 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Label-Independent Regularization from Spatial Dependencies for Whole Slide Image Analysis
Feb 23, 2026Whole slide images, with their gigapixel-scale panoramas of tissue samples, are pivotal for precise disease diagnosis. However, their analysis is hindered by immense data size and scarce annotations. Existing MIL methods face challenges due to the fundamental imbalance where a single bag-level label must guide the learning of numerous patch-level features. This sparse supervision makes it difficult to reliably identify discriminative patches during training, leading to unstable optimization and suboptimal solutions. We propose a spatially regularized MIL framework that leverages inherent spatial relationships among patch features as label-independent regularization signals. Our approach learns a shared representation space by jointly optimizing feature-induced spatial reconstruction and label-guided classification objectives, enforcing consistency between intrinsic structural patterns and supervisory signals. Experimental results on multiple public datasets demonstrate significant improvements over state-of-the-art methods, offering a promising direction.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025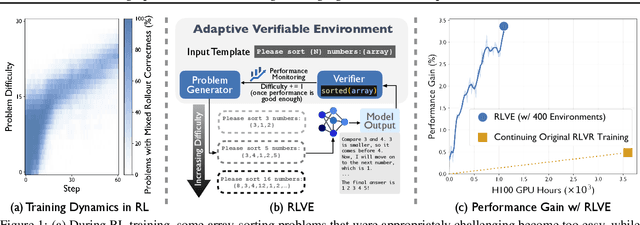

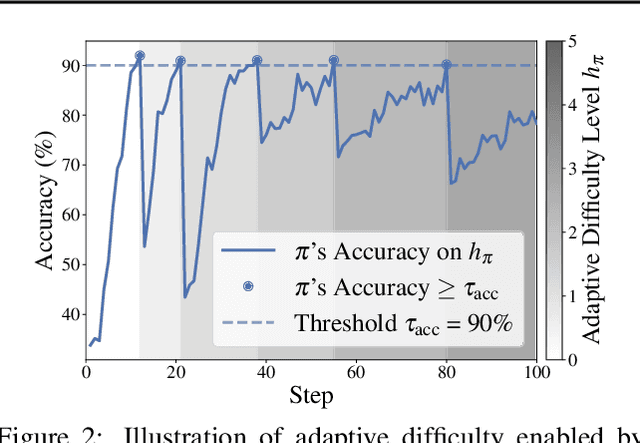
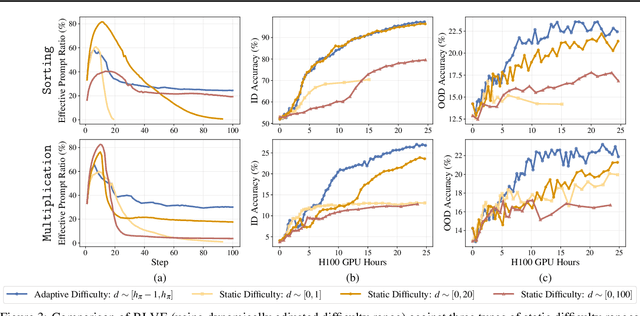
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Highlighting What Matters: Promptable Embeddings for Attribute-Focused Image Retrieval
May 21, 2025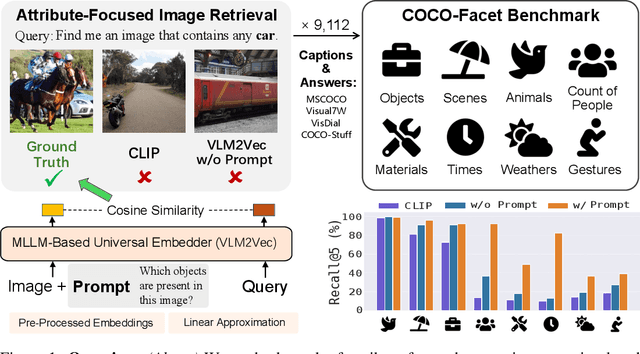
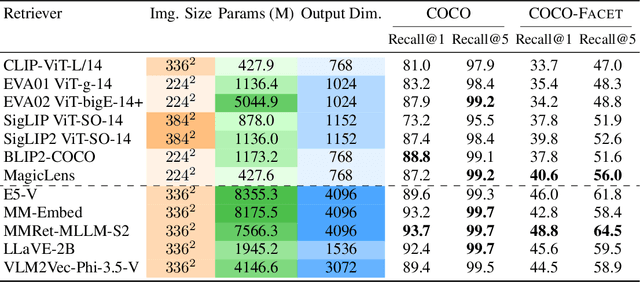
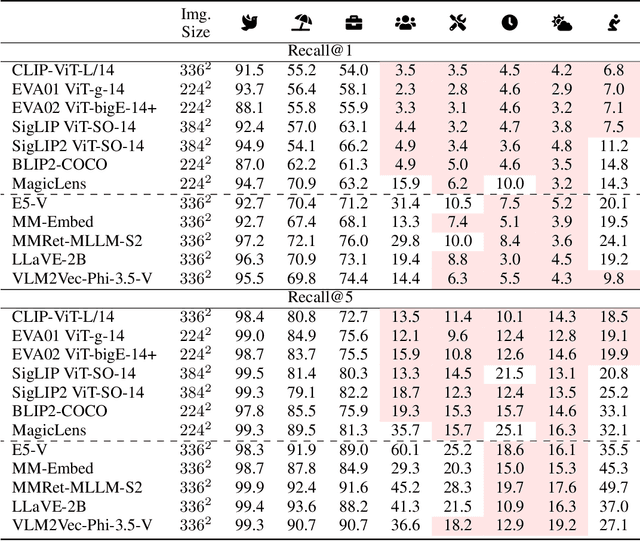
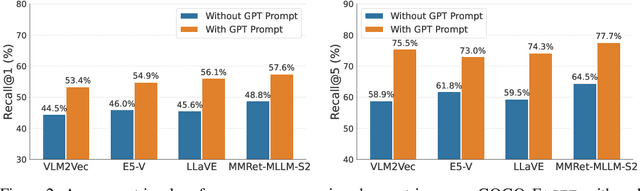
While an image is worth more than a thousand words, only a few provide crucial information for a given task and thus should be focused on. In light of this, ideal text-to-image (T2I) retrievers should prioritize specific visual attributes relevant to queries. To evaluate current retrievers on handling attribute-focused queries, we build COCO-Facet, a COCO-based benchmark with 9,112 queries about diverse attributes of interest. We find that CLIP-like retrievers, which are widely adopted due to their