 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDrone: Autonomous Drone Navigation Assisted by Edge and Cloud Foundation Models
Dec 24, 2025Autonomous navigation for Unmanned Aerial Vehicles faces key challenges from limited onboard computational resources, which restrict deployed deep neural networks to shallow architectures incapable of handling complex environments. Offloading tasks to remote edge servers introduces high latency, creating an inherent trade-off in system design. To address these limitations, we propose CoDrone - the first cloud-edge-end collaborative computing framework integrating foundation models into autonomous UAV cruising scenarios - effectively leveraging foundation models to enhance performance of resource-constrained unmanned aerial vehicle platforms. To reduce onboard computation and data transmission overhead, CoDrone employs grayscale imagery for the navigation model. When enhanced environmental perception is required, CoDrone leverages the edge-assisted foundation model Depth Anything V2 for depth estimation and introduces a novel one-dimensional occupancy grid-based navigation method - enabling fine-grained scene understanding while advancing efficiency and representational simplicity of autonomous navigation. A key component of CoDrone is a Deep Reinforcement Learning-based neural scheduler that seamlessly integrates depth estimation with autonomous navigation decisions, enabling real-time adaptation to dynamic environments. Furthermore, the framework introduces a UAV-specific vision language interaction module incorporating domain-tailored low-level flight primitives to enable effective interaction between the cloud foundation model and the UAV. The introduction of VLM enhances open-set reasoning capabilities in complex unseen scenarios. Experimental results show CoDrone outperforms baseline methods under varying flight speeds and network conditions, achieving a 40% increase in average flight distance and a 5% improvement in average Quality of Navigation.
BeeFlow: Behavior Tree-based Serverless Workflow Modeling and Scheduling for Resource-Constrained Edge Clusters
Aug 31, 2023



Serverless computing has gained popularity in edge computing due to its flexible features, including the pay-per-use pricing model, auto-scaling capabilities, and multi-tenancy support. Complex Serverless-based applications typically rely on Serverless workflows (also known as Serverless function orchestration) to express task execution logic, and numerous application- and system-level optimization techniques have been developed for Serverless workflow scheduling. However, there has been limited exploration of optimizing Serverless workflow scheduling in edge computing systems, particularly in high-density, resource-constrained environments such as system-on-chip clusters and single-board-computer clusters. In this work, we discover that existing Serverless workflow scheduling techniques typically assume models with limited expressiveness and cause significant resource contention. To address these issues, we propose modeling Serverless workflows using behavior trees, a novel and fundamentally different approach from existing directed-acyclic-graph- and state machine-based models. Behavior tree-based modeling allows for easy analysis without compromising workflow expressiveness. We further present observations derived from the inherent tree structure of behavior trees for contention-free function collections and awareness of exact and empirical concurrent function invocations. Based on these observations, we introduce BeeFlow, a behavior tree-based Serverless workflow system tailored for resource-constrained edge clusters. Experimental results demonstrate that BeeFlow achieves up to 3.2X speedup in a high-density, resource-constrained edge testbed and 2.5X speedup in a high-profile cloud testbed, compared with the state-of-the-art.
Serving Graph Neural Networks With Distributed Fog Servers For Smart IoT Services
Jul 04, 2023



Graph Neural Networks (GNNs) have gained growing interest in miscellaneous applications owing to their outstanding ability in extracting latent representation on graph structures. To render GNN-based service for IoT-driven smart applications, traditional model serving paradigms usually resort to the cloud by fully uploading geo-distributed input data to remote datacenters. However, our empirical measurements reveal the significant communication overhead of such cloud-based serving and highlight the profound potential in applying the emerging fog computing. To maximize the architectural benefits brought by fog computing, in this paper, we present Fograph, a novel distributed real-time GNN inference framework that leverages diverse and dynamic resources of multiple fog nodes in proximity to IoT data sources. By introducing heterogeneity-aware execution planning and GNN-specific compression techniques, Fograph tailors its design to well accommodate the unique characteristics of GNN serving in fog environments. Prototype-based evaluation and case study demonstrate that Fograph significantly outperforms the state-of-the-art cloud serving and fog deployment by up to 5.39x execution speedup and 6.84x throughput improvement.
