 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Delta Parameters as JPEG Images: Data-Free Delta Compression with Discrete Cosine Transform
Paper and Code
Mar 09, 2025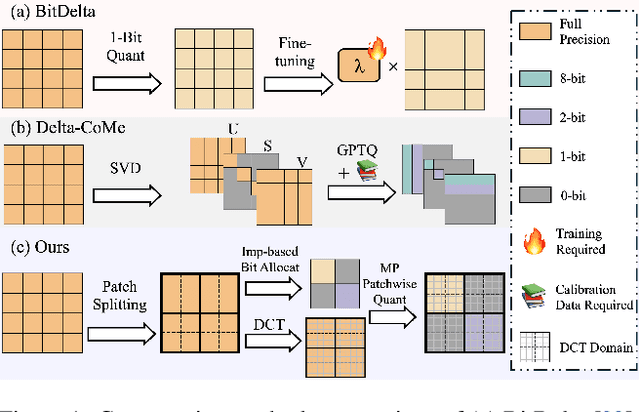



With transformer-based models and the pretrain-finetune paradigm becoming mainstream, the high storage and deployment costs of individual finetuned models on multiple tasks pose critical challenges. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights). However, existing methods usually face problems including data accessibility and training requirements. To tackle this issue, we introduce Delta-DCT, the first data-free delta compression method inspired by classic JPEG image compression, leveraging the Discrete Cosine Transform (DCT). We first (a) group delta parameters within a layer into patches. Then we (b) assess the importance of each patch and allocate them with different quantization bit-widths. Afterwards, we (c) convert these patches to the DCT domain and conduct quantization to each patch based on the allocated bit-width. The proposed Delta-DCT does not require any training or data calibration, while achieving performance comparable to or even surpassing original finetuned models under 1-bit equivalent delta compression ratios on different kinds of models including: (1) recently-released LLMs of different sizes from 7B to 13B, (2) relatively smaller language models including RoBERTa and T5 models, (3) variants of vision transformer models, and (4) multi-modal BEiT-3 models.