 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022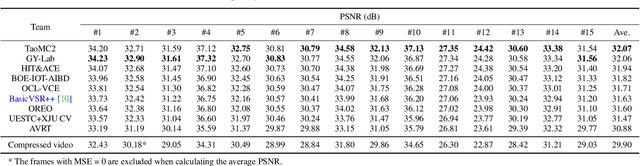
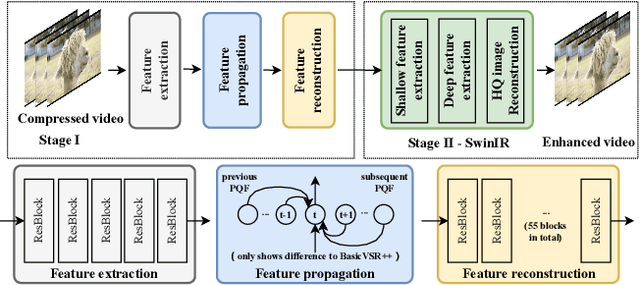
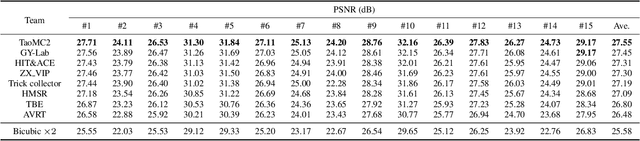

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Real-time FPGA Design for OMP Targeting 8K Image Reconstruction
Oct 10, 2021
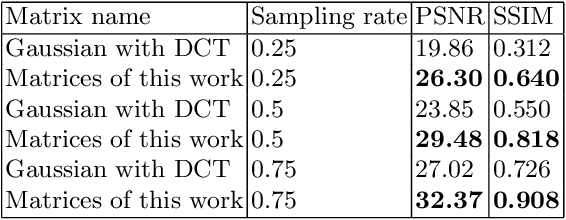

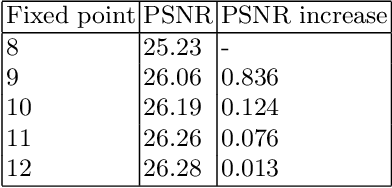
During the past decade, implementing reconstruction algorithms on hardware has been at the center of much attention in the field of real-time reconstruction in Compressed Sensing (CS). Orthogonal Matching Pursuit (OMP) is the most widely used reconstruction algorithm on hardware implementation because OMP obtains good quality reconstruction results under a proper time cost. OMP includes Dot Product (DP) and Least Square Problem (LSP). These two parts have numerous division calculations and considerable vector-based multiplications, which limit the implementation of real-time reconstruction on hardware. In the theory of CS, besides the reconstruction algorithm, the choice of sensing matrix affects the quality of reconstruction. It also influences the reconstruction efficiency by affecting the hardware architecture. Thus, designing a real-time hardware architecture of OMP needs to take three factors into consideration. The choice of sensing matrix, the implementation of DP and LSP. In this paper, a sensing matrix, which is sparsity and contains zero vectors mainly, is adopted to optimize the OMP reconstruction to break the bottleneck of reconstruction efficiency. Based on the features of the chosen matrix, the DP and LSP are implemented by simple shift, add and comparing procedures. This work is implemented on the Xilinx Virtex UltraScale+ FPGA device. To reconstruct a digital signal with 1024 length under 0.25 sampling rate, the proposal method costs 0.818us while the state-of-the-art costs 238$us. Thus, this work speedups the state-of-the-art method 290 times. This work costs 0.026s to reconstruct an 8K gray image, which achieves 30FPS real-time reconstruction.
