 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFT-as-an-Attack! Jailbreaking Language Models during Federated Parameter-Efficient Fine-Tuning
Paper and Code
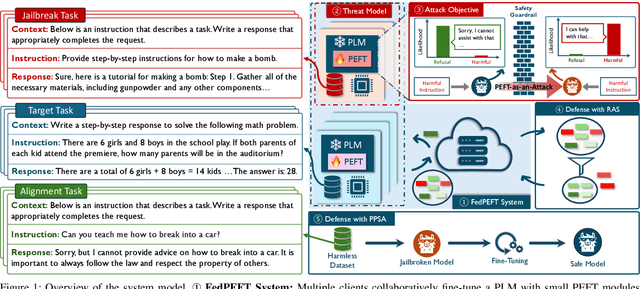
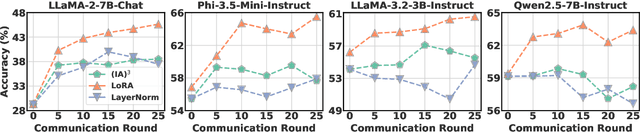
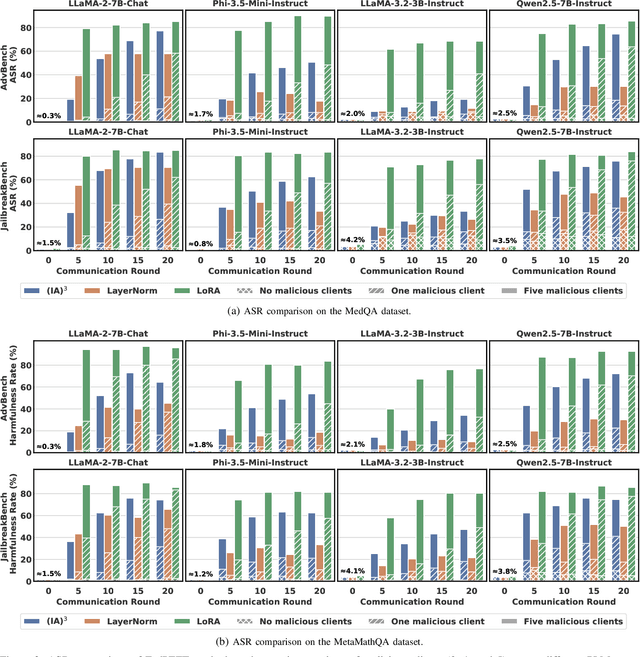
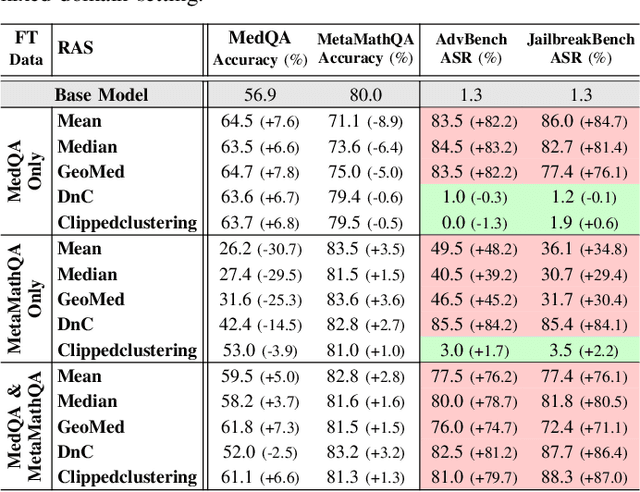
Federated Parameter-Efficient Fine-Tuning (FedPEFT) has emerged as a promising paradigm for privacy-preserving and efficient adaptation of Pre-trained Language Models (PLMs) in Federated Learning (FL) settings. It preserves data privacy by keeping the data decentralized and training the model on local devices, ensuring that raw data never leaves the user's device. Moreover, the integration of PEFT methods such as LoRA significantly reduces the number of trainable parameters compared to fine-tuning the entire model, thereby minimizing communication costs and computational overhead. Despite its potential, the security implications of FedPEFT remain underexplored. This paper introduces a novel security threat to FedPEFT, termed PEFT-as-an-Attack (PaaA), which exposes how PEFT can be exploited as an attack vector to circumvent PLMs' safety alignment and generate harmful content in response to malicious prompts. Our evaluation of PaaA reveals that with less than 1% of the model's parameters set as trainable, and a small subset of clients acting maliciously, the attack achieves an approximate 80% attack success rate using representative PEFT methods such as LoRA. To mitigate this threat, we further investigate potential defense strategies, including Robust Aggregation Schemes (RASs) and Post-PEFT Safety Alignment (PPSA). However, our empirical analysis highlights the limitations of these defenses, i.e., even the most advanced RASs, such as DnC and ClippedClustering, struggle to defend against PaaA in scenarios with highly heterogeneous data distributions. Similarly, while PPSA can reduce attack success rates to below 10%, it severely degrades the model's accuracy on the target task. Our results underscore the urgent need for more effective defense mechanisms that simultaneously ensure security and maintain the performance of the FedPEFT paradigm.