 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Holodeck-style Simulation Game
Sep 12, 2023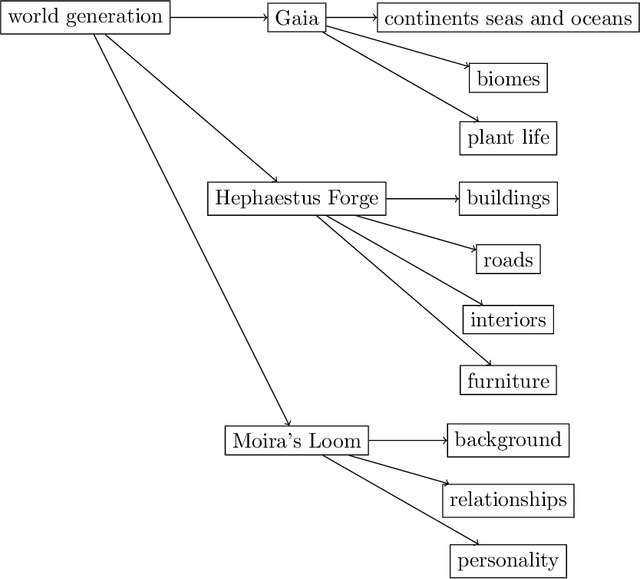


We introduce Infinitia, a simulation game system that uses generative image and language models at play time to reshape all aspects of the setting and NPCs based on a short description from the player, in a way similar to how settings are created on the fictional Holodeck. Building off the ideas of the Generative Agents paper, our system introduces gameplay elements, such as infinite generated fantasy worlds, controllability of NPC behavior, humorous dialogue, cost & time efficiency, collaboration between players and elements of non-determinism among in-game events. Infinitia is implemented in the Unity engine with a server-client architecture, facilitating the addition of exciting features by community developers in the future. Furthermore, it uses a multiplayer framework to allow humans to be present and interact in the simulation. The simulation will be available in open-alpha shortly at https://infinitia.ai/ and we are looking forward to building upon it with the community.
Gluing Neural Networks Symbolically Through Hyperdimensional Computing
May 31, 2022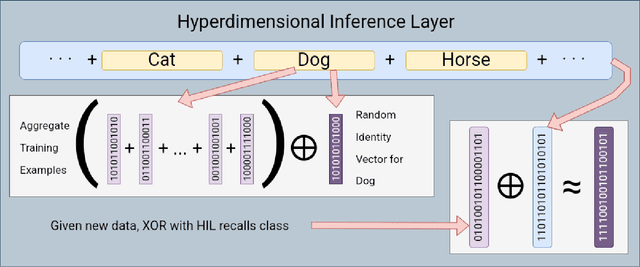
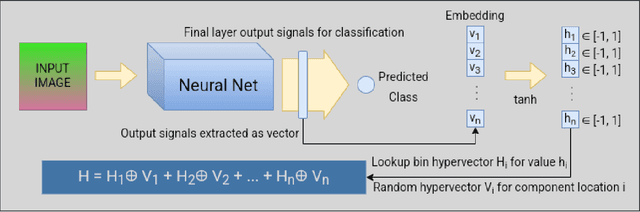
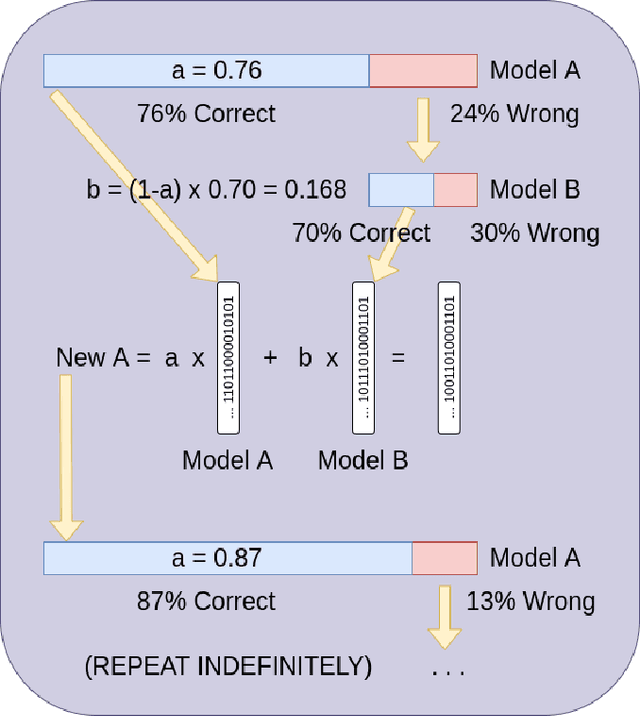
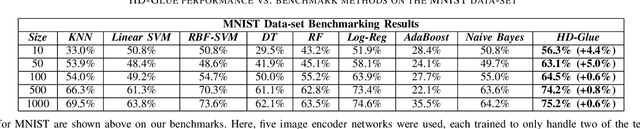
Hyperdimensional Computing affords simple, yet powerful operations to create long Hyperdimensional Vectors (hypervectors) that can efficiently encode information, be used for learning, and are dynamic enough to be modified on the fly. In this paper, we explore the notion of using binary hypervectors to directly encode the final, classifying output signals of neural networks in order to fuse differing networks together at the symbolic level. This allows multiple neural networks to work together to solve a problem, with little additional overhead. Output signals just before