 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Silent Majority: Demystifying Memorization Effect in the Presence of Spurious Correlations
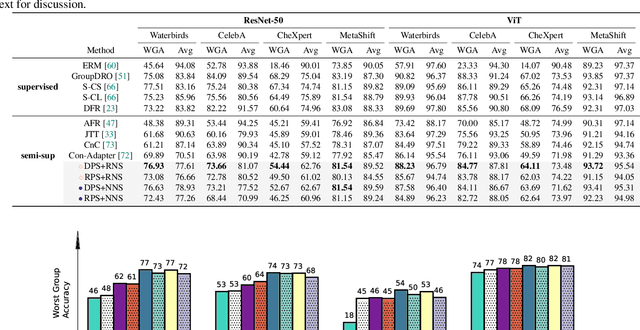
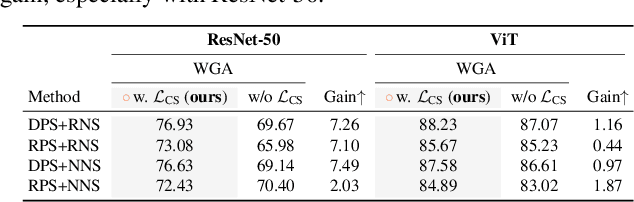
Jan 01, 2025Machine learning models often rely on simple spurious features -- patterns in training data that correlate with targets but are not causally related to them, like image backgrounds in foreground classification. This reliance typically leads to imbalanced test performance across minority and majority groups. In this work, we take a closer look at the fundamental cause of such imbalanced performance through the lens of memorization, which refers to the ability to predict accurately on \textit{atypical} examples (minority groups) in the training set but failing in achieving the same accuracy in the testing set. This paper systematically shows the ubiquitous existence of spurious features in a small set of neurons within the network, providing the first-ever evidence that memorization may contribute to imbalanced group performance. Through three experimental sources of converging empirical evidence, we find the property of a small subset of neurons or channels in memorizing minority group information. Inspired by these findings, we articulate the hypothesis: the imbalanced group performance is a byproduct of ``noisy'' spurious memorization confined to a small set of neurons. To further substantiate this hypothesis, we show that eliminating these unnecessary spurious memorization patterns via a novel framework during training can significantly affect the model performance on minority groups. Our experimental results across various architectures and benchmarks offer new insights on how neural networks encode core and spurious knowledge, laying the groundwork for future research in demystifying robustness to spurious correlation.
Calibrating Multi-modal Representations: A Pursuit of Group Robustness without Annotations
Mar 12, 2024

Fine-tuning pre-trained vision-language models, like CLIP, has yielded success on diverse downstream tasks. However, several pain points persist for this paradigm: (i) directly tuning entire pre-trained models becomes both time-intensive and computationally costly. Additionally, these tuned models tend to become highly specialized, limiting their practicality for real-world deployment; (ii) recent studies indicate that pre-trained vision-language classifiers may overly depend on spurious features -- patterns that correlate with the target in training data, but are not related to the true labeling function; and (iii) existing studies on mitigating the reliance on spurious features, largely based on the assumption that we can identify such features, does not provide definitive assurance for real-world applications. As a piloting study, this work focuses on exploring mitigating the reliance on spurious features for CLIP without using any group annotation. To this end, we systematically study the existence of spurious correlation on CLIP and CILP+ERM. We first, following recent work on Deep Feature Reweighting (DFR), verify that last-layer retraining can greatly improve group robustness on pretrained CLIP. In view of them, we advocate a lightweight representation calibration method for fine-tuning CLIP, by first generating a calibration set using the pretrained CLIP, and then calibrating representations of samples within this set through contrastive learning, all without the need for group labels. Extensive experiments and in-depth visualizations on several benchmarks validate the effectiveness of our proposals, largely reducing reliance and significantly boosting the model generalization.
Cooperative Multi-Agent Reinforcement Learning: Asynchronous Communication and Linear Function Approximation
May 12, 2023We study multi-agent reinforcement learning in the setting of episodic Markov decision processes, where multiple agents cooperate via communication through a central server. We propose a provably efficient algorithm based on value iteration that enable asynchronous communication while ensuring the advantage of cooperation with low communication overhead. With linear function approximation, we prove that our algorithm enjoys an $\tilde{\mathcal{O}}(d^{3/2}H^2\sqrt{K})$ regret with $\tilde{\mathcal{O}}(dHM^2)$ communication complexity, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the total number of agents, and $K$ is the total number of episodes. We also provide a lower bound showing that a minimal $\Omega(dM)$ communication complexity is required to improve the performance through collaboration.
