 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Importance Sampling Based Methods for Mitigating the Effect of Class Imbalance
Paper and Code
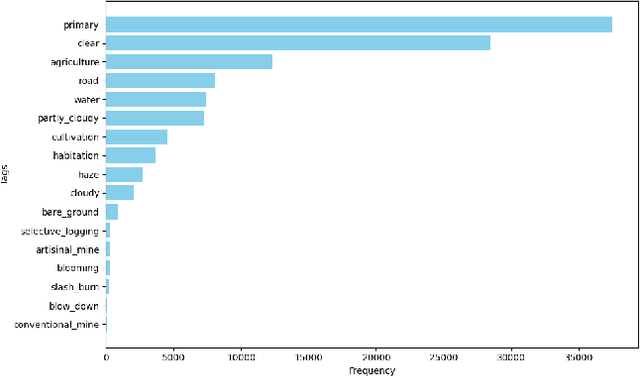
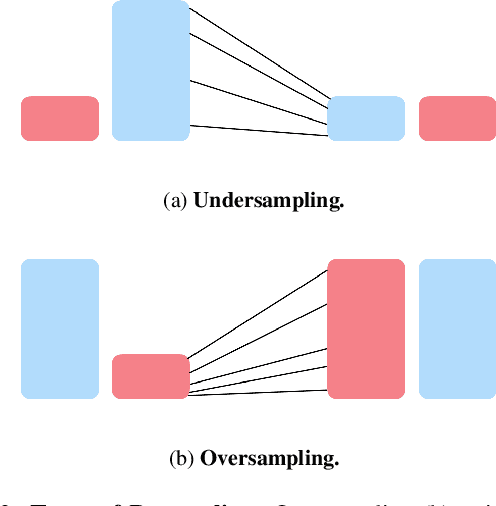
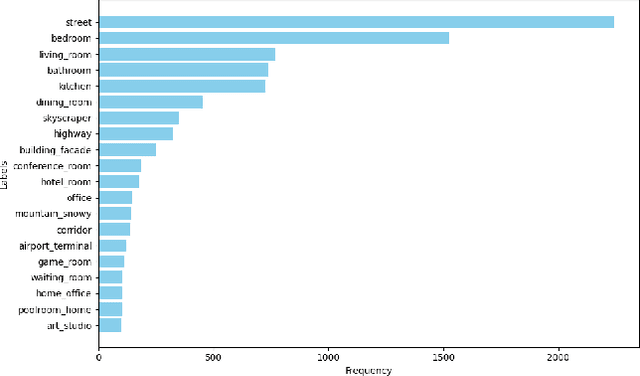

Most state-of-the-art computer vision models heavily depend on data. However, many datasets exhibit extreme class imbalance which has been shown to negatively impact model performance. Among the training-time and data-generation solutions that have been explored, one subset that leverages existing data is importance sampling. A good deal of this work focuses primarily on the CIFAR-10 and CIFAR-100 datasets which fail to be representative of the scale, composition, and complexity of current state-of-the-art datasets. In this work, we explore and compare three techniques that derive from importance sampling: loss reweighting, undersampling, and oversampling. Specifically, we compare the effect of these techniques on the performance of two encoders on an impactful satellite imagery dataset, Planet's Amazon Rainforest dataset, in preparation for another work. Furthermore, we perform supplemental experimentation on a scene classification dataset, ADE20K, to test on a contrasting domain and clarify our results. Across both types of encoders, we find that up-weighting the loss for and undersampling has a negigible effect on the performance on underrepresented classes. Additionally, our results suggest oversampling generally improves performance for the same underrepresented classes. Interestingly, our findings also indicate that there may exist some redundancy in data in the Planet dataset. Our work aims to provide a foundation for further work on the Planet dataset and similar domain-specific datasets. We open-source our code at https://github.com/RichardZhu123/514-class-imbalance for future work on other satellite imagery datasets as well.