 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing guidance for missing data in diffusion-based sequential recommendation
Jan 22, 2026Contemporary sequential recommendation methods are becoming more complex, shifting from classification to a diffusion-guided generative paradigm. However, the quality of guidance in the form of user information is often compromised by missing data in the observed sequences, leading to suboptimal generation quality. Existing methods address this by removing locally similar items, but overlook ``critical turning points'' in user interest, which are crucial for accurately predicting subsequent user intent. To address this, we propose a novel Counterfactual Attention Regulation Diffusion model (CARD), which focuses on amplifying the signal from key interest-turning-point items while concurrently identifying and suppressing noise within the user sequence. CARD consists of (1) a Dual-side Thompson Sampling method to identify sequences undergoing significant interest shift, and (2) a counterfactual attention mechanism for these sequences to quantify the importance of each item. In this manner, CARD provides the diffusion model with a high-quality guidance signal composed of dynamically re-weighted interaction vectors to enable effective generation. Experiments show our method works well on real-world data without being computationally expensive. Our code is available at https://github.com/yanqilong3321/CARD.
TACO: Tackling Over-correction in Federated Learning with Tailored Adaptive Correction
Apr 24, 2025Non-independent and identically distributed (Non-IID) data across edge clients have long posed significant challenges to federated learning (FL) training in edge computing environments. Prior works have proposed various methods to mitigate this statistical heterogeneity. While these works can achieve good theoretical performance, in this work we provide the first investigation into a hidden over-correction phenomenon brought by the uniform model correction coefficients across clients adopted by existing methods. Such over-correction could degrade model performance and even cause failures in model convergence. To address this, we propose TACO, a novel algorithm that addresses the non-IID nature of clients' data by implementing fine-grained, client-specific gradient correction and model aggregation, steering local models towards a more accurate global optimum. Moreover, we verify that leading FL algorithms generally have better model accuracy in terms of communication rounds rather than wall-clock time, resulting from their extra computation overhead imposed on clients. To enhance the training efficiency, TACO deploys a lightweight model correction and tailored aggregation approach that requires minimum computation overhead and no extra information beyond the synchronized model parameters. To validate TACO's effectiveness, we present the first FL convergence analysis that reveals the root cause of over-correction. Extensive experiments across various datasets confirm TACO's superior and stable performance in practice.
Online Location Planning for AI-Defined Vehicles: Optimizing Joint Tasks of Order Serving and Spatio-Temporal Heterogeneous Model Fine-Tuning
Feb 06, 2025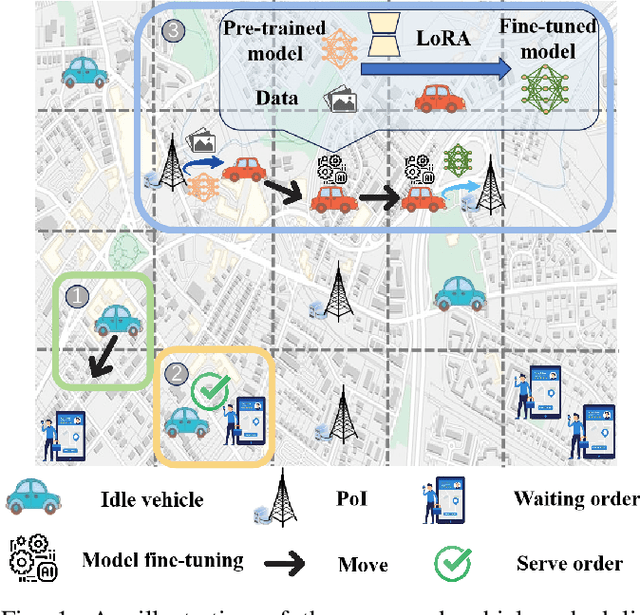



Advances in artificial intelligence (AI) including foundation models (FMs), are increasingly transforming human society, with smart city driving the evolution of urban living.Meanwhile, vehicle crowdsensing (VCS) has emerged as a key enabler, leveraging vehicles' mobility and sensor-equipped capabilities. In particular, ride-hailing vehicles can effectively facilitate flexible data collection and contribute towards urban intelligence, despite resource limitations. Therefore, this work explores a promising scenario, where edge-assisted vehicles perform joint tasks of order serving and the emerging foundation model fine-tuning using various urban data. However, integrating the VCS AI task with the conventional order serving task is challenging, due to their inconsistent spatio-temporal characteristics: (i) The distributions of ride orders and data point-of-interests (PoIs) may not coincide in geography, both following a priori unknown patterns; (ii) they have distinct forms of temporal effects, i.e., prolonged waiting makes orders become instantly invalid while data with increased staleness gradually reduces its utility for model fine-tuning.To overcome these obstacles, we propose an online framework based on multi-agent reinforcement learning (MARL) with careful augmentation. A new quality-of-service (QoS) metric is designed to characterize and balance the utility of the two joint tasks, under the effects of varying data volumes and staleness. We also integrate graph neural networks (GNNs) with MARL to enhance state representations, capturing graph-structured, time-varying dependencies among vehicles and across locations. Extensive experiments on our testbed simulator, utilizing various real-world foundation model fine-tuning tasks and the New York City Taxi ride order dataset, demonstrate the advantage of our proposed method.
