 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsically Motivated Self-supervised Learning in Reinforcement Learning
Paper and Code
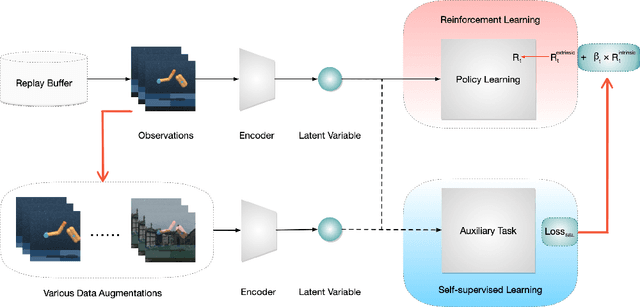
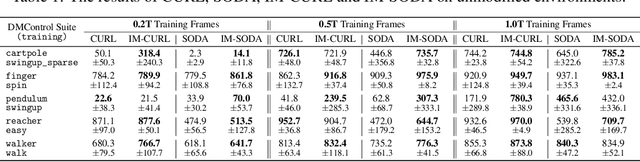
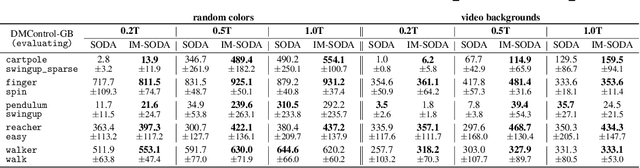

In vision-based reinforcement learning (RL) tasks, it is prevalent to assign the auxiliary task with a surrogate self-supervised loss so as to obtain more semantic representations and improve sample efficiency. However, abundant information in self-supervised auxiliary tasks has been disregarded, since the representation learning part and the decision-making part are separated. To sufficiently utilize information in the auxiliary task, we present a simple yet effective idea to employ self-supervised loss as an intrinsic reward, called Intrinsically Motivated Self-Supervised learning in Reinforcement learning (IM-SSR). We formally show that the self-supervised loss can be decomposed as exploration for novel states and robustness improvement from nuisance elimination. IM-SSR can be effortlessly plugged into any reinforcement learning with self-supervised auxiliary objectives with nearly no additional cost. Combined with IM-SSR, the previous underlying algorithms achieve salient improvements on both sample efficiency and generalization in various vision-based robotics tasks from the DeepMind Control Suite, especially when the reward signal is sparse.