efficiency and zero-shot ability, have poor and imbalanced performance, possibly because their image embeddings focus on global semantics and subjects while leaving out other details. Notably, we reveal that even recent Multimodal Large Language Model (MLLM)-based, stronger retrievers with a larger output dimension struggle with this limitation. Hence, we hypothesize that retrieving with general image embeddings is suboptimal for performing such queries. As a solution, we propose to use promptable image embeddings enabled by these multimodal retrievers, which boost performance by highlighting required attributes. Our pipeline for deriving such embeddings generalizes across query types, image pools, and base retriever architectures. To enhance real-world applicability, we offer two acceleration strategies: Pre-processing promptable embeddings and using linear approximations. We show that the former yields a 15% improvement in Recall@5 when prompts are predefined, while the latter achieves an 8% improvement when prompts are only available during inference.
Assessing and Mitigating Medical Knowledge Drift and Conflicts in Large Language Models
May 12, 2025Large Language Models (LLMs) have great potential in the field of health care, yet they face great challenges in adapting to rapidly evolving medical knowledge. This can lead to outdated or contradictory treatment suggestions. This study investigated how LLMs respond to evolving clinical guidelines, focusing on concept drift and internal inconsistencies. We developed the DriftMedQA benchmark to simulate guideline evolution and assessed the temporal reliability of various LLMs. Our evaluation of seven state-of-the-art models across 4,290 scenarios demonstrated difficulties in rejecting outdated recommendations and frequently endorsing conflicting guidance. Additionally, we explored two mitigation strategies: Retrieval-Augmented Generation and preference fine-tuning via Direct Preference Optimization. While each method improved model performance, their combination led to the most consistent and reliable results. These findings underscore the need to improve LLM robustness to temporal shifts to ensure more dependable applications in clinical practice.