Depth Completion via Inductive Fusion of Planar LIDAR and Monocular Camera
Sep 03, 2020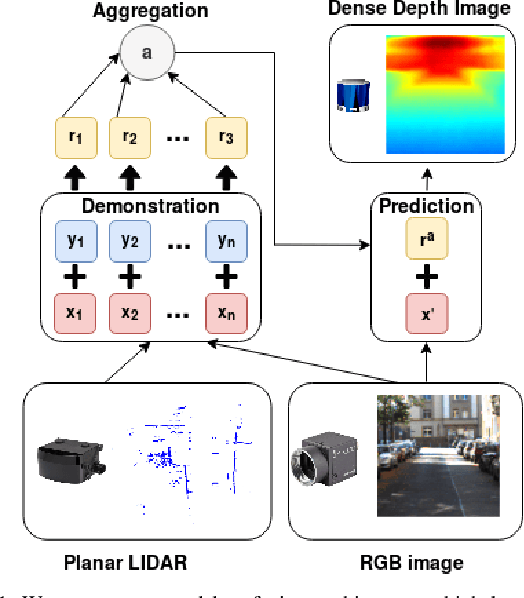
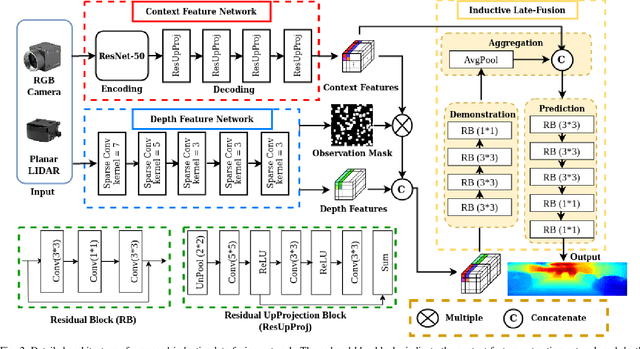
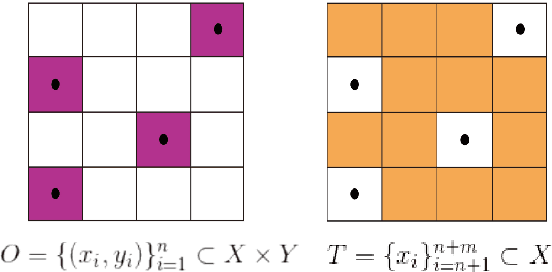
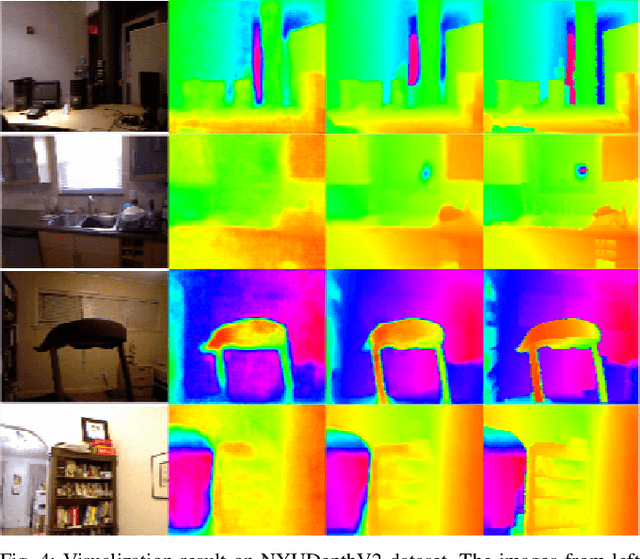
Modern high-definition LIDAR is expensive for commercial autonomous driving vehicles and small indoor robots. An affordable solution to this problem is fusion of planar LIDAR with RGB images to provide a similar level of perception capability. Even though state-of-the-art methods provide approaches to predict depth information from limited sensor input, they are usually a simple concatenation of sparse LIDAR features and dense RGB features through an end-to-end fusion architecture. In this paper, we introduce an inductive late-fusion block which better fuses different sensor modalities inspired by a probability model. The proposed demonstration and aggregation network propagates the mixed context and depth features to the prediction network and serves as a prior knowledge of the depth completion. This late-fusion block uses the dense context features to guide the depth prediction based on demonstrations by sparse depth features. In addition to evaluating the proposed method on benchmark depth completion datasets including NYUDepthV2 and KITTI, we also test the proposed method on a simulated planar LIDAR dataset. Our method shows promising results compared to previous approaches on both the benchmark datasets and simulated dataset with various 3D densities.