ACTION++: Improving Semi-supervised Medical Image Segmentation with Adaptive Anatomical Contrast
Apr 07, 2023
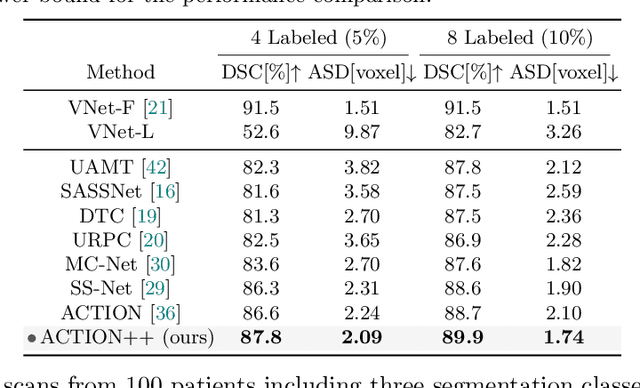
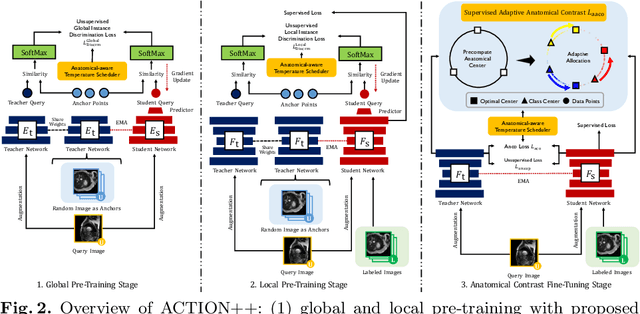
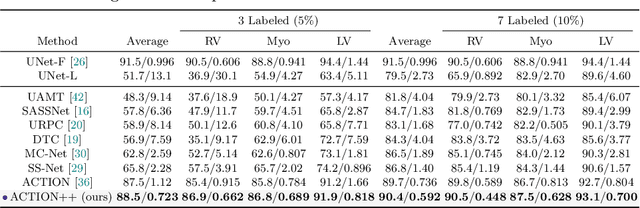
Medical data often exhibits long-tail distributions with heavy class imbalance, which naturally leads to difficulty in classifying the minority classes (i.e., boundary regions or rare objects). Recent work has significantly improved semi-supervised medical image segmentation in long-tailed scenarios by equipping them with unsupervised contrastive criteria. However, it remains unclear how well they will perform in the labeled portion of data where class distribution is also highly imbalanced. In this work, we present ACTION++, an improved contrastive learning framework with adaptive anatomical contrast for semi-supervised medical segmentation. Specifically, we propose an adaptive supervised contrastive loss, where we first compute the optimal locations of class centers uniformly distributed on the embedding space (i.e., off-line), and then perform online contrastive matching training by encouraging different class features to adaptively match these distinct and uniformly distributed class centers. Moreover, we argue that blindly adopting a constant temperature $\tau$ in the contrastive loss on long-tailed medical data is not optimal, and propose to use a dynamic $\tau$ via a simple cosine schedule to yield better separation between majority and minority classes. Empirically, we evaluate ACTION++ on ACDC and LA benchmarks and show that it achieves state-of-the-art across two semi-supervised settings. Theoretically, we analyze the performance of adaptive anatomical contrast and confirm its superiority in label efficiency.
Implicit Anatomical Rendering for Medical Image Segmentation with Stochastic Experts
Apr 06, 2023



Integrating high-level semantically correlated contents and low-level anatomical features is of central importance in medical image segmentation. Towards this end, recent deep learning-based medical segmentation methods have shown great promise in better modeling such information. However, convolution operators for medical segmentation typically operate on regular grids, which inherently blur the high-frequency regions, i.e., boundary regions. In this work, we propose MORSE, a generic implicit neural rendering framework designed at an anatomical level to assist learning in medical image segmentation. Our method is motivated by the fact that implicit neural representation has been shown to be more effective in fitting complex signals and solving computer graphics problems than discrete grid-based representation. The core of our approach is to formulate medical image segmentation as a rendering problem in an end-to-end manner. Specifically, we continuously align the coarse segmentation prediction with the ambiguous coordinate-based point representations and aggregate these features to adaptively refine the boundary region. To parallelly optimize multi-scale pixel-level features, we leverage the idea from Mixture-of-Expert (MoE) to design and train our MORSE with a stochastic gating mechanism. Our experiments demonstrate that MORSE can work well with different medical segmentation backbones, consistently achieving competitive performance improvements in both 2D and 3D supervised medical segmentation methods. We also theoretically analyze the superiority of MORSE.
