 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Robust Multi-Modal Models in the Face of Missing Modalities?
Paper and Code
Oct 10, 2023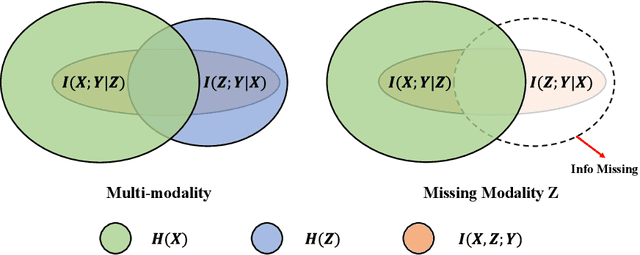
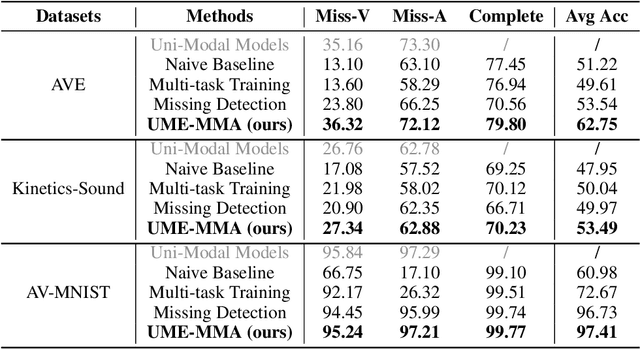
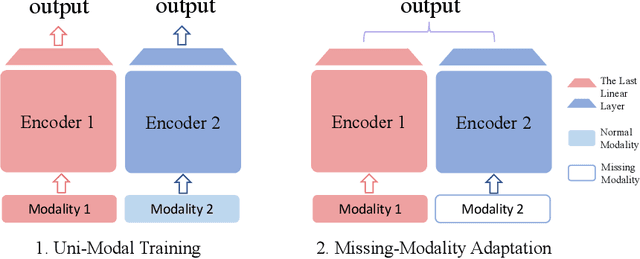
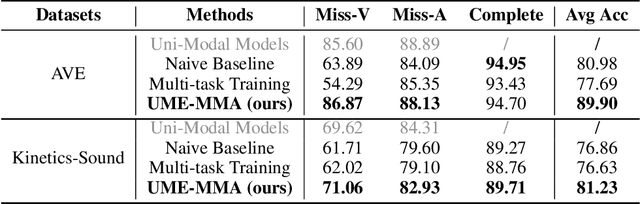
With the growing success of multi-modal learning, research on the robustness of multi-modal models, especially when facing situations with missing modalities, is receiving increased attention. Nevertheless, previous studies in this domain exhibit certain limitations, as they often lack theoretical insights or their methodologies are tied to specific network architectures or modalities. We model the scenarios of multi-modal models encountering missing modalities from an information-theoretic perspective and illustrate that the performance ceiling in such scenarios can be approached by efficiently utilizing the information inherent in non-missing modalities. In practice, there are two key aspects: (1) The encoder should be able to extract sufficiently good features from the non-missing modality; (2) The extracted features should be robust enough not to be influenced by noise during the fusion process across modalities. To this end, we introduce Uni-Modal Ensemble with Missing Modality Adaptation (UME-MMA). UME-MMA employs uni-modal pre-trained weights for the multi-modal model to enhance feature extraction and utilizes missing modality data augmentation techniques to better adapt to situations with missing modalities. Apart from that, UME-MMA, built on a late-fusion learning framework, allows for the plug-and-play use of various encoders, making it suitable for a wide range of modalities and enabling seamless integration of large-scale pre-trained encoders to further enhance performance. And we demonstrate UME-MMA's effectiveness in audio-visual datasets~(e.g., AV-MNIST, Kinetics-Sound, AVE) and vision-language datasets~(e.g., MM-IMDB, UPMC Food101).