Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Real Time Facial Capture Based on Single Camera
Paper and Code
Nov 15, 2021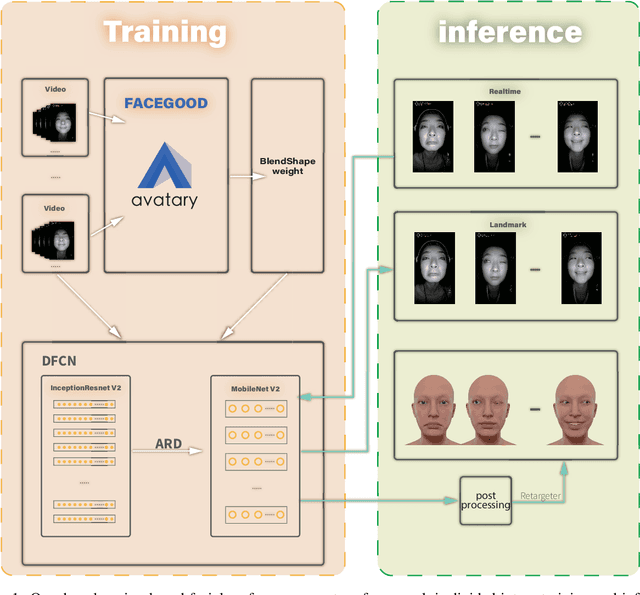



We propose a real time deep learning framework for video-based facial expression capture. Our process uses a high-end facial capture pipeline based on FACEGOOD to capture facial expression. We train a convolutional neural network to produce high-quality continuous blendshape weight output from video training. Since this facial capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We demonstrate compelling animation inference in challenging areas such as eyes and lips.
* arXiv admin note: text overlap with arXiv:1609.06536 by other authors
View paper on