 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022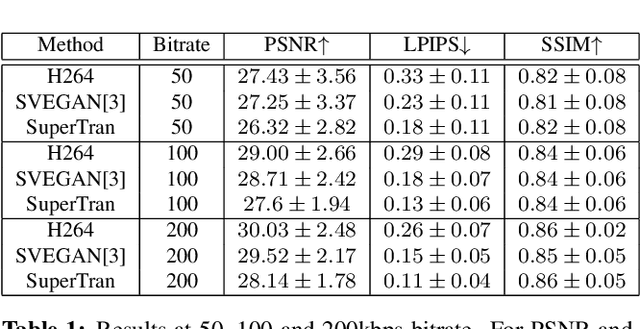


This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
Jun 06, 2019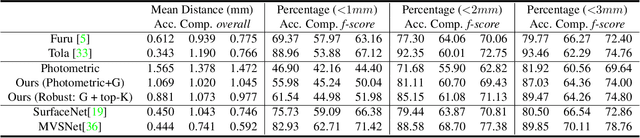
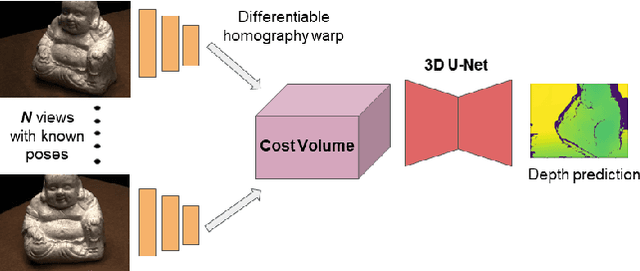
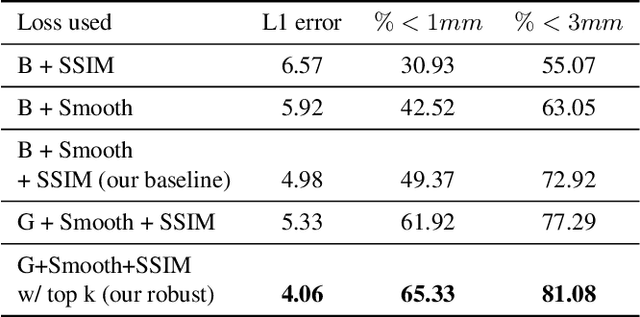
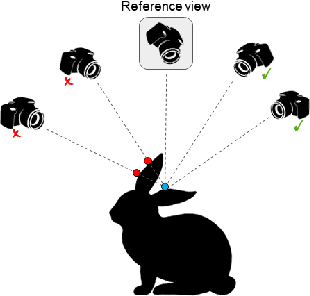
We present a learning based approach for multi-view stereopsis (MVS). While current deep MVS methods achieve impressive results, they crucially rely on ground-truth 3D training data, and acquisition of such precise 3D geometry for supervision is a major hurdle. Our framework instead leverages photometric consistency between multiple views as supervisory signal for learning depth prediction in a wide baseline MVS setup. However, naively applying photo consistency constraints is undesirable due to occlusion and lighting changes across views. To overcome this, we propose a robust loss formulation that: a) enforces first order consistency and b) for each point, selectively enforces consistency with some views, thus implicitly handling occlusions. We demonstrate our ability to learn MVS without 3D supervision using a real dataset, and show that each component of our proposed robust loss results in a significant improvement. We qualitatively observe that our reconstructions are often more complete than the acquired ground truth, further showing the merits of this approach. Lastly, our learned model generalizes to novel settings, and our approach allows adaptation of existing CNNs to datasets without ground-truth 3D by unsupervised finetuning. Project webpage: https://tejaskhot.github.io/unsup_mvs
PCN: Point Completion Network
Aug 05, 2018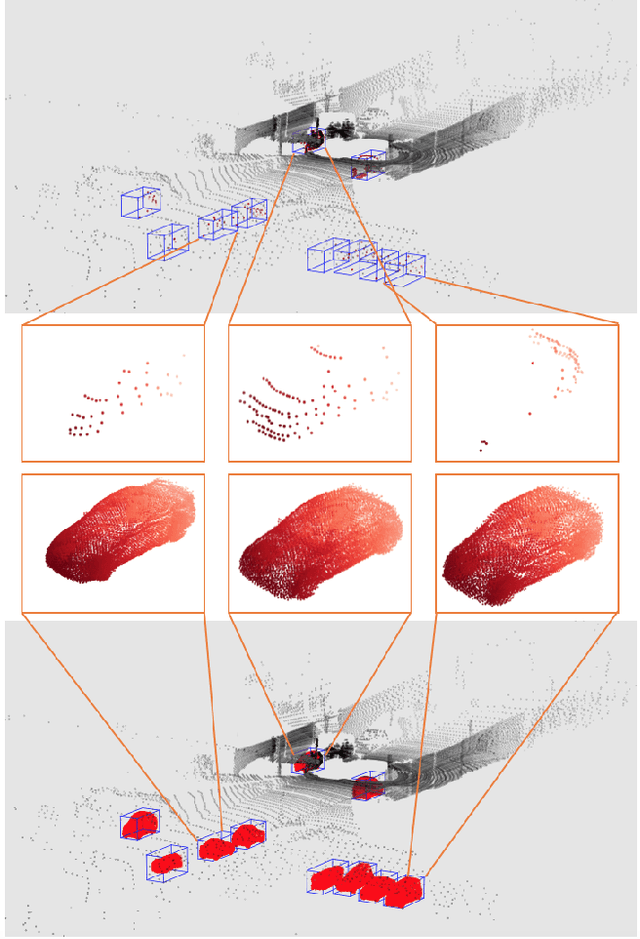

