 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCS: Clinical Consensus Selection for Radiology Report Generation
May 28, 2026Radiology report generation (RRG) is commonly formulated as a single-path generation task, where a multimodal large language model (MLLM) produces one decoded report as the final output. While recent progress has largely been driven by scaling training data, model capacity, and retrieval mechanisms, improving report quality at inference time remains underexplored. In this work, we observe that fixed radiology MLLMs often generate clinically stronger reports elsewhere in their candidate pool than the one selected by default decoding, suggesting that inference-time decision making remains an overlooked bottleneck. To address this, we propose Clinical Consensus Selection (CCS), a decoder-agnostic inference-time selection framework that samples multiple candidate reports and selects the one with the highest clinical consensus across the rollout pool. CCS unifies text-based utilities with a radiology-adapted utility computed by an image--report-trained multimodal embedder, which measures candidate agreement beyond surface-level textual similarity. Across three datasets and multiple radiology MLLMs, CCS consistently improves inference-time performance over single-path decoding and generic Best-of-N baselines, with particularly clear gains on clinical metrics. Further analysis shows that image-grounded utility forms a selection axis distinct from textual consensus and that substantial headroom remains for improving RRG at inference time.
Can We Edit LLMs for Long-Tail Biomedical Knowledge?
Apr 14, 2025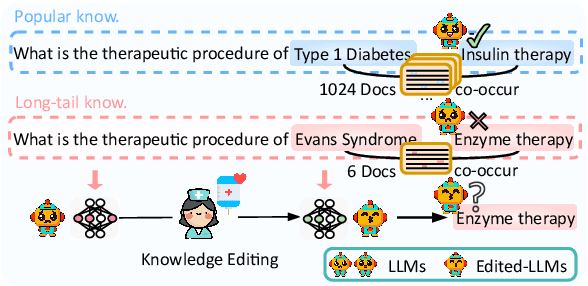
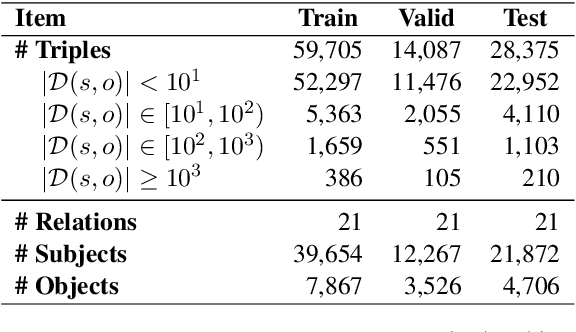
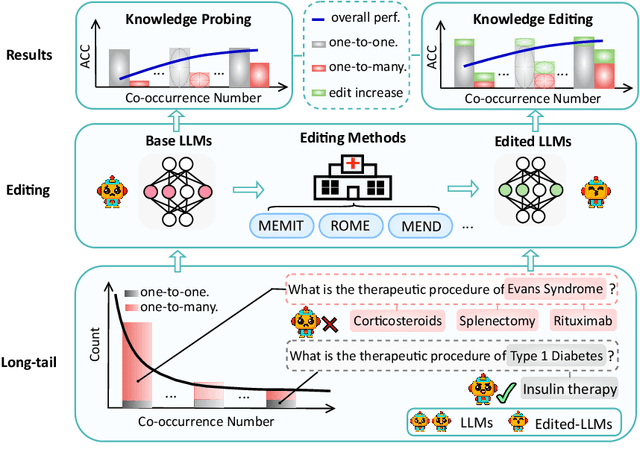
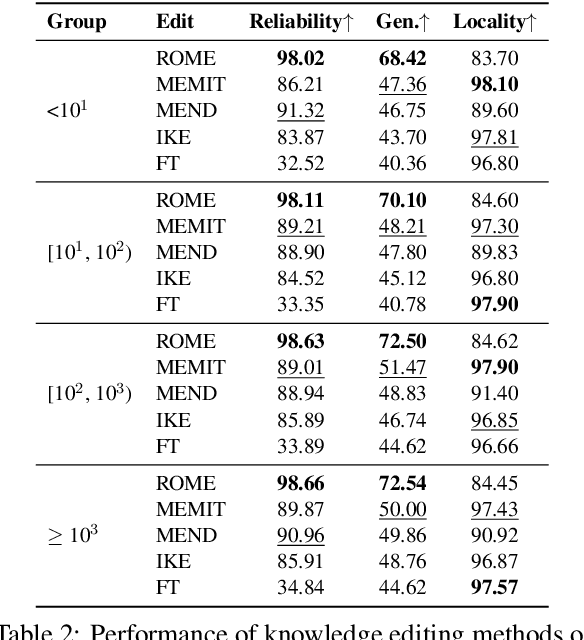
Knowledge editing has emerged as an effective approach for updating large language models (LLMs) by modifying their internal knowledge. However, their application to the biomedical domain faces unique challenges due to the long-tailed distribution of biomedical knowledge, where rare and infrequent information is prevalent. In this paper, we conduct the first comprehensive study to investigate the effectiveness of knowledge editing methods for editing long-tail biomedical knowledge. Our results indicate that, while existing editing methods can enhance LLMs' performance on long-tail biomedical knowledge, their performance on long-tail knowledge remains inferior to that on high-frequency popular knowledge, even after editing. Our further analysis reveals that long-tail biomedical knowledge contains a significant amount of one-to-many knowledge, where one subject and relation link to multiple objects. This high prevalence of one-to-many knowledge limits the effectiveness of knowledge editing in improving LLMs' understanding of long-tail biomedical knowledge, highlighting the need for tailored strategies to bridge this performance gap.
Gla-AI4BioMed at RRG24: Visual Instruction-tuned Adaptation for Radiology Report Generation
Dec 06, 2024
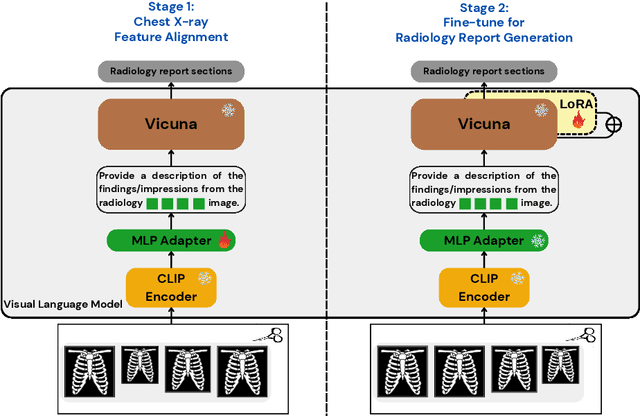

