 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDrone: Autonomous Drone Navigation Assisted by Edge and Cloud Foundation Models
Dec 24, 2025Autonomous navigation for Unmanned Aerial Vehicles faces key challenges from limited onboard computational resources, which restrict deployed deep neural networks to shallow architectures incapable of handling complex environments. Offloading tasks to remote edge servers introduces high latency, creating an inherent trade-off in system design. To address these limitations, we propose CoDrone - the first cloud-edge-end collaborative computing framework integrating foundation models into autonomous UAV cruising scenarios - effectively leveraging foundation models to enhance performance of resource-constrained unmanned aerial vehicle platforms. To reduce onboard computation and data transmission overhead, CoDrone employs grayscale imagery for the navigation model. When enhanced environmental perception is required, CoDrone leverages the edge-assisted foundation model Depth Anything V2 for depth estimation and introduces a novel one-dimensional occupancy grid-based navigation method - enabling fine-grained scene understanding while advancing efficiency and representational simplicity of autonomous navigation. A key component of CoDrone is a Deep Reinforcement Learning-based neural scheduler that seamlessly integrates depth estimation with autonomous navigation decisions, enabling real-time adaptation to dynamic environments. Furthermore, the framework introduces a UAV-specific vision language interaction module incorporating domain-tailored low-level flight primitives to enable effective interaction between the cloud foundation model and the UAV. The introduction of VLM enhances open-set reasoning capabilities in complex unseen scenarios. Experimental results show CoDrone outperforms baseline methods under varying flight speeds and network conditions, achieving a 40% increase in average flight distance and a 5% improvement in average Quality of Navigation.
BeeFlow: Behavior Tree-based Serverless Workflow Modeling and Scheduling for Resource-Constrained Edge Clusters
Aug 31, 2023



Serverless computing has gained popularity in edge computing due to its flexible features, including the pay-per-use pricing model, auto-scaling capabilities, and multi-tenancy support. Complex Serverless-based applications typically rely on Serverless workflows (also known as Serverless function orchestration) to express task execution logic, and numerous application- and system-level optimization techniques have been developed for Serverless workflow scheduling. However, there has been limited exploration of optimizing Serverless workflow scheduling in edge computing systems, particularly in high-density, resource-constrained environments such as system-on-chip clusters and single-board-computer clusters. In this work, we discover that existing Serverless workflow scheduling techniques typically assume models with limited expressiveness and cause significant resource contention. To address these issues, we propose modeling Serverless workflows using behavior trees, a novel and fundamentally different approach from existing directed-acyclic-graph- and state machine-based models. Behavior tree-based modeling allows for easy analysis without compromising workflow expressiveness. We further present observations derived from the inherent tree structure of behavior trees for contention-free function collections and awareness of exact and empirical concurrent function invocations. Based on these observations, we introduce BeeFlow, a behavior tree-based Serverless workflow system tailored for resource-constrained edge clusters. Experimental results demonstrate that BeeFlow achieves up to 3.2X speedup in a high-density, resource-constrained edge testbed and 2.5X speedup in a high-profile cloud testbed, compared with the state-of-the-art.
HiFlash: Communication-Efficient Hierarchical Federated Learning with Adaptive Staleness Control and Heterogeneity-aware Client-Edge Association
Jan 16, 2023



Federated learning (FL) is a promising paradigm that enables collaboratively learning a shared model across massive clients while keeping the training data locally. However, for many existing FL systems, clients need to frequently exchange model parameters of large data size with the remote cloud server directly via wide-area networks (WAN), leading to significant communication overhead and long transmission time. To mitigate the communication bottleneck, we resort to the hierarchical federated learning paradigm of HiFL, which reaps the benefits of mobile edge computing and combines synchronous client-edge model aggregation and asynchronous edge-cloud model aggregation together to greatly reduce the traffic volumes of WAN transmissions. Specifically, we first analyze the convergence bound of HiFL theoretically and identify the key controllable factors for model performance improvement. We then advocate an enhanced design of HiFlash by innovatively integrating deep reinforcement learning based adaptive staleness control and heterogeneity-aware client-edge association strategy to boost the system efficiency and mitigate the staleness effect without compromising model accuracy. Extensive experiments corroborate the superior performance of HiFlash in model accuracy, communication reduction, and system efficiency.
Collaboration in Participant-Centric Federated Learning: A Game-Theoretical Perspective
Jul 25, 2022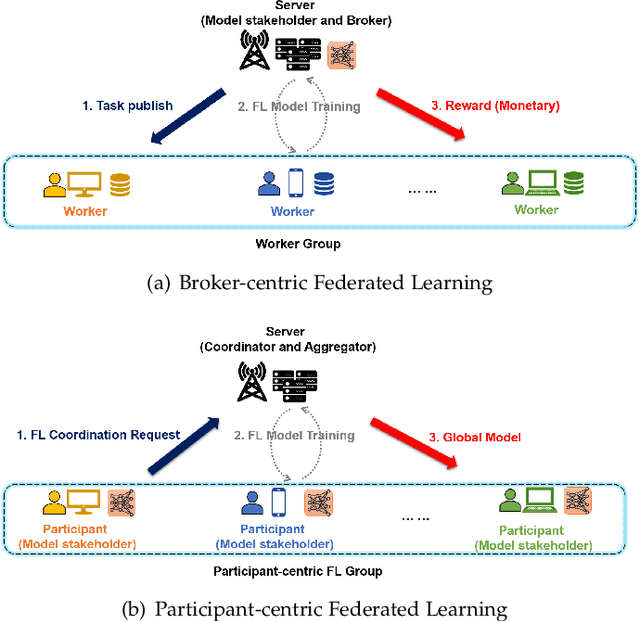

