 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Erroneous Agreements of CLIP Image Embeddings
Paper and Code
Nov 07, 2024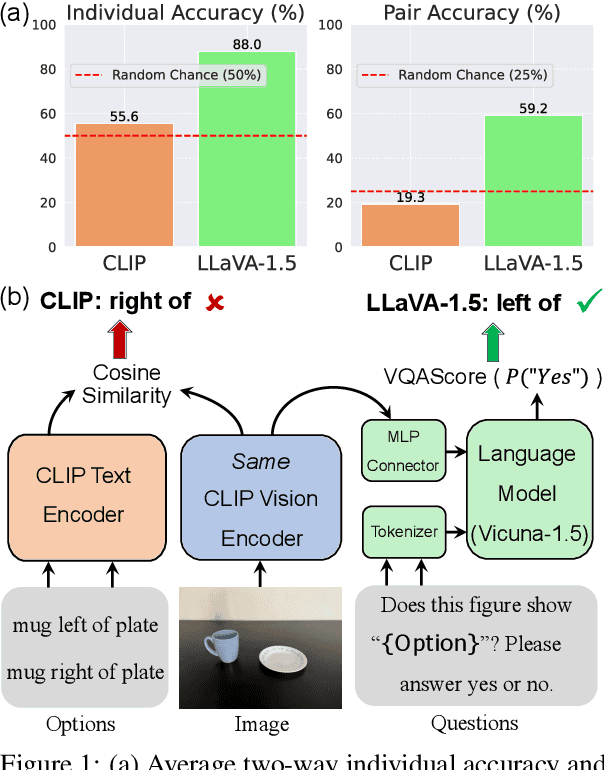
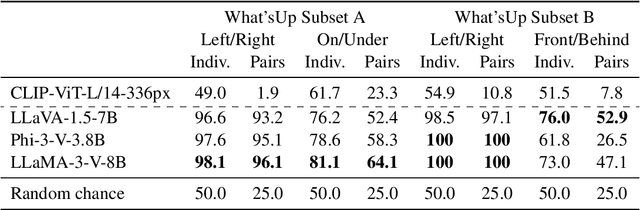
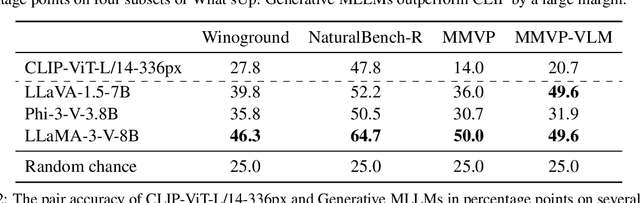
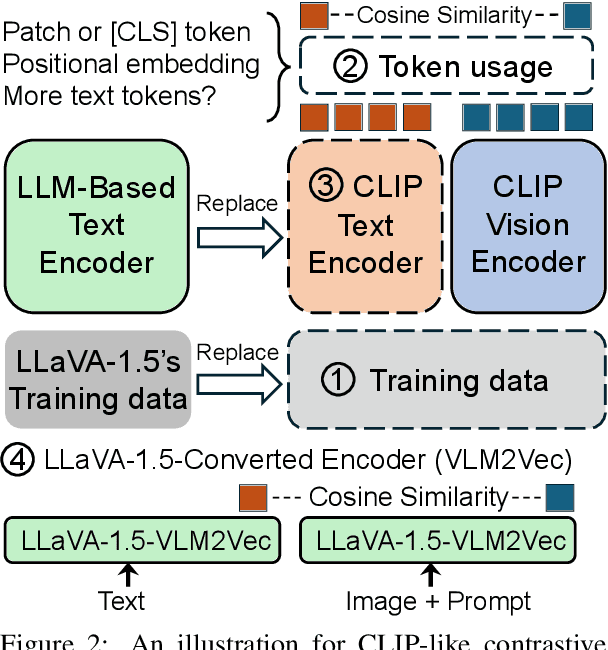
Recent research suggests that the failures of Vision-Language Models (VLMs) at visual reasoning often stem from erroneous agreements -- when semantically distinct images are ambiguously encoded by the CLIP image encoder into embeddings with high cosine similarity. In this paper, we show that erroneous agreements are not always the main culprit, as Multimodal Large Language Models (MLLMs) can still extract distinct information from them. For instance, when distinguishing objects on the left vs right in the What'sUp benchmark, the CLIP image embeddings of the left/right pairs have an average cosine similarity $>0.99$, and CLIP performs at random chance; but LLaVA-1.5-7B, which uses the same CLIP image encoder, achieves nearly $100\%$ accuracy. We find that the extractable information in CLIP image embeddings is likely obscured by CLIP's inadequate vision-language alignment: Its matching score learned by the contrastive objective might not capture all diverse image-text correspondences. We also study the MMVP benchmark, on which prior work has shown that LLaVA-1.5 cannot distinguish image pairs with high cosine similarity. We observe a performance gain brought by attending more to visual input through an alternative decoding algorithm. Further, the accuracy significantly increases if the model can take both images as input to emphasize their nuanced differences. Both findings indicate that LLaVA-1.5 did not utilize extracted visual information sufficiently. In conclusion, our findings suggest that while improving image encoders could benefit VLMs, there is still room to enhance models with a fixed image encoder by applying better strategies for extracting and utilizing visual information.