Finding Regularized Competitive Equilibria of Heterogeneous Agent Macroeconomic Models with Reinforcement Learning
Feb 24, 2023
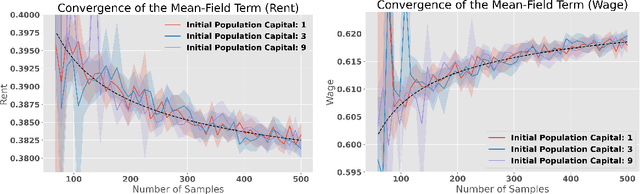
We study a heterogeneous agent macroeconomic model with an infinite number of households and firms competing in a labor market. Each household earns income and engages in consumption at each time step while aiming to maximize a concave utility subject to the underlying market conditions. The households aim to find the optimal saving strategy that maximizes their discounted cumulative utility given the market condition, while the firms determine the market conditions through maximizing corporate profit based on the household population behavior. The model captures a wide range of applications in macroeconomic studies, and we propose a data-driven reinforcement learning framework that finds the regularized competitive equilibrium of the model. The proposed algorithm enjoys theoretical guarantees in converging to the equilibrium of the market at a sub-linear rate.
Rethinking Semi-Supervised Medical Image Segmentation: A Variance-Reduction Perspective
Feb 07, 2023



For medical image segmentation, contrastive learning is the dominant practice to improve the quality of visual representations by contrasting semantically similar and dissimilar pairs of samples. This is enabled by the observation that without accessing ground truth label, negative examples with truly dissimilar anatomical features, if sampled, can significantly improve the performance. In reality, however, these samples may come from similar anatomical features and the models may struggle to distinguish the minority tail-class samples, making the tail classes more prone to misclassification, both of which typically lead to model collapse. In this paper, we propose ARCO, a semi-supervised contrastive learning (CL) framework with stratified group sampling theory in medical image segmentation. In particular, we first propose building ARCO through the concept of variance-reduced estimation, and show that certain variance-reduction techniques are particularly beneficial in medical image segmentation tasks with extremely limited labels. Furthermore, we theoretically prove these sampling techniques are universal in variance reduction. Finally, we experimentally validate our approaches on three benchmark datasets with different label settings, and our methods consistently outperform state-of-the-art semi- and fully-supervised methods. Additionally, we augment the CL frameworks with these sampling techniques and demonstrate significant gains over previous methods. We believe our work is an important step towards semi-supervised medical image segmentation by quantifying the limitation of current self-supervision objectives for accomplishing medical image analysis tasks.
A Simple and Provably Efficient Algorithm for Asynchronous Federated Contextual Linear Bandits
Jul 07, 2022

We study federated contextual linear bandits, where $M$ agents cooperate with each other to solve a global contextual linear bandit problem with the help of a central server. We consider the asynchronous setting, where all agents work independently and the communication between one agent and the server will not trigger other agents' communication. We propose a simple algorithm named \texttt{FedLinUCB} based on the principle of optimism. We prove that the regret of \texttt{FedLinUCB} is bounded by $\tilde{O}(d\sqrt{\sum_{m=1}^M T_m})$ and the communication complexity is $\tilde{O}(dM^2)$, where $d$ is the dimension of the contextual vector and $T_m$ is the total number of interactions with the environment by $m$-th agent. To the best of our knowledge, this is the first provably efficient algorithm that allows fully asynchronous communication for federated contextual linear bandits, while achieving the same regret guarantee as in the single-agent setting.