Real-Time High-Resolution Pedestrian Detection in Crowded Scenes via Parallel Edge Offloading
Jan 20, 2023



To identify dense and small-size pedestrians in surveillance systems, high-resolution cameras are widely deployed, where high-resolution images are captured and delivered to off-the-shelf pedestrian detection models. However, given the highly computation-intensive workload brought by the high resolution, the resource-constrained cameras fail to afford accurate inference in real time. To address that, we propose Hode, an offloaded video analytic framework that utilizes multiple edge nodes in proximity to expedite pedestrian detection with high-resolution inputs. Specifically, Hode can intelligently split high-resolution images into respective regions and then offload them to distributed edge nodes to perform pedestrian detection in parallel. A spatio-temporal flow filtering method is designed to enable context-aware region partitioning, as well as a DRL-based scheduling algorithm to allow accuracy-aware load balance among heterogeneous edge nodes. Extensive evaluation results using realistic prototypes show that Hode can achieve up to 2.01% speedup with very mild accuracy loss.
Edge Robotics: Edge-Computing-Accelerated Multi-Robot Simultaneous Localization and Mapping
Jan 24, 2022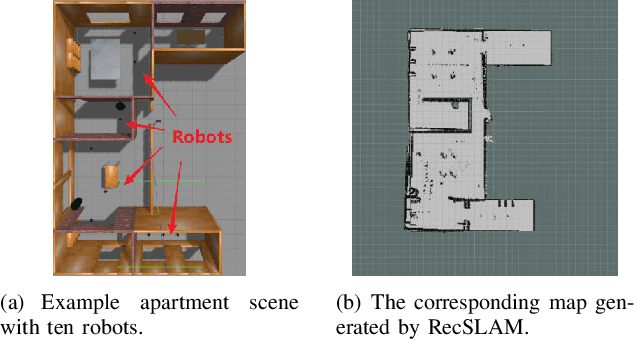


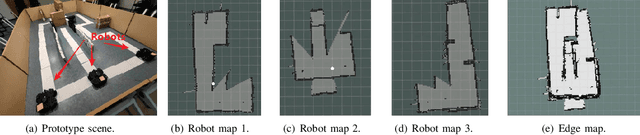
With the wide penetration of smart robots in multifarious fields, Simultaneous Localization and Mapping (SLAM) technique in robotics has attracted growing attention in the community. Yet collaborating SLAM over multiple robots still remains challenging due to performance contradiction between the intensive graphics computation of SLAM and the limited computing capability of robots. While traditional solutions resort to the powerful cloud servers acting as an external computation provider, we show by real-world measurements that the significant communication overhead in data offloading prevents its practicability to real deployment. To tackle these challenges, this paper promotes the emerging edge computing paradigm into multi-robot SLAM and proposes RecSLAM, a multi-robot laser SLAM system that focuses on accelerating map construction process under the robot-edge-cloud architecture. In contrast to conventional multi-robot SLAM that generates graphic maps on robots and completely merges them on the cloud, RecSLAM develops a hierarchical map fusion technique that directs robots' raw data to edge servers for real-time fusion and then sends to the cloud for global merging. To optimize the overall pipeline, an efficient multi-robot SLAM collaborative processing framework is introduced to adaptively optimize robot-to-edge offloading tailored to heterogeneous edge resource conditions, meanwhile ensuring the workload balancing among the edge servers. Extensive evaluations show RecSLAM can achieve up to 39% processing latency reduction over the state-of-the-art. Besides, a proof-of-concept prototype is developed and deployed in real scenes to demonstrate its effectiveness.