F2GAN: Fusing-and-Filling GAN for Few-shot Image Generation
Aug 06, 2020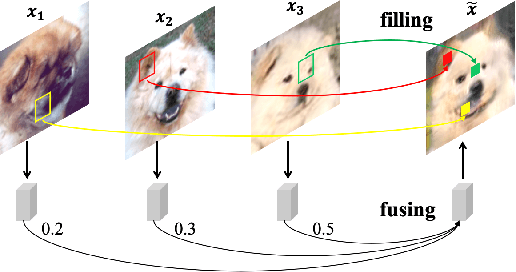
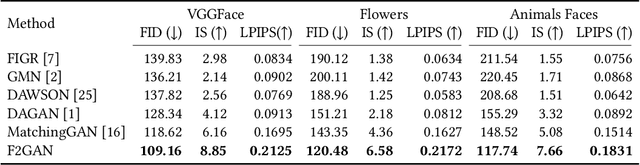
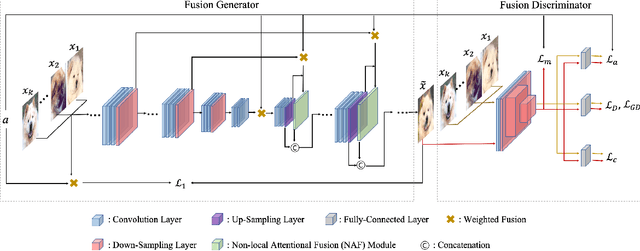
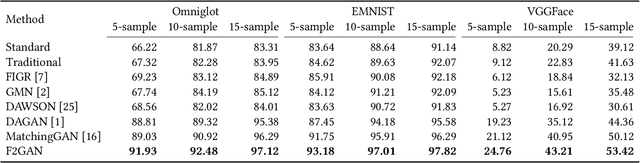
In order to generate images for a given category, existing deep generative models generally rely on abundant training images. However, extensive data acquisition is expensive and fast learning ability from limited data is necessarily required in real-world applications. Also, these existing methods are not well-suited for fast adaptation to a new category. Few-shot image generation, aiming to generate images from only a few images for a new category, has attracted some research interest. In this paper, we propose a Fusing-and-Filling Generative Adversarial Network (F2GAN) to generate realistic and diverse images for a new category with only a few images. In our F2GAN, a fusion generator is designed to fuse the high-level features of conditional images with random interpolation coefficients, and then fills in attended low-level details with non-local attention module to produce a new image. Moreover, our discriminator can ensure the diversity of generated images by a mode seeking loss and an interpolation regression loss. Extensive experiments on five datasets demonstrate the effectiveness of our proposed method for few-shot image generation.
Low-cost LIDAR based Vehicle Pose Estimation and Tracking
Oct 03, 2019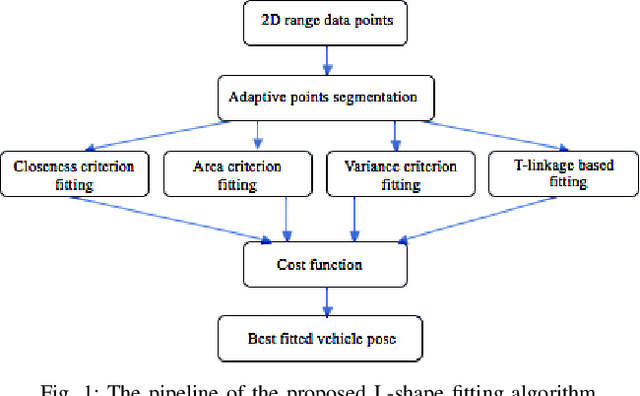
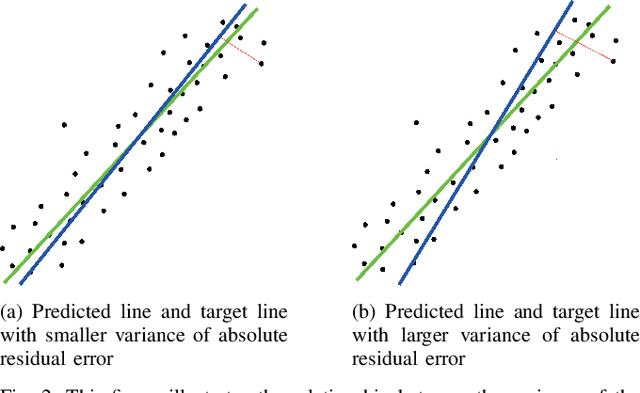
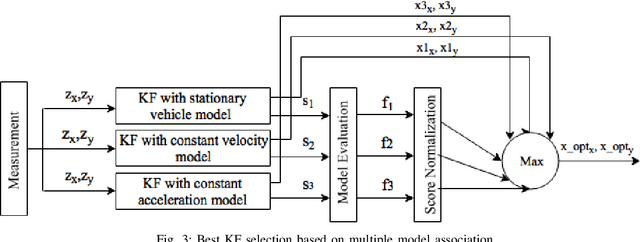
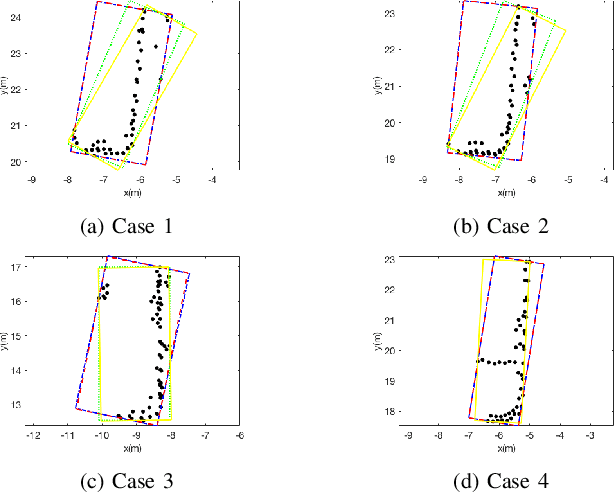
Detecting surrounding vehicles by low-cost LIDAR has been drawing enormous attention. In low-cost LIDAR, vehicles present a multi-layer L-Shape. Based on our previous optimization/criteria-based L-Shape fitting algorithm, we here propose a data-driven and model-based method for robust vehicle segmentation and tracking. The new method uses T-linkage RANSAC to take a limited amount of noisy data and performs a robust segmentation for a moving car against noise. Compared with our previous method, T-Linkage RANSAC is more tolerant of observation uncertainties, i.e., the number of sides of the target being observed, and gets rid of the L-Shape assumption. In addition, a