 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Compact and Robust DNNs via Compression-aware Sharpness Minimization
Jan 28, 2026Sharpness-Aware Minimization (SAM) has recently emerged as an effective technique for improving DNN robustness to input variations. However, its interplay with the compactness requirements of on-device DNN deployments remains less explored. Simply pruning a SAM-trained model can undermine robustness, since flatness in the continuous parameter space does not necessarily translate to robustness under the discrete structural changes induced by pruning. Conversely, applying SAM after pruning may be fundamentally constrained by architectural limitations imposed by an early, robustness-agnostic pruning pattern. To address this gap, we propose Compression-aware ShArpness Minimization (C-SAM), a framework that shifts sharpness-aware learning from parameter perturbations to mask perturbations. By explicitly perturbing pruning masks during training, C-SAM promotes a flatter loss landscape with respect to model structure, enabling the discovery of pruning patterns that simultaneously optimize model compactness and robustness to input variations. Extensive experiments on CelebA-HQ, Flowers-102, and CIFAR-10-C across ResNet-18, GoogLeNet, and MobileNet-V2 show that C-SAM consistently achieves higher certified robustness than strong baselines, with improvements of up to 42%, while maintaining task accuracy comparable to the corresponding unpruned models.
Automating Conflict-Aware ACL Configurations with Natural Language Intents
Aug 25, 2025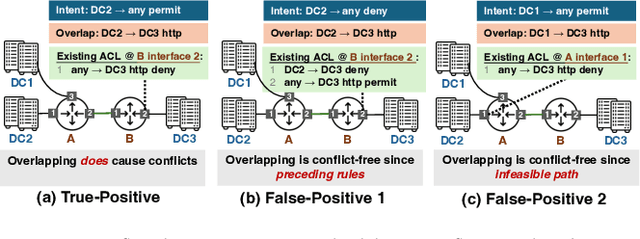

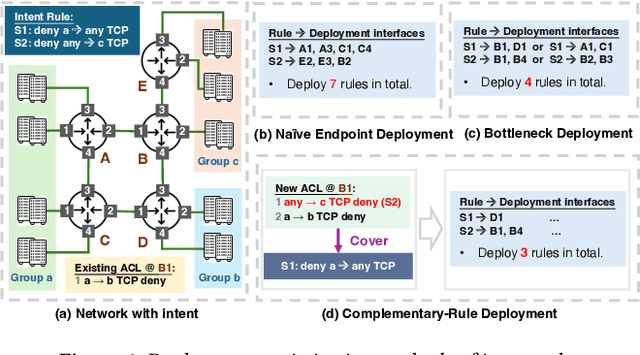
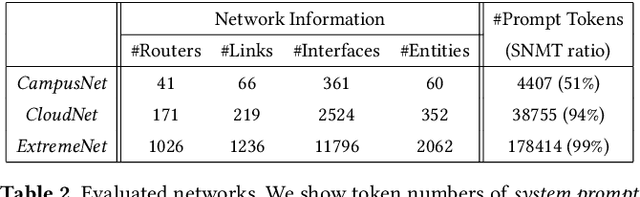
ACL configuration is essential for managing network flow reachability, yet its complexity grows significantly with topologies and pre-existing rules. To carry out ACL configuration, the operator needs to (1) understand the new configuration policies or intents and translate them into concrete ACL rules, (2) check and resolve any conflicts between the new and existing rules, and (3) deploy them across the network. Existing systems rely heavily on manual efforts for these tasks, especially for the first two, which are tedious, error-prone, and impractical to scale. We propose Xumi to tackle this problem. Leveraging LLMs with domain knowledge of the target network, Xumi automatically and accurately translates the natural language intents into complete ACL rules to reduce operators' manual efforts. Xumi then detects all potential conflicts between new and existing rules and generates resolved intents for deployment with operators' guidance, and finally identifies the best deployment plan that minimizes the rule additions while satisfying all intents. Evaluation shows that Xumi accelerates the entire configuration pipeline by over 10x compared to current practices, addresses O(100) conflicting ACLs and reduces rule additions by ~40% in modern cloud network.