On Erroneous Agreements of CLIP Image Embeddings
Nov 07, 2024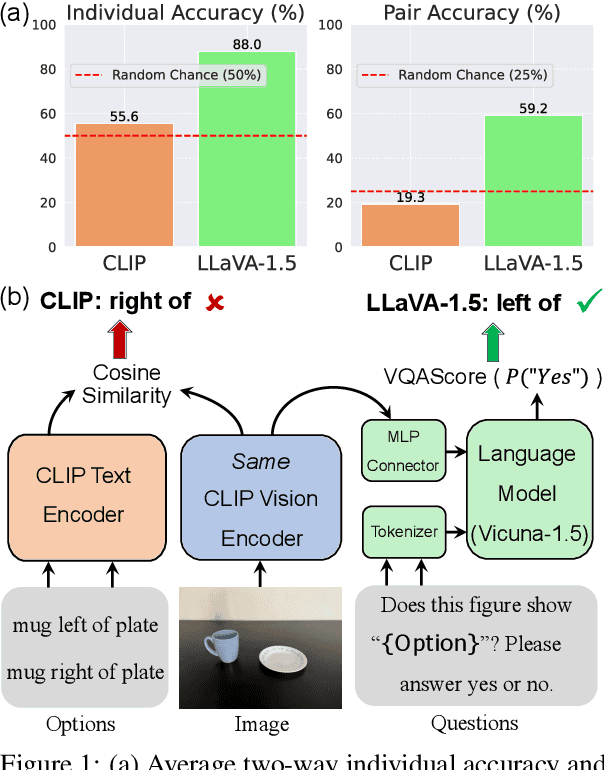
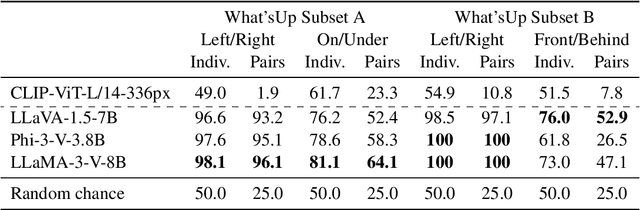
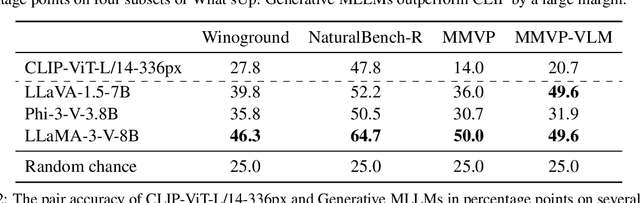
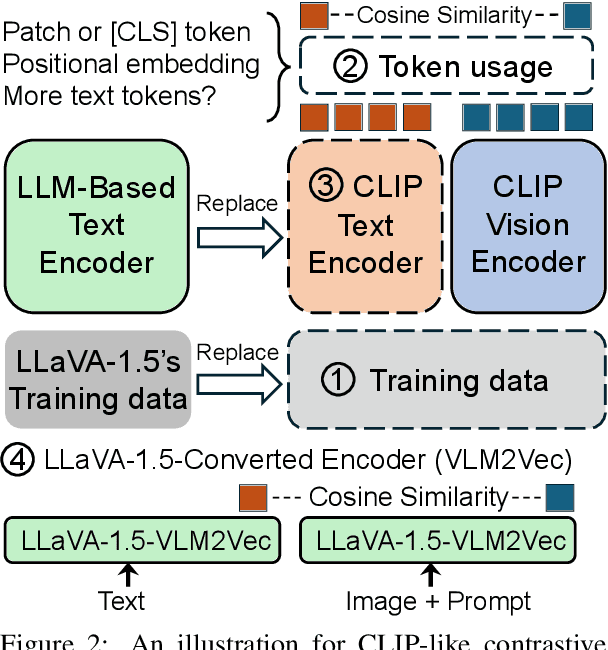
Recent research suggests that the failures of Vision-Language Models (VLMs) at visual reasoning often stem from erroneous agreements -- when semantically distinct images are ambiguously encoded by the CLIP image encoder into embeddings with high cosine similarity. In this paper, we show that erroneous agreements are not always the main culprit, as Multimodal Large Language Models (MLLMs) can still extract distinct information from them. For instance, when distinguishing objects on the left vs right in the What'sUp benchmark, the CLIP image embeddings of the left/right pairs have an average cosine similarity $>0.99$, and CLIP performs at random chance; but LLaVA-1.5-7B, which uses the same CLIP image encoder, achieves nearly $100\%$ accuracy. We find that the extractable information in CLIP image embeddings is likely obscured by CLIP's inadequate vision-language alignment: Its matching score learned by the contrastive objective might not capture all diverse image-text correspondences. We also study the MMVP benchmark, on which prior work has shown that LLaVA-1.5 cannot distinguish image pairs with high cosine similarity. We observe a performance gain brought by attending more to visual input through an alternative decoding algorithm. Further, the accuracy significantly increases if the model can take both images as input to emphasize their nuanced differences. Both findings indicate that LLaVA-1.5 did not utilize extracted visual information sufficiently. In conclusion, our findings suggest that while improving image encoders could benefit VLMs, there is still room to enhance models with a fixed image encoder by applying better strategies for extracting and utilizing visual information.