classification are encoded as hypervectors and bundled together through consensus summation to train a classification hypervector. This process can be performed iteratively and even on single neural networks by instead making a consensus of multiple classification hypervectors. We find that this outperforms the state of the art, or is on a par with it, while using very little overhead, as hypervector operations are extremely fast and efficient in comparison to the neural networks. This consensus process can learn online and even grow or lose models in real time. Hypervectors act as memories that can be stored, and even further bundled together over time, affording life long learning capabilities. Additionally, this consensus structure inherits the benefits of Hyperdimensional Computing, without sacrificing the performance of modern Machine Learning. This technique can be extrapolated to virtually any neural model, and requires little modification to employ - one simply requires recording the output signals of networks when presented with a testing example.
Representing Sets as Summed Semantic Vectors
Sep 24, 2018
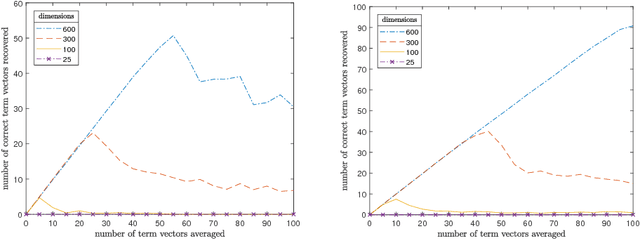
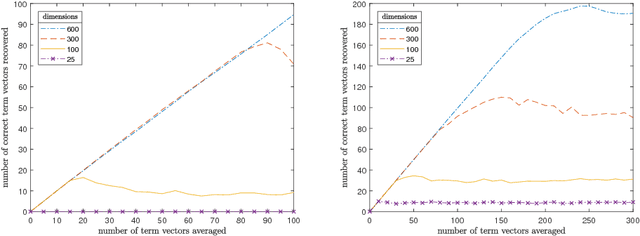
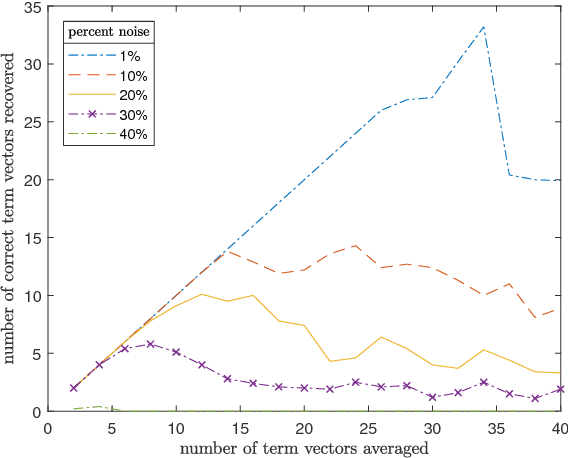
Representing meaning in the form of high dimensional vectors is a common and powerful tool in biologically inspired architectures. While the meaning of a set of concepts can be summarized by taking a (possibly weighted) sum of their associated vectors, this has generally been treated as a one-way operation. In this paper we show how a technique built to aid sparse vector decomposition allows in many cases the exact recovery of the inputs and weights to such a sum, allowing a single vector to represent an entire set of vectors from a dictionary. We characterize the number of vectors that can be recovered under various conditions, and explore several ways such a tool can be used for vector-based reasoning.