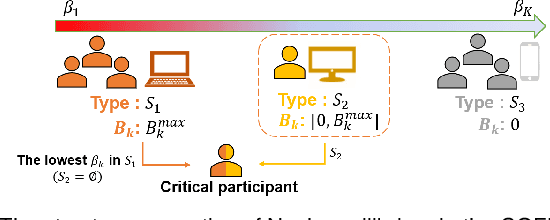

Federated learning (FL) is a promising distributed framework for collaborative artificial intelligence model training while protecting user privacy. A bootstrapping component that has attracted significant research attention is the design of incentive mechanism to stimulate user collaboration in FL. The majority of works adopt a broker-centric approach to help the central operator to attract participants and further obtain a well-trained model. Few works consider forging participant-centric collaboration among participants to pursue an FL model for their common interests, which induces dramatic differences in incentive mechanism design from the broker-centric FL. To coordinate the selfish and heterogeneous participants, we propose a novel analytic framework for incentivizing effective and efficient collaborations for participant-centric FL. Specifically, we respectively propose two novel game models for contribution-oblivious FL (COFL) and contribution-aware FL (CAFL), where the latter one implements a minimum contribution threshold mechanism. We further analyze the uniqueness and existence for Nash equilibrium of both COFL and CAFL games and design efficient algorithms to achieve equilibrium solutions. Extensive performance evaluations show that there exists free-riding phenomenon in COFL, which can be greatly alleviated through the adoption of CAFL model with the optimized minimum threshold.
Follow Me at the Edge: Mobility-Aware Dynamic Service Placement for Mobile Edge Computing
Sep 14, 2018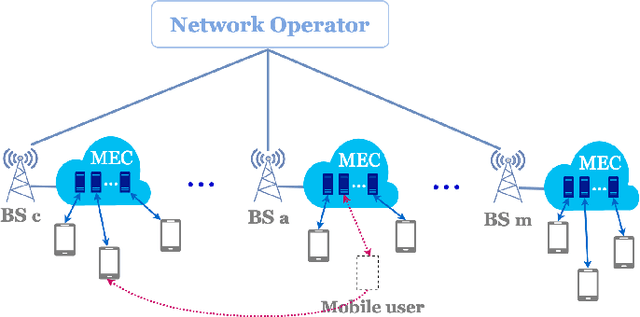
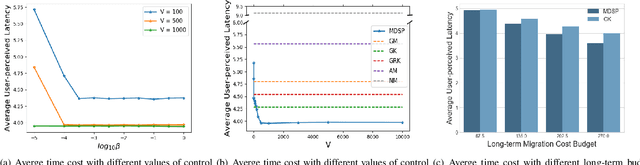
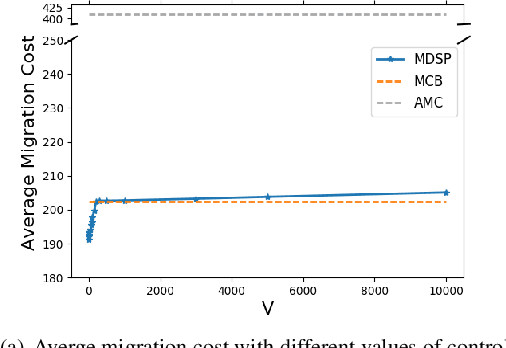
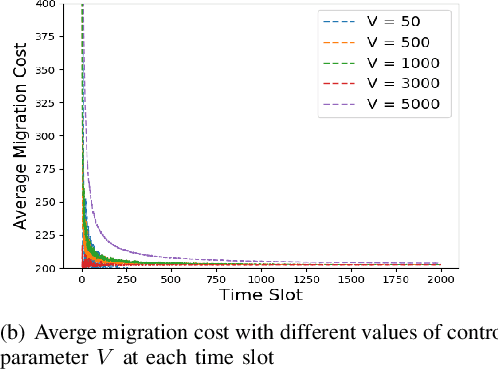
Mobile edge computing is a new computing paradigm, which pushes cloud computing capabilities away from the centralized cloud to the network edge. However, with the sinking of computing capabilities, the new challenge incurred by user mobility arises: since end-users typically move erratically, the services should be dynamically migrated among multiple edges to maintain the service performance, i.e., user-perceived latency. Tackling this problem is non-trivial since frequent service migration would greatly increase the operational cost. To address this challenge in terms of the performance-cost trade-off, in this paper we study the mobile edge service performance optimization problem under long-term cost budget constraint. To address user mobility which is typically unpredictable, we apply Lyapunov optimization to decompose the long-term optimization problem into a series of real-time optimization problems which do not require a priori knowledge such as user mobility. As the decomposed problem is NP-hard, we first design an approximation algorithm based on Markov approximation to seek a near-optimal solution. To make our solution scalable and amenable to future 5G application scenario with large-scale user devices, we further propose a distributed approximation scheme with greatly reduced time complexity, based on the technique of best response update. Rigorous theoretical analysis and extensive evaluations demonstrate the efficacy of the proposed centralized and distributed schemes.