Memory-Efficient Sparse Pyramid Attention Networks for Whole Slide Image Analysis
Jun 13, 2024



Whole Slide Images (WSIs) are crucial for modern pathological diagnosis, yet their gigapixel-scale resolutions and sparse informative regions pose significant computational challenges. Traditional dense attention mechanisms, widely used in computer vision and natural language processing, are impractical for WSI analysis due to the substantial data scale and the redundant processing of uninformative areas. To address these challenges, we propose Memory-Efficient Sparse Pyramid Attention Networks with Shifted Windows (SPAN), drawing inspiration from state-of-the-art sparse attention techniques in other domains. SPAN introduces a sparse pyramid attention architecture that hierarchically focuses on informative regions within the WSI, aiming to reduce memory overhead while preserving critical features. Additionally, the incorporation of shifted windows enables the model to capture long-range contextual dependencies essential for accurate classification. We evaluated SPAN on multiple public WSI datasets, observing its competitive performance. Unlike existing methods that often struggle to model spatial and contextual information due to memory constraints, our approach enables the accurate modeling of these crucial features. Our study also highlights the importance of key design elements in attention mechanisms, such as the shifted-window scheme and the hierarchical structure, which contribute substantially to the effectiveness of SPAN in WSI analysis. The potential of SPAN for memory-efficient and effective analysis of WSI data is thus demonstrated, and the code will be made publicly available following the publication of this work.
What Makes for Robust Multi-Modal Models in the Face of Missing Modalities?
Oct 10, 2023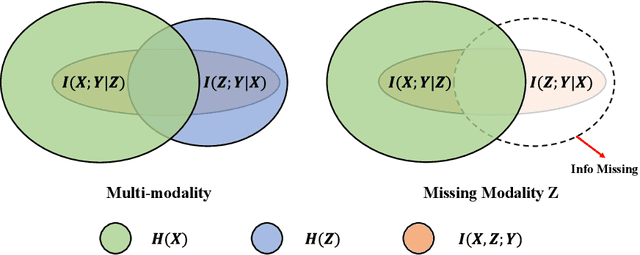
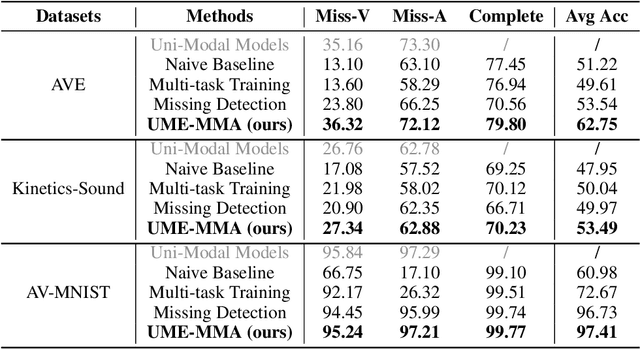