vehicle tracking system with Multi-Model Association (MMA) is built upon the segmentation result, which provides smooth trajectories of tracked objects. A manually labeled dataset from low-cost multi-layer LIDARs for validation will also be released with the paper. Experiments on the dataset show that the new approach outperforms previous ones based on multiple criteria. The new algorithm can also run in real-time.
A data-driven method for syndrome type identification and classification in traditional Chinese medicine
Feb 24, 2016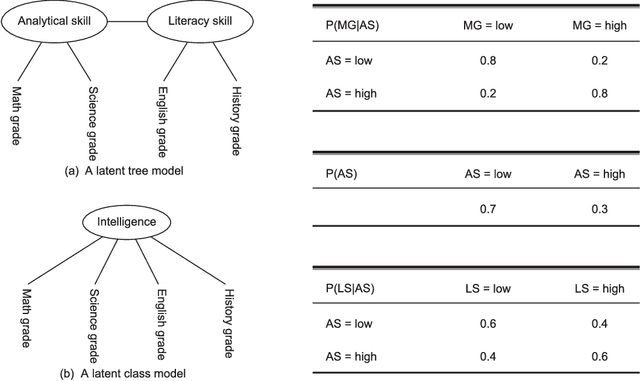


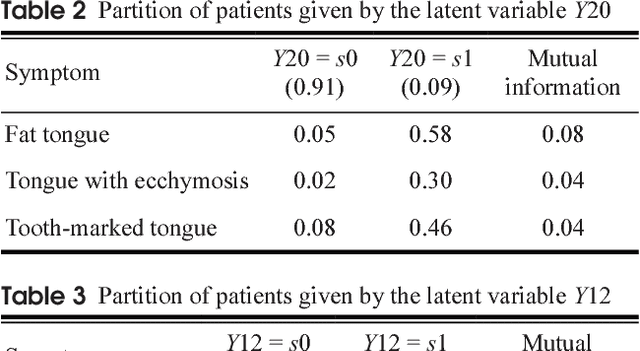
Objective: The efficacy of traditional Chinese medicine (TCM) treatments for Western medicine (WM) diseases relies heavily on the proper classification of patients into TCM syndrome types. We develop a data-driven method for solving the classification problem, where syndrome types are identified and quantified based on patterns detected in unlabeled symptom survey data. Method: Latent class analysis (LCA) has been applied in WM research to solve a similar problem, i.e., to identify subtypes of a patient population in the absence of a gold standard. A widely known weakness of LCA is that it makes an unrealistically strong independence assumption. We relax the assumption by first detecting symptom co-occurrence patterns from survey data and use those patterns instead of the symptoms as features for LCA. Results: The result of the investigation is a six-step method: Data collection, symptom co-occurrence pattern discovery, pattern interpretation, syndrome identification, syndrome type identification, and syndrome type classification. A software package called Lantern is developed to support the application of the method. The method is illustrated using a data set on Vascular Mild Cognitive Impairment (VMCI). Conclusions: A data-driven method for TCM syndrome identification and classification is presented. The method can be used to answer the following questions about a Western medicine disease: What TCM syndrome types are there among the patients with the disease? What is the prevalence of each syndrome type? What are the statistical characteristics of each syndrome type in terms of occurrence of symptoms? How can we determine the syndrome type(s) of a patient?