We introduce a radiology-focused visual language model designed to generate radiology reports from chest X-rays. Building on previous findings that large language models (LLMs) can acquire multimodal capabilities when aligned with pretrained vision encoders, we demonstrate similar potential with chest X-ray images. This integration enhances the ability of model to understand and describe chest X-ray images. Our model combines an image encoder with a fine-tuned LLM based on the Vicuna-7B architecture, enabling it to generate different sections of a radiology report with notable accuracy. The training process involves a two-stage approach: (i) initial alignment of chest X-ray features with the LLM (ii) followed by fine-tuning for radiology report generation.
Libra: Leveraging Temporal Images for Biomedical Radiology Analysis
Nov 28, 2024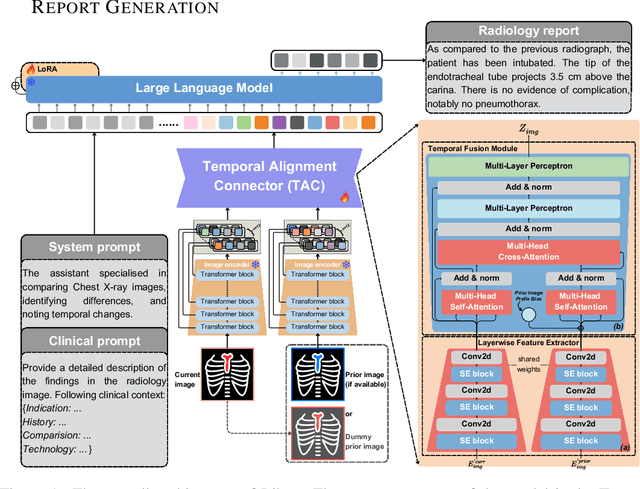



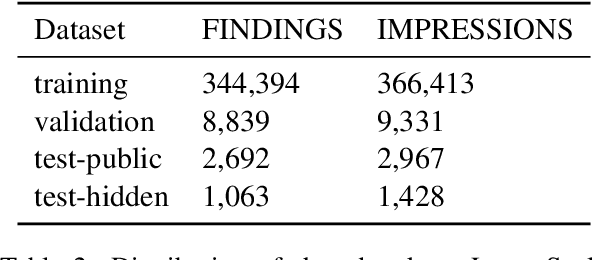
Radiology report generation (RRG) is a challenging task, as it requires a thorough understanding of medical images, integration of multiple temporal inputs, and accurate report generation. Effective interpretation of medical images, such as chest X-rays (CXRs), demands sophisticated visual-language reasoning to map visual findings to structured reports. Recent studies have shown that multimodal large language models (MLLMs) can acquire multimodal capabilities by aligning with pre-trained vision encoders. However, current approaches predominantly focus on single-image analysis or utilise rule-based symbolic processing to handle multiple images, thereby overlooking the essential temporal information derived from comparing current images with prior ones. To overcome this critical limitation, we introduce Libra, a temporal-aware MLLM tailored for CXR report generation using temporal images. Libra integrates a radiology-specific image encoder with a MLLM and utilises a novel Temporal Alignment Connector to capture and synthesise temporal information of images across different time points with unprecedented precision. Extensive experiments show that Libra achieves new state-of-the-art performance among the same parameter scale MLLMs for RRG tasks on the MIMIC-CXR. Specifically, Libra improves the RadCliQ metric by 12.9% and makes substantial gains across all lexical metrics compared to previous models.
Zero-shot and Few-shot Generation Strategies for Artificial Clinical Records
Mar 14, 2024


The challenge of accessing historical patient data for clinical research, while adhering to privacy regulations, is a significant obstacle in medical science. An innovative approach to circumvent this issue involves utilising synthetic medical records that mirror real patient data without compromising individual privacy. The creation of these synthetic datasets, particularly without using actual patient data to train Large Language Models (LLMs), presents a novel solution as gaining access to sensitive patient information to train models is also a challenge. This study assesses the capability of the Llama 2 LLM to create synthetic medical records that accurately reflect real patient information, employing zero-shot and few-shot prompting strategies for comparison against fine-tuned methodologies that do require sensitive patient data during training. We focus on generating synthetic narratives for the History of Present Illness section, utilising data from the MIMIC-IV dataset for comparison. In this work introduce a novel prompting technique that leverages a chain-of-thought approach, enhancing the model's ability to generate more accurate and contextually relevant medical narratives without prior fine-tuning. Our findings suggest that this chain-of-thought prompted approach allows the zero-shot model to achieve results on par with those of fine-tuned models, based on Rouge metrics evaluation.