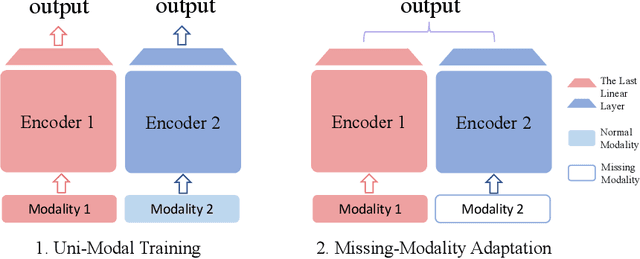
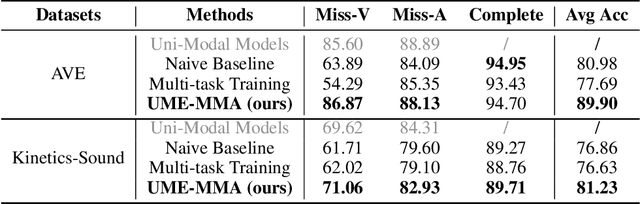
With the growing success of multi-modal learning, research on the robustness of multi-modal models, especially when facing situations with missing modalities, is receiving increased attention. Nevertheless, previous studies in this domain exhibit certain limitations, as they often lack theoretical insights or their methodologies are tied to specific network architectures or modalities. We model the scenarios of multi-modal models encountering missing modalities from an information-theoretic perspective and illustrate that the performance ceiling in such scenarios can be approached by efficiently utilizing the information inherent in non-missing modalities. In practice, there are two key aspects: (1) The encoder should be able to extract sufficiently good features from the non-missing modality; (2) The extracted features should be robust enough not to be influenced by noise during the fusion process across modalities. To this end, we introduce Uni-Modal Ensemble with Missing Modality Adaptation (UME-MMA). UME-MMA employs uni-modal pre-trained weights for the multi-modal model to enhance feature extraction and utilizes missing modality data augmentation techniques to better adapt to situations with missing modalities. Apart from that, UME-MMA, built on a late-fusion learning framework, allows for the plug-and-play use of various encoders, making it suitable for a wide range of modalities and enabling seamless integration of large-scale pre-trained encoders to further enhance performance. And we demonstrate UME-MMA's effectiveness in audio-visual datasets~(e.g., AV-MNIST, Kinetics-Sound, AVE) and vision-language datasets~(e.g., MM-IMDB, UPMC Food101).
Training-Free Robust Multimodal Learning via Sample-Wise Jacobian Regularization
Apr 05, 2022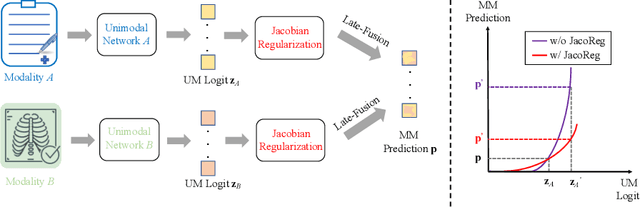
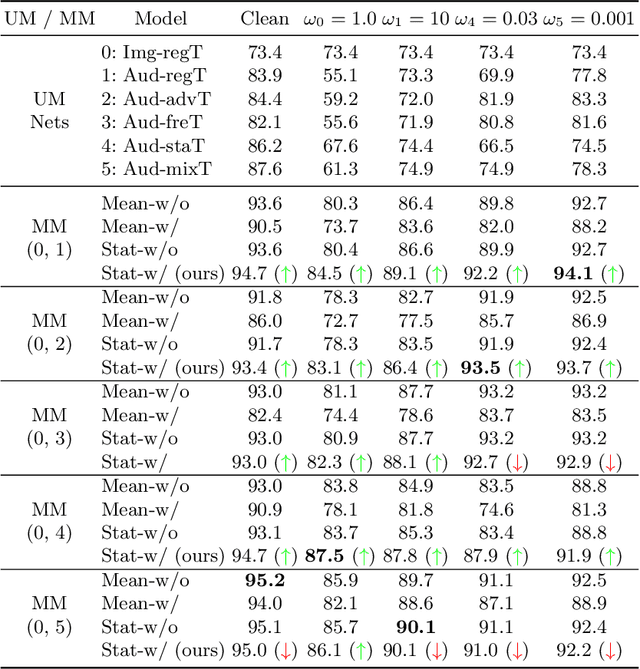
