 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Performance Benchmarking on Mobile Platforms: A Thorough Evaluation
Paper and Code
Oct 04, 2024
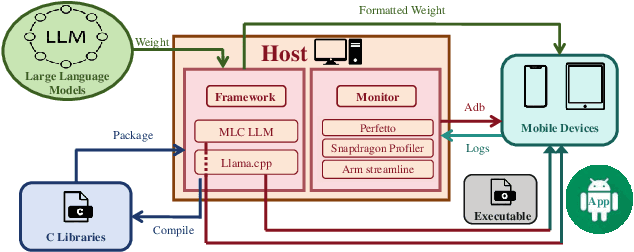
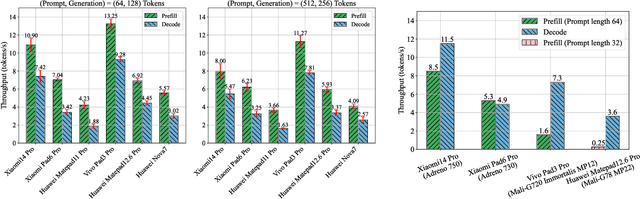
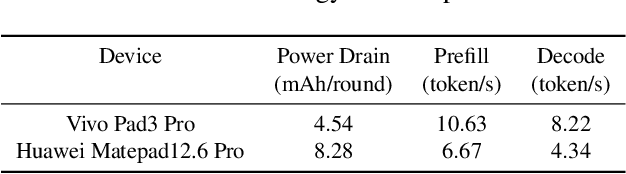
As large language models (LLMs) increasingly integrate into every aspect of our work and daily lives, there are growing concerns about user privacy, which push the trend toward local deployment of these models. There are a number of lightweight LLMs (e.g., Gemini Nano, LLAMA2 7B) that can run locally on smartphones, providing users with greater control over their personal data. As a rapidly emerging application, we are concerned about their performance on commercial-off-the-shelf mobile devices. To fully understand the current landscape of LLM deployment on mobile platforms, we conduct a comprehensive measurement study on mobile devices. We evaluate both metrics that affect user experience, including token throughput, latency, and battery consumption, as well as factors critical to developers, such as resource utilization, DVFS strategies, and inference engines. In addition, we provide a detailed analysis of how these hardware capabilities and system dynamics affect on-device LLM performance, which may help developers identify and address bottlenecks for mobile LLM applications. We also provide comprehensive comparisons across the mobile system-on-chips (SoCs) from major vendors, highlighting their performance differences in handling LLM workloads. We hope that this study can provide insights for both the development of on-device LLMs and the design for future mobile system architecture.