ObjVariantEnsemble: Advancing Point Cloud LLM Evaluation in Challenging Scenes with Subtly Distinguished Objects
Dec 19, 2024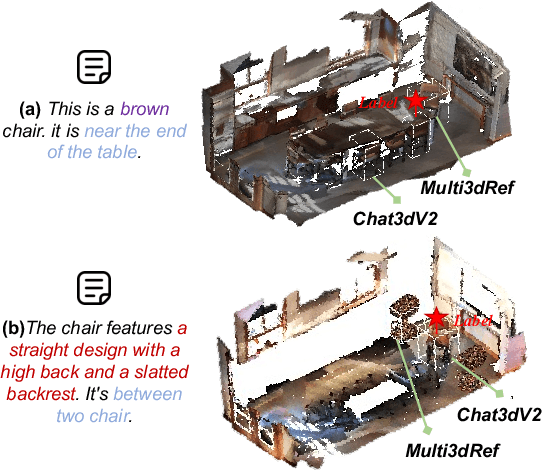
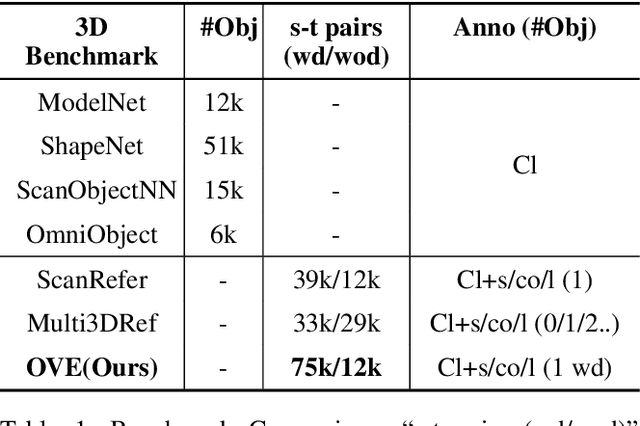
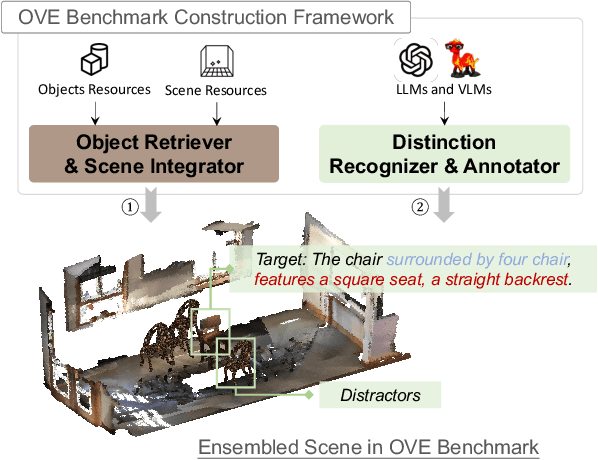
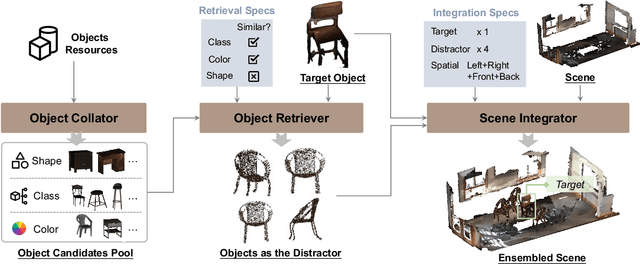
3D scene understanding is an important task, and there has been a recent surge of research interest in aligning 3D representations of point clouds with text to empower embodied AI. However, due to the lack of comprehensive 3D benchmarks, the capabilities of 3D models in real-world scenes, particularly those that are challenging with subtly distinguished objects, remain insufficiently investigated. To facilitate a more thorough evaluation of 3D models' capabilities, we propose a scheme, ObjVariantEnsemble, to systematically introduce more scenes with specified object classes, colors, shapes, quantities, and spatial relationships to meet model evaluation needs. More importantly, we intentionally construct scenes with similar objects to a certain degree and design an LLM-VLM-cooperated annotator to capture key distinctions as annotations. The resultant benchmark can better challenge 3D models, reveal their shortcomings in understanding, and potentially aid in the further development of 3D models.