CPT: Competence-progressive Training Strategy for Few-shot Node Classification
Feb 01, 2024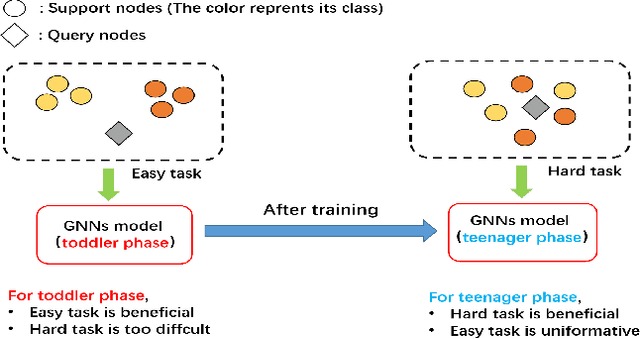
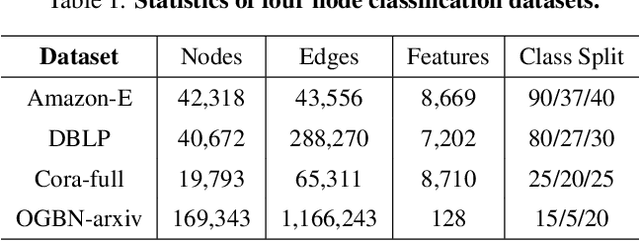


Graph Neural Networks (GNNs) have made significant advancements in node classification, but their success relies on sufficient labeled nodes per class in the training data. Real-world graph data often exhibits a long-tail distribution with sparse labels, emphasizing the importance of GNNs' ability in few-shot node classification, which entails categorizing nodes with limited data. Traditional episodic meta-learning approaches have shown promise in this domain, but they face an inherent limitation: it might lead the model to converge to suboptimal solutions because of random and uniform task assignment, ignoring task difficulty levels. This could lead the meta-learner to face complex tasks too soon, hindering proper learning. Ideally, the meta-learner should start with simple concepts and advance to more complex ones, like human learning. So, we introduce CPT, a novel two-stage curriculum learning method that aligns task difficulty with the meta-learner's progressive competence, enhancing overall performance. Specifically, in CPT's initial stage, the focus is on simpler tasks, fostering foundational skills for engaging with complex tasks later. Importantly, the second stage dynamically adjusts task difficulty based on the meta-learner's growing competence, aiming for optimal knowledge acquisition. Extensive experiments on popular node classification datasets demonstrate significant improvements of our strategy over existing methods.
DYNAMITE: Dynamic Interplay of Mini-Batch Size and Aggregation Frequency for Federated Learning with Static and Streaming Dataset
Oct 20, 2023Federated Learning (FL) is a distributed learning paradigm that can coordinate heterogeneous edge devices to perform model training without sharing private data. While prior works have focused on analyzing FL convergence with respect to hyperparameters like batch size and aggregation frequency, the joint effects of adjusting these parameters on model performance, training time, and resource consumption have been overlooked, especially when facing dynamic data streams and network characteristics. This paper introduces novel analytical models and optimization algorithms that leverage the interplay between batch size and aggregation frequency to navigate the trade-offs among convergence, cost, and completion time for dynamic FL training. We establish a new convergence bound for training error considering heterogeneous datasets across devices and derive closed-form solutions for co-optimized batch size and aggregation frequency that are consistent across all devices. Additionally, we design an efficient algorithm for assigning different batch configurations across devices, improving model accuracy and addressing the heterogeneity of both data and system characteristics. Further, we propose an adaptive control algorithm that dynamically estimates network states, efficiently samples appropriate data batches, and effectively adjusts batch sizes and aggregation frequency on the fly. Extensive experiments demonstrate the superiority of our offline optimal solutions and online adaptive algorithm.