A Computational Theory for Life-Long Learning of Semantics
Jul 22, 2018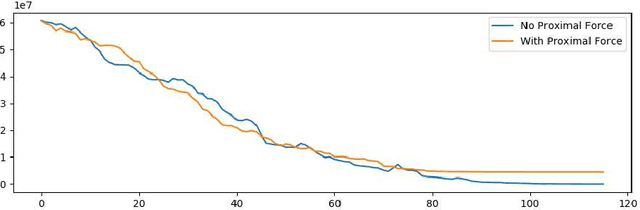
Semantic vectors are learned from data to express semantic relationships between elements of information, for the purpose of solving and informing downstream tasks. Other models exist that learn to map and classify supervised data. However, the two worlds of learning rarely interact to inform one another dynamically, whether across types of data or levels of semantics, in order to form a unified model. We explore the research problem of learning these vectors and propose a framework for learning the semantics of knowledge incrementally and online, across multiple mediums of data, via binary vectors. We discuss the aspects of this framework to spur future research on this approach and problem.
Deductive and Analogical Reasoning on a Semantically Embedded Knowledge Graph
Jul 11, 2017
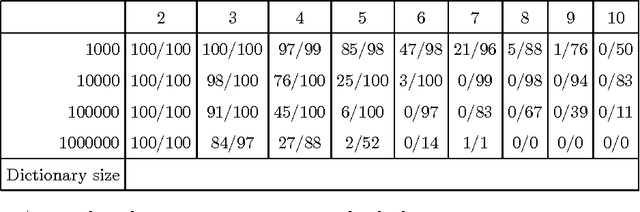
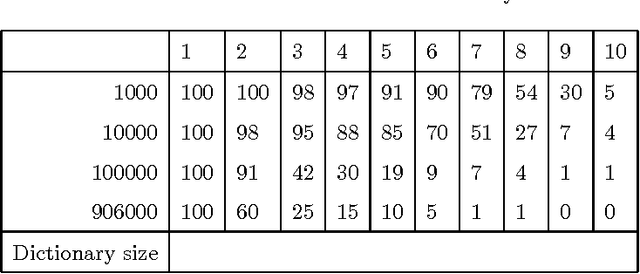
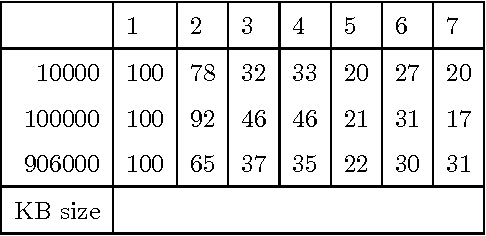
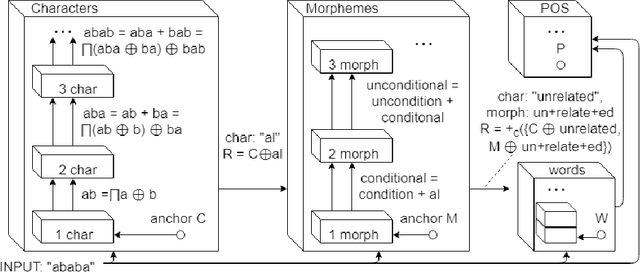
Representing knowledge as high-dimensional vectors in a continuous semantic vector space can help overcome the brittleness and incompleteness of traditional knowledge bases. We present a method for performing deductive reasoning directly in such a vector space, combining analogy, association, and deduction in a straightforward way at each step in a chain of reasoning, drawing on knowledge from diverse sources and ontologies.
Graphcut Texture Synthesis for Single-Image Superresolution
Jun 21, 2017Texture synthesis has proven successful at imitating a wide variety of textures. Adding additional constraints (in the form of a low-resolution version of the texture to be synthesized) makes it possible to use texture synthesis methods for texture superresolution.