Divide-and-Conquer Attack: Harnessing the Power of LLM to Bypass the Censorship of Text-to-Image Generation Model
Dec 12, 2023Text-to-image generative models offer many innovative services but also raise ethical concerns due to their potential to generate unethical images. Most publicly available text-to-image models employ safety filters to prevent unintended generation intents. In this work, we introduce the Divide-and-Conquer Attack to circumvent the safety filters of state-of-the-art text-to-image models. Our attack leverages LLMs as agents for text transformation, creating adversarial prompts from sensitive ones. We have developed effective helper prompts that enable LLMs to break down sensitive drawing prompts into multiple harmless descriptions, allowing them to bypass safety filters while still generating sensitive images. This means that the latent harmful meaning only becomes apparent when all individual elements are drawn together. Our evaluation demonstrates that our attack successfully circumvents the closed-box safety filter of SOTA DALLE-3 integrated natively into ChatGPT to generate unethical images. This approach, which essentially uses LLM-generated adversarial prompts against GPT-4-assisted DALLE-3, is akin to using one's own spear to breach their shield. It could have more severe security implications than previous manual crafting or iterative model querying methods, and we hope it stimulates more attention towards similar efforts. Our code and data are available at: https://github.com/researchcode001/Divide-and-Conquer-Attack
ECGadv: Generating Adversarial Electrocardiogram to Misguide Arrhythmia Classification System
Jan 12, 2019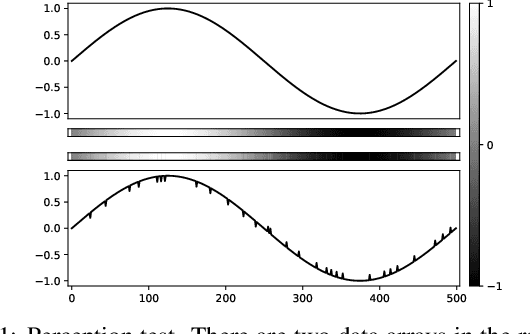
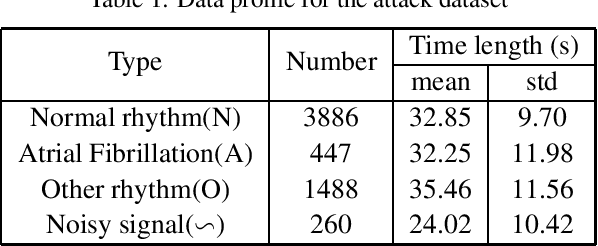
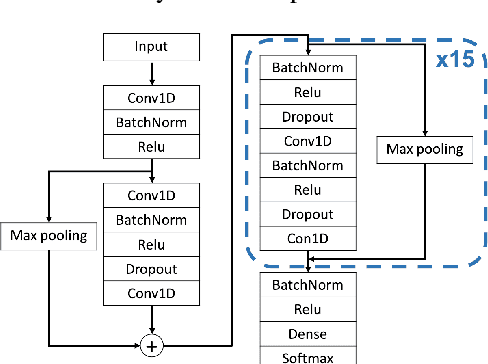

Deep neural networks (DNNs)-powered Electrocardiogram (ECG) diagnosis systems emerge recently, and are expected to take over tedious examinations by cardiologists. However, their vulnerability to adversarial attacks still lack of comprehensive investigation. ECG recordings differ from images in the visualization, dynamic property and accessibility, thus, the existing image-targeted attack may not directly applicable. To fill this gap, this paper proposes ECGadv to explore the feasibility of adversarial attacks on arrhythmia classification system. We identify the main issues under two different deployment models(i.e., cloud-based and local-based) and propose effective attack schemes respectively. Our results demonstrate the blind spots of DNN-powered diagnosis system under adversarial attacks, which facilitates future researches on countermeasures.