 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025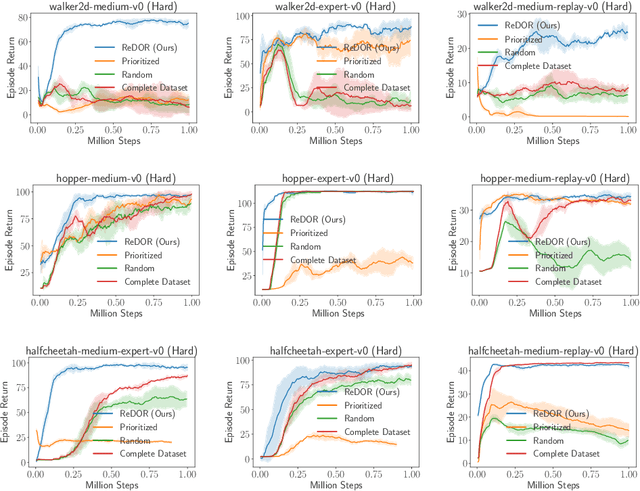
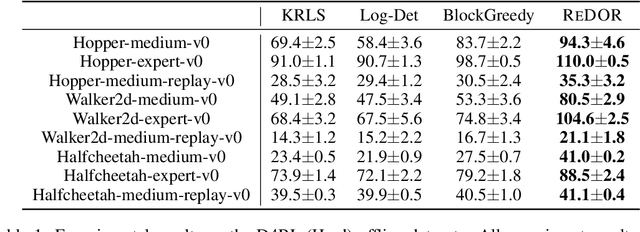

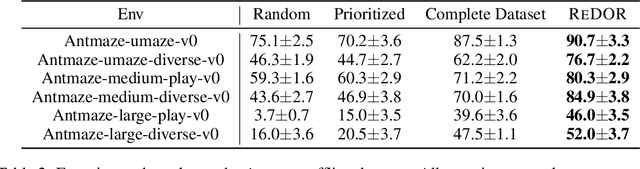
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.
High-Quality Real Time Facial Capture Based on Single Camera
Nov 15, 2021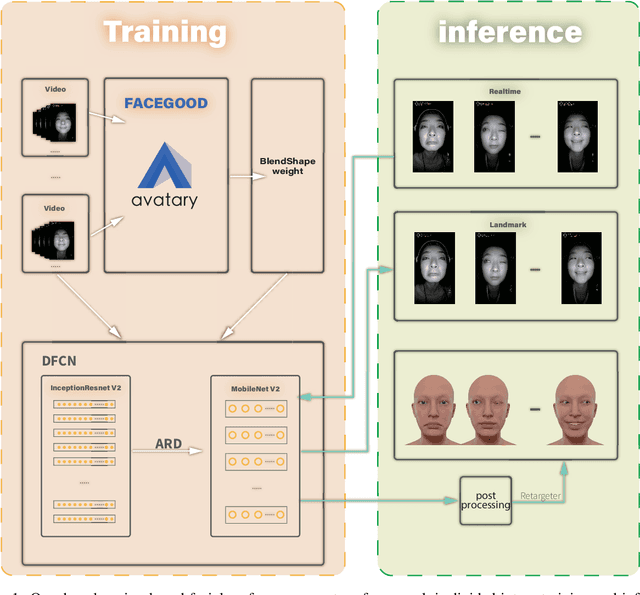



We propose a real time deep learning framework for video-based facial expression capture. Our process uses a high-end facial capture pipeline based on FACEGOOD to capture facial expression. We train a convolutional neural network to produce high-quality continuous blendshape weight output from video training. Since this facial capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We demonstrate compelling animation inference in challenging areas such as eyes and lips.