 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
SOWing Information: Cultivating Contextual Coherence with MLLMs in Image Generation
Nov 28, 2024



Originating from the diffusion phenomenon in physics, which describes the random movement and collisions of particles, diffusion generative models simulate a random walk in the data space along the denoising trajectory. This allows information to diffuse across regions, yielding harmonious outcomes. However, the chaotic and disordered nature of information diffusion in diffusion models often results in undesired interference between image regions, causing degraded detail preservation and contextual inconsistency. In this work, we address these challenges by reframing disordered diffusion as a powerful tool for text-vision-to-image generation (TV2I) tasks, achieving pixel-level condition fidelity while maintaining visual and semantic coherence throughout the image. We first introduce Cyclic One-Way Diffusion (COW), which provides an efficient unidirectional diffusion framework for precise information transfer while minimizing disruptive interference. Building on COW, we further propose Selective One-Way Diffusion (SOW), which utilizes Multimodal Large Language Models (MLLMs) to clarify the semantic and spatial relationships within the image. Based on these insights, SOW combines attention mechanisms to dynamically regulate the direction and intensity of diffusion according to contextual relationships. Extensive experiments demonstrate the untapped potential of controlled information diffusion, offering a path to more adaptive and versatile generative models in a learning-free manner.
CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation
Jun 15, 2024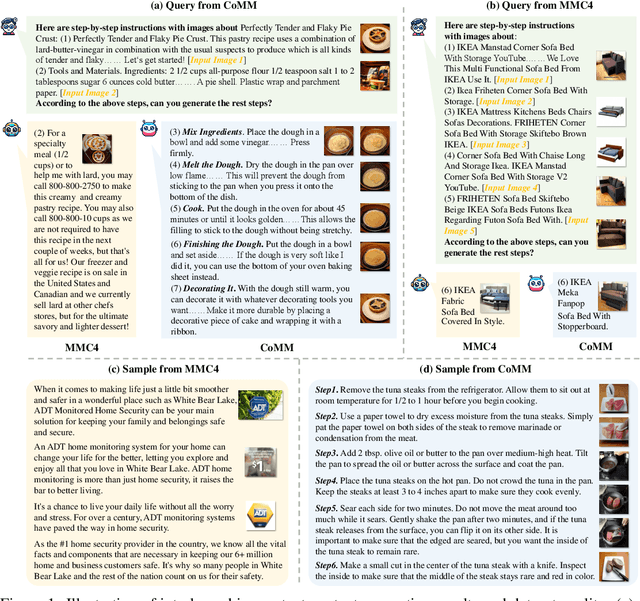



Interleaved image-text generation has emerged as a crucial multimodal task, aiming at creating sequences of interleaved visual and textual content given a query. Despite notable advancements in recent multimodal large language models (MLLMs), generating integrated image-text sequences that exhibit narrative coherence and entity and style consistency remains challenging due to poor training data quality. To address this gap, we introduce CoMM, a high-quality Coherent interleaved image-text MultiModal dataset designed to enhance the coherence, consistency, and alignment of generated multimodal content. Initially, CoMM harnesses raw data from diverse sources, focusing on instructional content and visual storytelling, establishing a foundation for coherent and consistent content. To further refine the data quality, we devise a multi-perspective filter strategy that leverages advanced pre-trained models to ensure the development of sentences, consistency of inserted images, and semantic alignment between them. Various quality evaluation metrics are designed to prove the high quality of the filtered dataset. Meanwhile, extensive few-shot experiments on various downstream tasks demonstrate CoMM's effectiveness in significantly enhancing the in-context learning capabilities of MLLMs. Moreover, we propose four new tasks to evaluate MLLMs' interleaved generation abilities, supported by a comprehensive evaluation framework. We believe CoMM opens a new avenue for advanced MLLMs with superior multimodal in-context learning and understanding ability.
D$^3$: Scaling Up Deepfake Detection by Learning from Discrepancy
Apr 06, 2024



The boom of Generative AI brings opportunities entangled with risks and concerns. In this work, we seek a step toward a universal deepfake detection system with better generalization and robustness, to accommodate the responsible deployment of diverse image generative models. We do so by first scaling up the existing detection task setup from the one-generator to multiple-generators in training, during which we disclose two challenges presented in prior methodological designs. Specifically, we reveal that the current methods tailored for training on one specific generator either struggle to learn comprehensive artifacts from multiple generators or tend to sacrifice their ability to identify fake images from seen generators (i.e., In-Domain performance) to exchange the generalization for unseen generators (i.e., Out-Of-Domain performance). To tackle the above challenges, we propose our Discrepancy Deepfake Detector (D$^3$) framework, whose core idea is to learn the universal artifacts from multiple generators by introducing a parallel network branch that takes a distorted image as extra discrepancy signal to supplement its original counterpart. Extensive scaled-up experiments on the merged UFD and GenImage datasets with six detection models demonstrate the effectiveness of our framework, achieving a 5.3% accuracy improvement in the OOD testing compared to the current SOTA methods while maintaining the ID performance.
Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation
Jun 17, 2023



Text-to-Image (T2I) generation with diffusion models allows users to control the semantic content in the synthesized images given text conditions. As a further step toward a more customized image creation application, we introduce a new multi-modality generation setting that synthesizes images based on not only the semantic-level textual input but also on the pixel-level visual conditions. Existing literature first converts the given visual information to semantic-level representation by connecting it to languages, and then incorporates it into the original denoising process. Seemingly intuitive, such methodological design loses the pixel values during the semantic transition, thus failing to fulfill the task scenario where the preservation of low-level vision is desired (e.g., ID of a given face image). To this end, we propose Cyclic One-Way Diffusion (COW), a training-free framework for creating customized images with respect to semantic text and pixel-visual conditioning. Notably, we observe that sub-regions of an image impose mutual interference, just like physical diffusion, to achieve ultimate harmony along the denoising trajectory. Thus we propose to repetitively utilize the given visual condition in a cyclic way, by planting the visual condition as a high-concentration "seed" at the initialization step of the denoising process, and "diffuse" it into a harmonious picture by controlling a one-way information flow from the visual condition. We repeat the destroy-and-construct process multiple times to gradually but steadily impose the internal diffusion process within the image. Experiments on the challenging one-shot face and text-conditioned image synthesis task demonstrate our superiority in terms of speed, image quality, and conditional fidelity compared to learning-based text-vision conditional methods. Project page is available at: https://bigaandsmallq.github.io/COW/