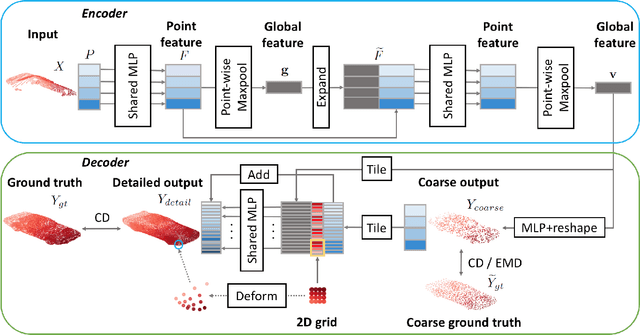

Shape completion, the problem of estimating the complete geometry of objects from partial observations, lies at the core of many vision and robotics applications. In this work, we propose Point Completion Network (PCN), a novel learning-based approach for shape completion. Unlike existing shape completion methods, PCN directly operates on raw point clouds without any structural assumption (e.g. symmetry) or annotation (e.g. semantic class) about the underlying shape. It features a decoder design that enables the generation of fine-grained completions while maintaining a small number of parameters. Our experiments show that PCN produces dense, complete point clouds with realistic structures in the missing regions on inputs with various levels of incompleteness and noise, including cars from LiDAR scans in the KITTI dataset.
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
May 15, 2017
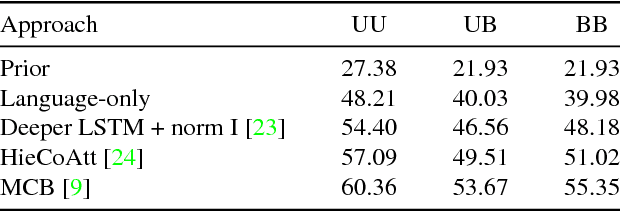

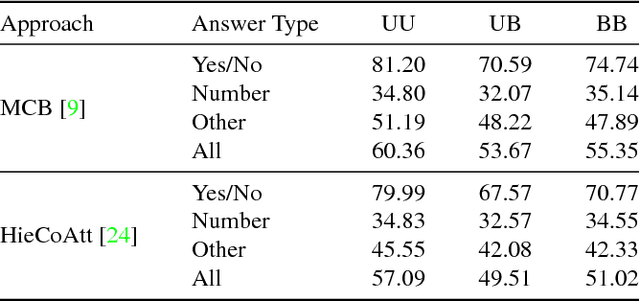
Problems at the intersection of vision and language are of significant importance both as challenging research questions and for the rich set of applications they enable. However, inherent structure in our world and bias in our language tend to be a simpler signal for learning than visual modalities, resulting in models that ignore visual information, leading to an inflated sense of their capability. We propose to counter these language priors for the task of Visual Question Answering (VQA) and make vision (the V in VQA) matter! Specifically, we balance the popular VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset is publicly available at www.visualqa.org as part of the 2nd iteration of the Visual Question Answering Dataset and Challenge (VQA v2.0). We further benchmark a number of state-of-art VQA models on our balanced dataset. All models perform significantly worse on our balanced dataset, suggesting that these models have indeed learned to exploit language priors. This finding provides the first concrete empirical evidence for what seems to be a qualitative sense among practitioners. Finally, our data collection protocol for identifying complementary images enables us to develop a novel interpretable model, which in addition to providing an answer to the given (image, question) pair, also provides a counter-example based explanation. Specifically, it identifies an image that is similar to the original image, but it believes has a different answer to the same question. This can help in building trust for machines among their users.