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
May 15, 2017
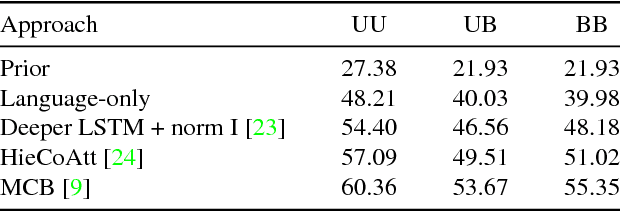

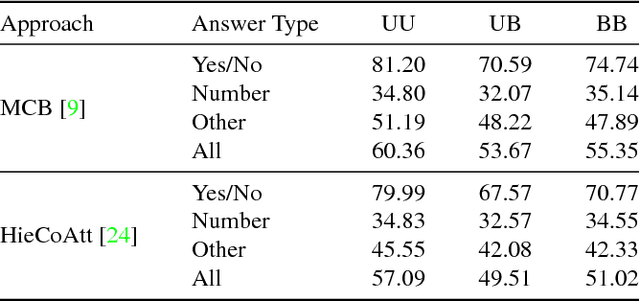
Problems at the intersection of vision and language are of significant importance both as challenging research questions and for the rich set of applications they enable. However, inherent structure in our world and bias in our language tend to be a simpler signal for learning than visual modalities, resulting in models that ignore visual information, leading to an inflated sense of their capability. We propose to counter these language priors for the task of Visual Question Answering (VQA) and make vision (the V in VQA) matter! Specifically, we balance the popular VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset is publicly available at www.visualqa.org as part of the 2nd iteration of the Visual Question Answering Dataset and Challenge (VQA v2.0). We further benchmark a number of state-of-art VQA models on our balanced dataset. All models perform significantly worse on our balanced dataset, suggesting that these models have indeed learned to exploit language priors. This finding provides the first concrete empirical evidence for what seems to be a qualitative sense among practitioners. Finally, our data collection protocol for identifying complementary images enables us to develop a novel interpretable model, which in addition to providing an answer to the given (image, question) pair, also provides a counter-example based explanation. Specifically, it identifies an image that is similar to the original image, but it believes has a different answer to the same question. This can help in building trust for machines among their users.
Using a Distributional Semantic Vector Space with a Knowledge Base for Reasoning in Uncertain Conditions
Jun 13, 2016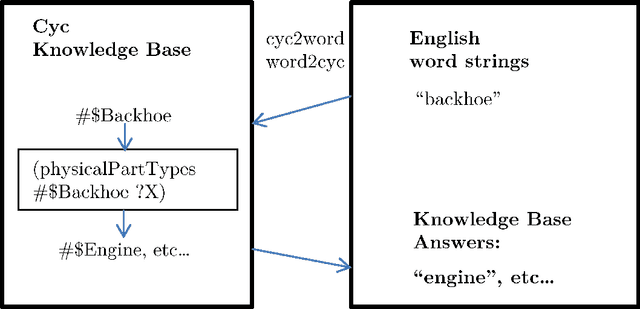

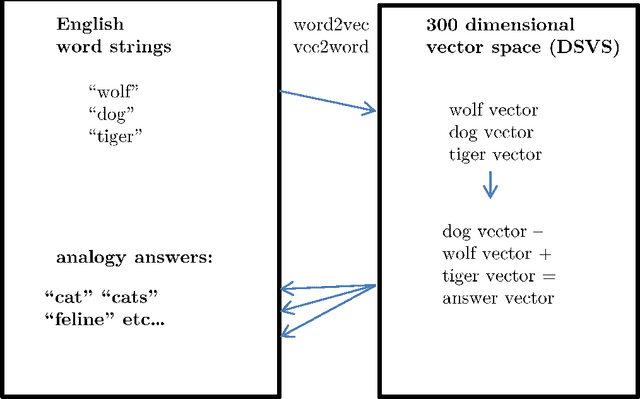
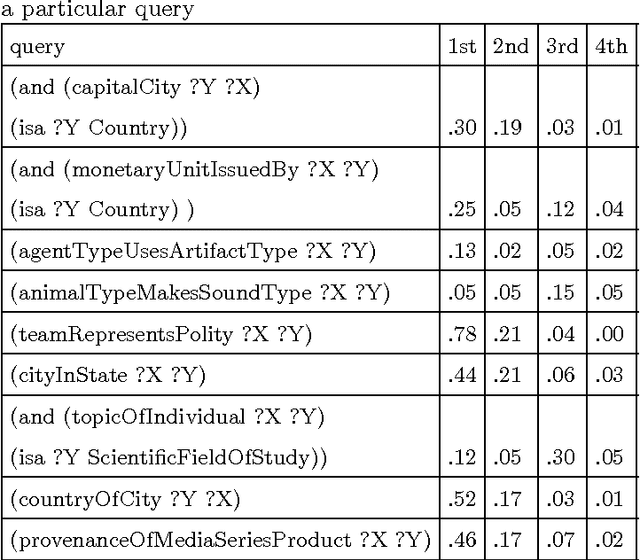
The inherent inflexibility and incompleteness of commonsense knowledge bases (KB) has limited their usefulness. We describe a system called Displacer for performing KB queries extended with the analogical capabilities of the word2vec distributional semantic vector space (DSVS). This allows the system to answer queries with information which was not contained in the original KB in any form. By performing analogous queries on semantically related terms and mapping their answers back into the context of the original query using displacement vectors, we are able to give approximate answers to many questions which, if posed to the KB alone, would return no results. We also show how the hand-curated knowledge in a KB can be used to increase the accuracy of a DSVS in solving analogy problems. In these ways, a KB and a DSVS can make up for each other's weaknesses.