Pessimism in the Face of Confounders: Provably Efficient Offline Reinforcement Learning in Partially Observable Markov Decision Processes
May 26, 2022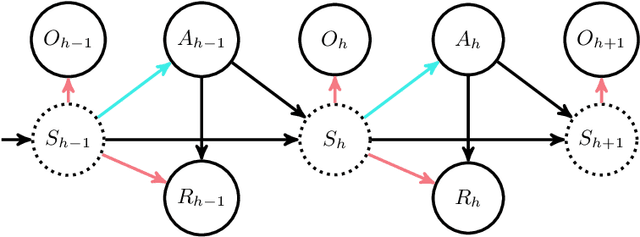
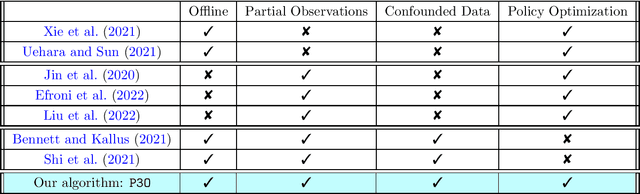
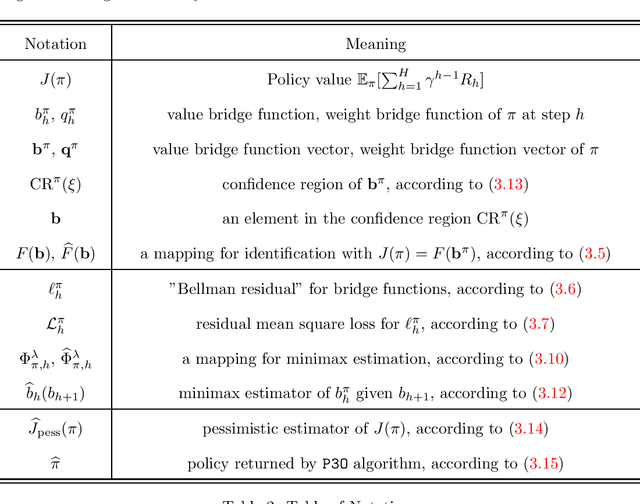
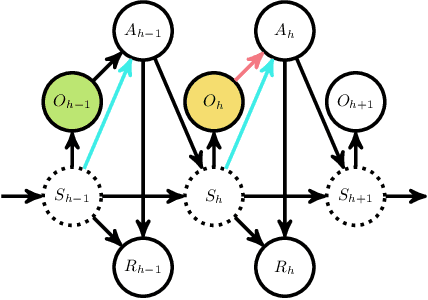
We study offline reinforcement learning (RL) in partially observable Markov decision processes. In particular, we aim to learn an optimal policy from a dataset collected by a behavior policy which possibly depends on the latent state. Such a dataset is confounded in the sense that the latent state simultaneously affects the action and the observation, which is prohibitive for existing offline RL algorithms. To this end, we propose the \underline{P}roxy variable \underline{P}essimistic \underline{P}olicy \underline{O}ptimization (\texttt{P3O}) algorithm, which addresses the confounding bias and the distributional shift between the optimal and behavior policies in the context of general function approximation. At the core of \texttt{P3O} is a coupled sequence of pessimistic confidence regions constructed via proximal causal inference, which is formulated as minimax estimation. Under a partial coverage assumption on the confounded dataset, we prove that \texttt{P3O} achieves a $n^{-1/2}$-suboptimality, where $n$ is the number of trajectories in the dataset. To our best knowledge, \texttt{P3O} is the first provably efficient offline RL algorithm for POMDPs with a confounded dataset.
Learn to Match with No Regret: Reinforcement Learning in Markov Matching Markets
Mar 07, 2022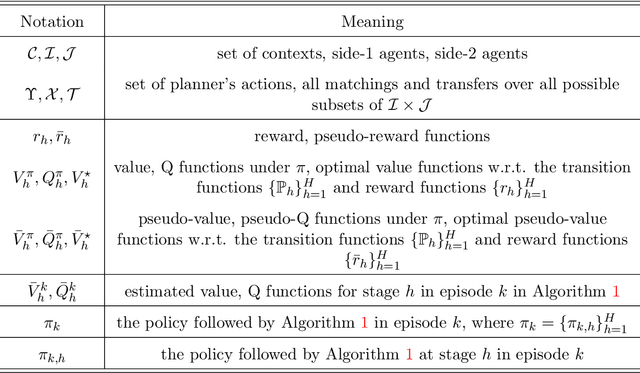
We study a Markov matching market involving a planner and a set of strategic agents on the two sides of the market. At each step, the agents are presented with a dynamical context, where the contexts determine the utilities. The planner controls the transition of the contexts to maximize the cumulative social welfare, while the agents aim to find a myopic stable matching at each step. Such a setting captures a range of applications including ridesharing platforms. We formalize the problem by proposing a reinforcement learning framework that integrates optimistic value iteration with maximum weight matching. The proposed algorithm addresses the coupled challenges of sequential exploration, matching stability, and function approximation. We prove that the algorithm achieves sublinear regret.