Hierarchical Large-scale Graph Similarity Computation via Graph Coarsening and Matching
Jun 09, 2020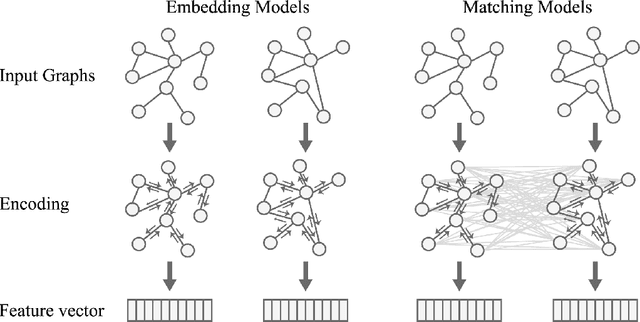
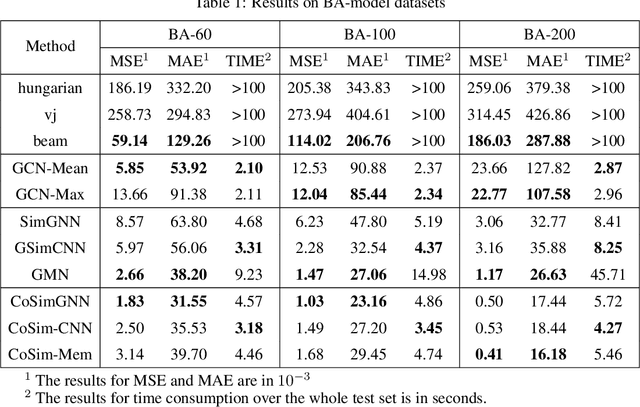
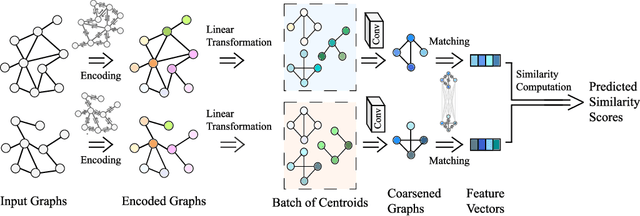
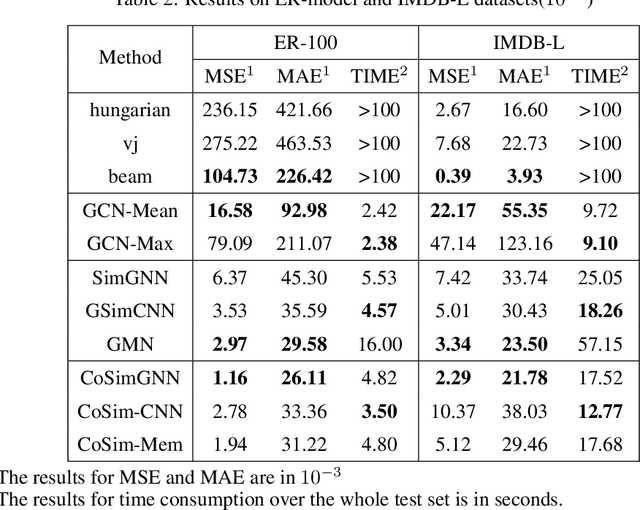
In this work, we focus on large graph similarity computation problem and propose a novel ``embedding-coarsening-matching'' learning framework, which outperforms state-of-the-art methods in this task and has significant improvement in time efficiency. Graph similarity computation for metrics such as Graph Edit Distance (GED) is typically NP-hard, and existing heuristics-based algorithms usually achieves a unsatisfactory trade-off between accuracy and efficiency. Recently the development of deep learning techniques provides a promising solution for this problem by a data-driven approach which trains a network to encode graphs to their own feature vectors and computes similarity based on feature vectors. These deep-learning methods can be classified to two categories, embedding models and matching models. Embedding models such as GCN-Mean and GCN-Max, which directly map graphs to respective feature vectors, run faster but the performance is usually poor due to the lack of interactions across graphs. Matching models such as GMN, whose encoding process involves interaction across the two graphs, are more accurate but interaction between whole graphs brings a significant increase in time consumption (at least quadratic time complexity over number of nodes). Inspired by large biological molecular identification where the whole molecular is first mapped to functional groups and then identified based on these functional groups, our ``embedding-coarsening-matching'' learning framework first embeds and coarsens large graphs to coarsened graphs with denser local topology and then matching mechanism is deployed on the coarsened graphs for the final similarity scores. Detailed experiments have been conducted and the results demonstrate the efficiency and effectiveness of our proposed framework.
Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing
May 24, 2019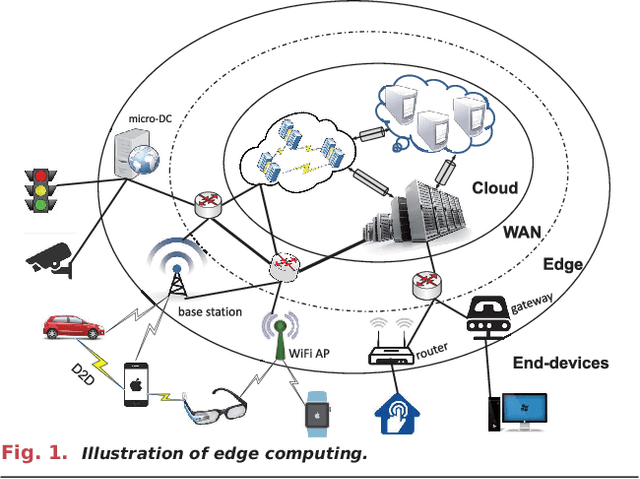
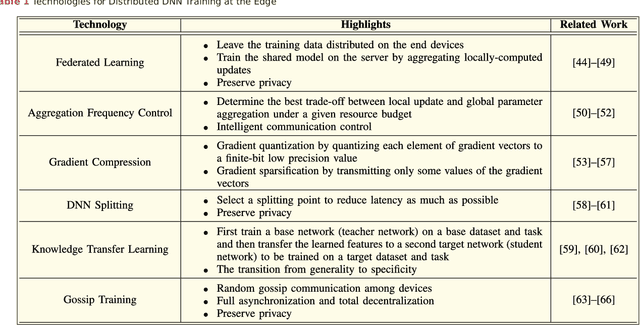
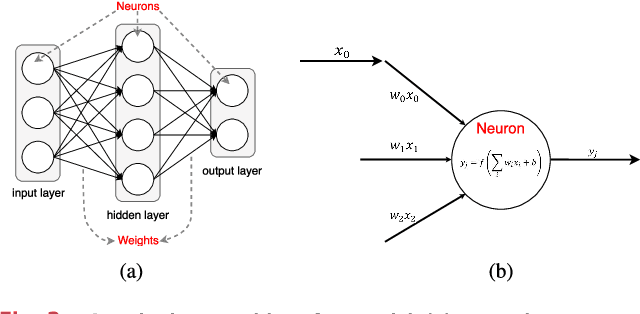
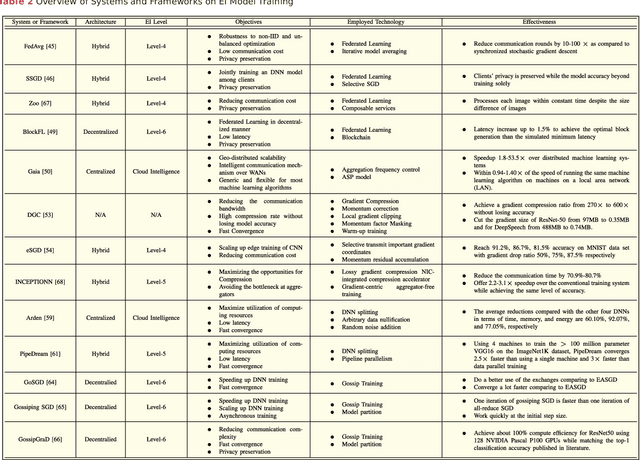
With the breakthroughs in deep learning, the recent years have witnessed a booming of artificial intelligence (AI) applications and services, spanning from personal assistant to recommendation systems to video/audio surveillance. More recently, with the proliferation of mobile computing and Internet-of-Things (IoT), billions of mobile and IoT devices are connected to the Internet, generating zillions Bytes of data at the network edge. Driving by this trend, there is an urgent need to push the AI frontiers to the network edge so as to fully unleash the potential of the edge big data. To meet this demand, edge computing, an emerging paradigm that pushes computing tasks and services from the network core to the network edge, has been widely recognized as a promising solution. The resulted new inter-discipline, edge AI or edge intelligence, is beginning to receive a tremendous amount of interest. However, research on edge intelligence is still in its infancy stage, and a dedicated venue for exchanging the recent advances of edge intelligence is highly desired by both the computer system and artificial intelligence communities. To this end, we conduct a comprehensive survey of the recent research efforts on edge intelligence. Specifically, we first review the background and motivation for artificial intelligence running at the network edge. We then provide an overview of the overarching architectures, frameworks and emerging key technologies for deep learning model towards training/inference at the network edge. Finally, we discuss future research opportunities on edge intelligence. We believe that this survey will elicit escalating attentions, stimulate fruitful discussions and inspire further research ideas on edge intelligence.