Yin and Yang: Balancing and Answering Binary Visual Questions
Apr 19, 2016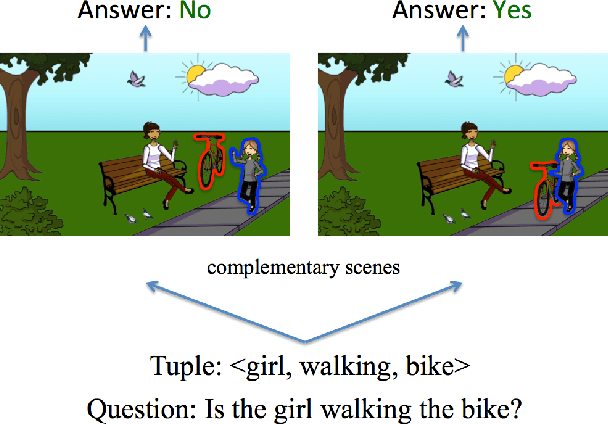
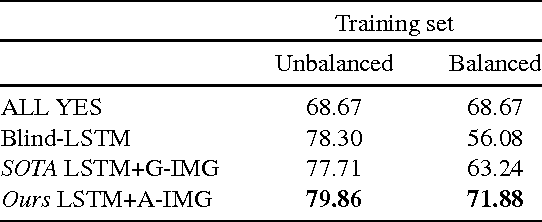
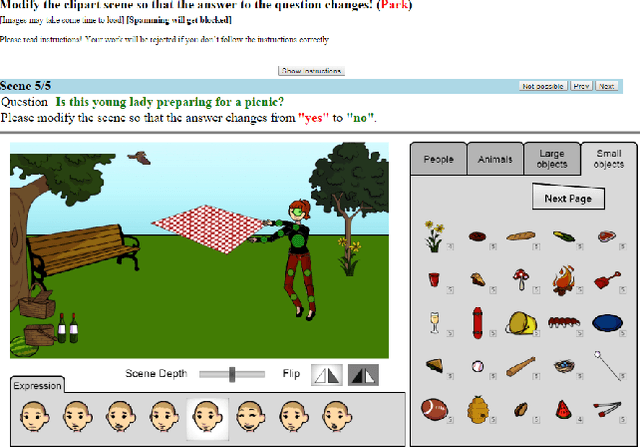
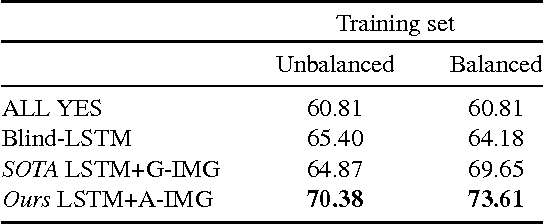
The complex compositional structure of language makes problems at the intersection of vision and language challenging. But language also provides a strong prior that can result in good superficial performance, without the underlying models truly understanding the visual content. This can hinder progress in pushing state of art in the computer vision aspects of multi-modal AI. In this paper, we address binary Visual Question Answering (VQA) on abstract scenes. We formulate this problem as visual verification of concepts inquired in the questions. Specifically, we convert the question to a tuple that concisely summarizes the visual concept to be detected in the image. If the concept can be found in the image, the answer to the question is "yes", and otherwise "no". Abstract scenes play two roles (1) They allow us to focus on the high-level semantics of the VQA task as opposed to the low-level recognition problems, and perhaps more importantly, (2) They provide us the modality to balance the dataset such that language priors are controlled, and the role of vision is essential. In particular, we collect fine-grained pairs of scenes for every question, such that the answer to the question is "yes" for one scene, and "no" for the other for the exact same question. Indeed, language priors alone do not perform better than chance on our balanced dataset. Moreover, our proposed approach matches the performance of a state-of-the-art VQA approach on the unbalanced dataset, and outperforms it on the balanced dataset.