 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
Paper and Code
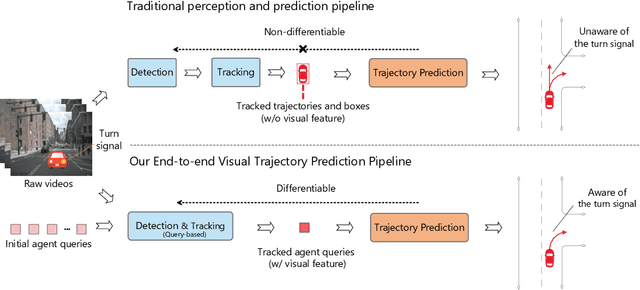
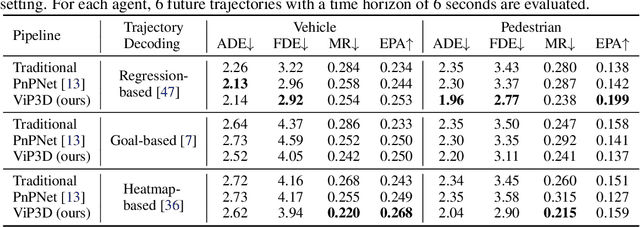
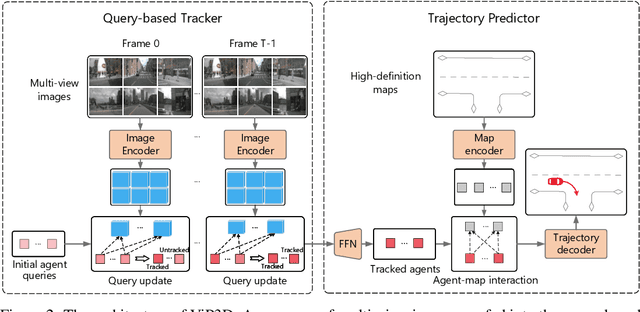
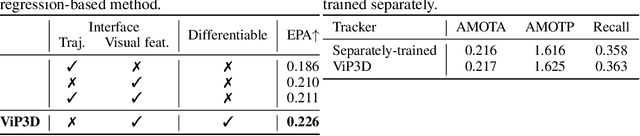
Existing autonomous driving pipelines separate the perception module from the prediction module. The two modules communicate via hand-picked features such as agent boxes and trajectories as interfaces. Due to this separation, the prediction module only receives partial information from the perception module. Even worse, errors from the perception modules can propagate and accumulate, adversely affecting the prediction results. In this work, we propose ViP3D, a visual trajectory prediction pipeline that leverages the rich information from raw videos to predict future trajectories of agents in a scene. ViP3D employs sparse agent queries throughout the pipeline, making it fully differentiable and interpretable. Furthermore, we propose an evaluation metric for this novel end-to-end visual trajectory prediction task. Extensive experimental results on the nuScenes dataset show the strong performance of ViP3D over traditional pipelines and previous end-to-end models.