 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
ObjVariantEnsemble: Advancing Point Cloud LLM Evaluation in Challenging Scenes with Subtly Distinguished Objects
Dec 19, 2024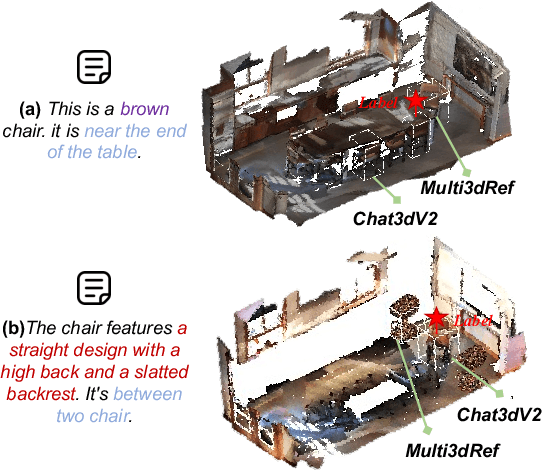
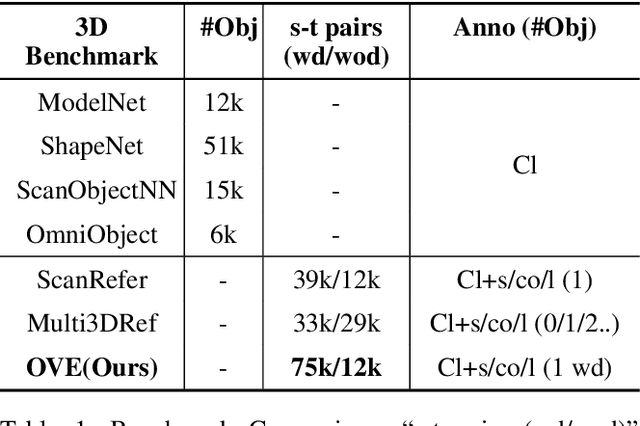
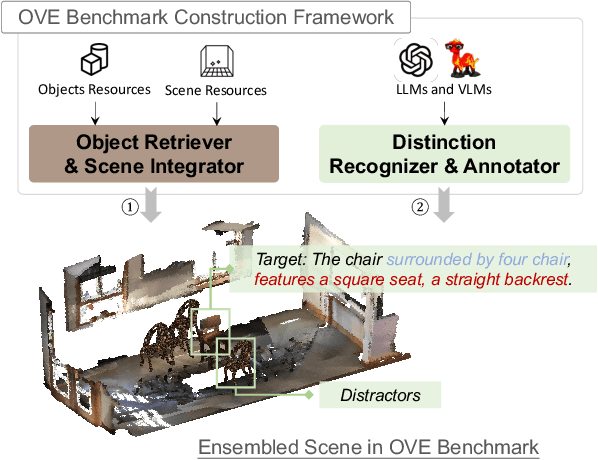
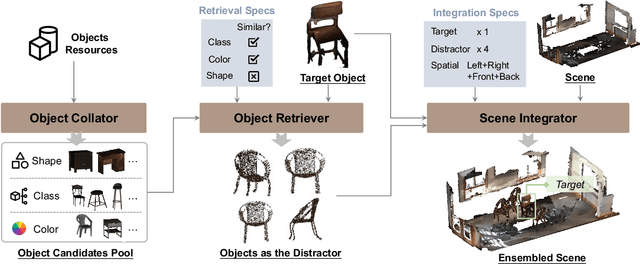
3D scene understanding is an important task, and there has been a recent surge of research interest in aligning 3D representations of point clouds with text to empower embodied AI. However, due to the lack of comprehensive 3D benchmarks, the capabilities of 3D models in real-world scenes, particularly those that are challenging with subtly distinguished objects, remain insufficiently investigated. To facilitate a more thorough evaluation of 3D models' capabilities, we propose a scheme, ObjVariantEnsemble, to systematically introduce more scenes with specified object classes, colors, shapes, quantities, and spatial relationships to meet model evaluation needs. More importantly, we intentionally construct scenes with similar objects to a certain degree and design an LLM-VLM-cooperated annotator to capture key distinctions as annotations. The resultant benchmark can better challenge 3D models, reveal their shortcomings in understanding, and potentially aid in the further development of 3D models.