Identification and classification of TCM syndrome types among patients with vascular mild cognitive impairment using latent tree analysis
Feb 24, 2016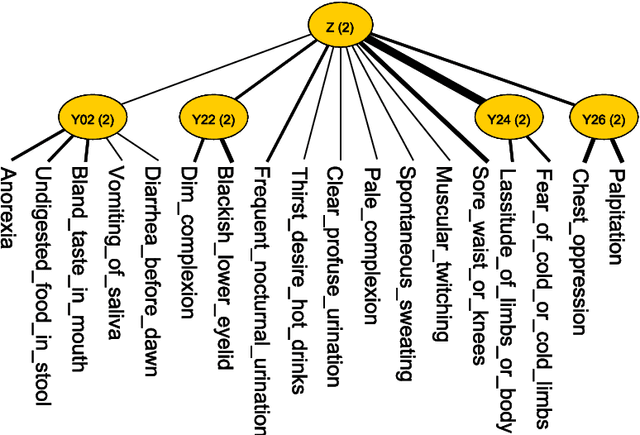
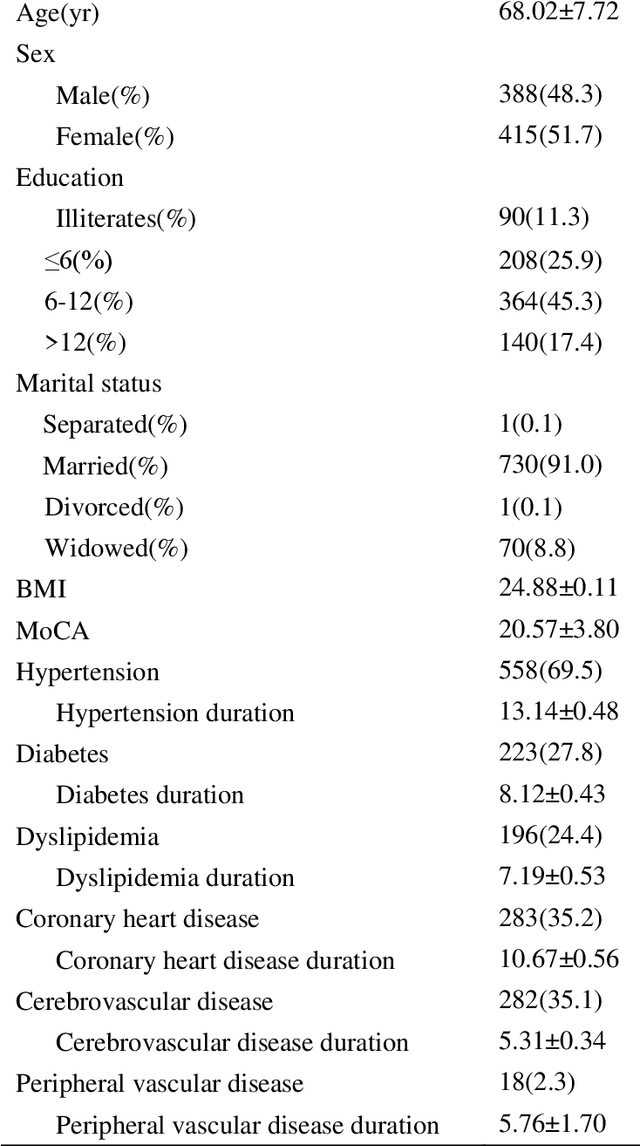
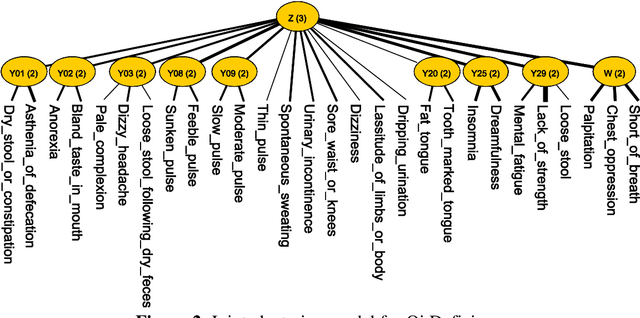
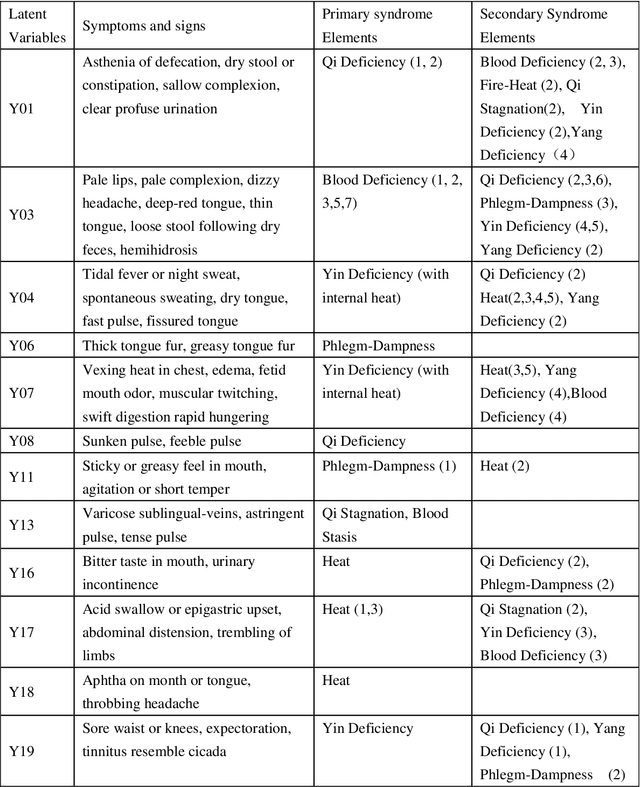
Objective: To treat patients with vascular mild cognitive impairment (VMCI) using TCM, it is necessary to classify the patients into TCM syndrome types and to apply different treatments to different types. We investigate how to properly carry out the classification using a novel data-driven method known as latent tree analysis. Method: A cross-sectional survey on VMCI was carried out in several regions in northern China from 2008 to 2011, which resulted in a data set that involves 803 patients and 93 symptoms. Latent tree analysis was performed on the data to reveal symptom co-occurrence patterns, and the patients were partitioned into clusters in multiple ways based on the patterns. The patient clusters were matched up with syndrome types, and population statistics of the clusters are used to quantify the syndrome types and to establish classification rules. Results: Eight syndrome types are identified: Qi Deficiency, Qi Stagnation, Blood Deficiency, Blood Stasis, Phlegm-Dampness, Fire-Heat, Yang Deficiency, and Yin Deficiency. The prevalence and symptom occurrence characteristics of each syndrome type are determined. Quantitative classification rules are established for determining whether a patient belongs to each of the syndrome types. Conclusions: A solution for the TCM syndrome classification problem associated with VMCI is established based on the latent tree analysis of unlabeled symptom survey data. The results can be used as a reference in clinic practice to improve the quality of syndrome differentiation and to reduce diagnosis variances across physicians. They can also be used for patient selection in research projects aimed at finding biomarkers for the syndrome types and in randomized control trials aimed at determining the efficacy of TCM treatments of VMCI.