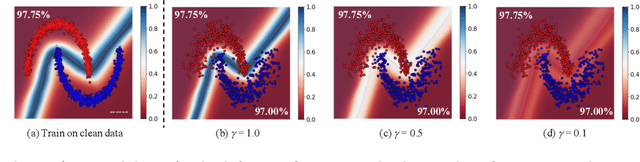
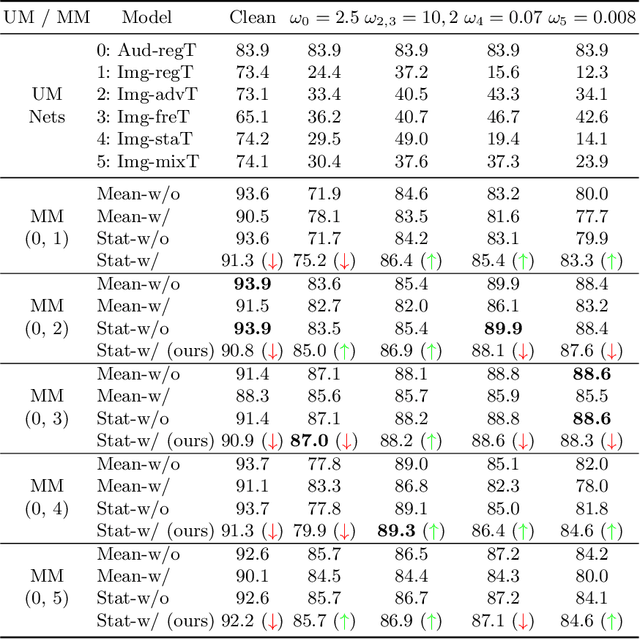
Multimodal fusion emerges as an appealing technique to improve model performances on many tasks. Nevertheless, the robustness of such fusion methods is rarely involved in the present literature. In this paper, we propose a training-free robust late-fusion method by exploiting conditional independence assumption and Jacobian regularization. Our key is to minimize the Frobenius norm of a Jacobian matrix, where the resulting optimization problem is relaxed to a tractable Sylvester equation. Furthermore, we provide a theoretical error bound of our method and some insights about the function of the extra modality. Several numerical experiments on AV-MNIST, RAVDESS, and VGGsound demonstrate the efficacy of our method under both adversarial attacks and random corruptions.
Difference-in-Differences: Bridging Normalization and Disentanglement in PG-GAN
Oct 16, 2020
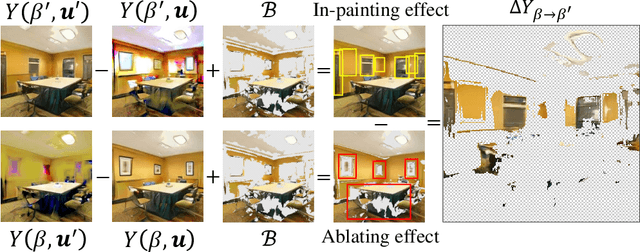
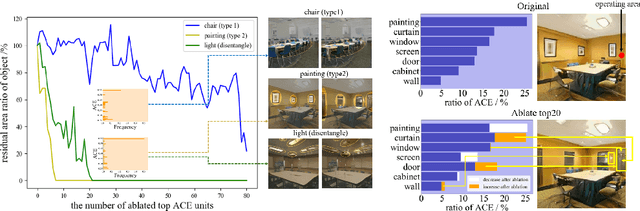
What mechanisms causes GAN's entanglement? Although developing disentangled GAN has attracted sufficient attention, it is unclear how entanglement is originated by GAN transformation. We in this research propose a difference-in-difference (DID) counterfactual framework to design experiments for analyzing the entanglement mechanism in on of the Progressive-growing GAN (PG-GAN). Our experiment clarify the mechanisms how pixel normalization causes PG-GAN entanglement during a input-unit-ablation transformation. We discover that pixel normalization causes object entanglement by in-painting the area occupied by ablated objects. We also discover the unit-object relation determines whether and how pixel normalization causes objects entanglement. Our DID framework theoretically guarantees that the mechanisms that we discover is solid, explainable and comprehensively.