 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Structured Analysis of Broadcast Badminton Videos
Dec 23, 2017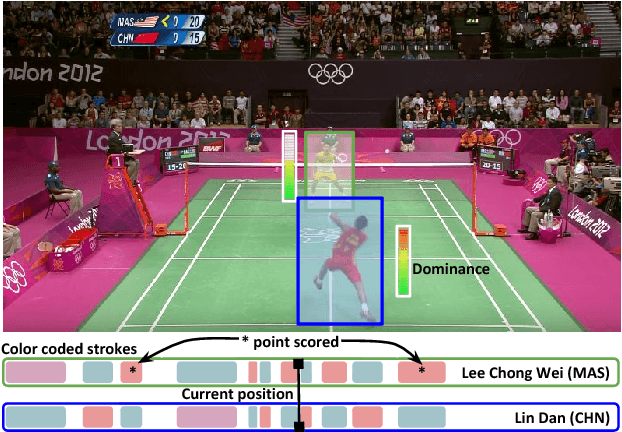
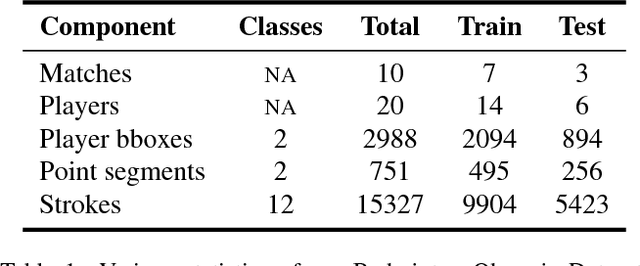

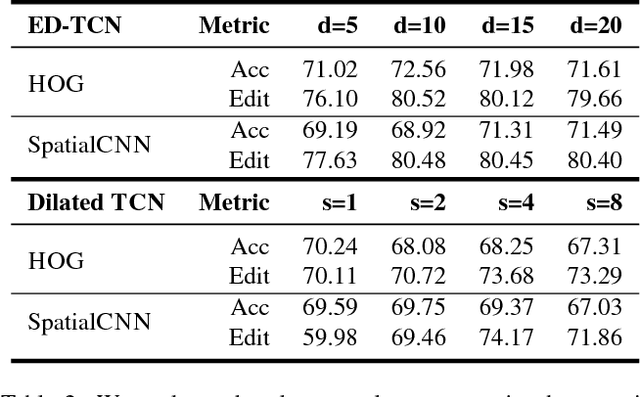
Sports video data is recorded for nearly every major tournament but remains archived and inaccessible to large scale data mining and analytics. It can only be viewed sequentially or manually tagged with higher-level labels which is time consuming and prone to errors. In this work, we propose an end-to-end framework for automatic attributes tagging and analysis of sport videos. We use commonly available broadcast videos of matches and, unlike previous approaches, does not rely on special camera setups or additional sensors. Our focus is on Badminton as the sport of interest. We propose a method to analyze a large corpus of badminton broadcast videos by segmenting the points played, tracking and recognizing the players in each point and annotating their respective badminton strokes. We evaluate the performance on 10 Olympic matches with 20 players and achieved 95.44% point segmentation accuracy, 97.38% player detection score (mAP@0.5), 97.98% player identification accuracy, and stroke segmentation edit scores of 80.48%. We further show that the automatically annotated videos alone could enable the gameplay analysis and inference by computing understandable metrics such as player's reaction time, speed, and footwork around the court, etc.
DimensionApp : android app to estimate object dimensions
Sep 24, 2016



In this project, we develop an android app that uses on computer vision techniques to estimate an object dimension present in field of view. The app while having compact size, is accurate upto +/- 5 mm and robust towards touch inputs. We use single-view metrology to compute accurate measurement. Unlike previous approaches, our technique does not rely on line detection and can be generalize to any object shape easily.
Trajectory Aligned Features For First Person Action Recognition
Apr 07, 2016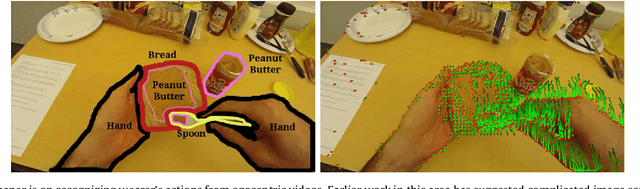


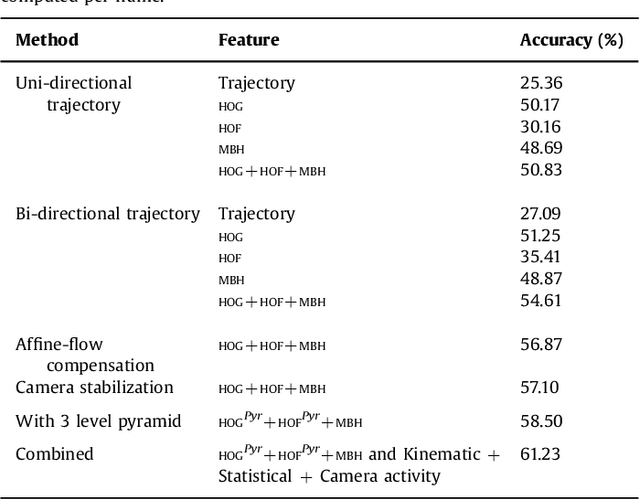
Egocentric videos are characterised by their ability to have the first person view. With the popularity of Google Glass and GoPro, use of egocentric videos is on the rise. Recognizing action of the wearer from egocentric videos is an important problem. Unstructured movement of the camera due to natural head motion of the wearer causes sharp changes in the visual field of the egocentric camera causing many standard third person action recognition techniques to perform poorly on such videos. Objects present in the scene and hand gestures of the wearer are the most important cues for first person action recognition but are difficult to segment and recognize in an egocentric video. We propose a novel representation of the first person actions derived from feature trajectories. The features are simple to compute using standard point tracking and does not assume segmentation of hand/objects or recognizing object or hand pose unlike in many previous approaches. We train a bag of words classifier with the proposed features and report a performance improvement of more than 11% on publicly available datasets. Although not designed for the particular case, we show that our technique can also recognize wearer's actions when hands or objects are not visible.