 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional embedding models for speaker identification and diarization with simultaneous speech from 2+ speakers
Paper and Code
Oct 22, 2020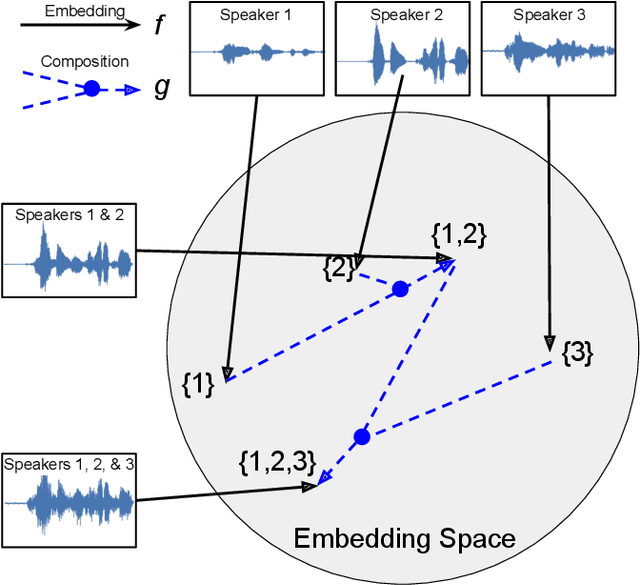
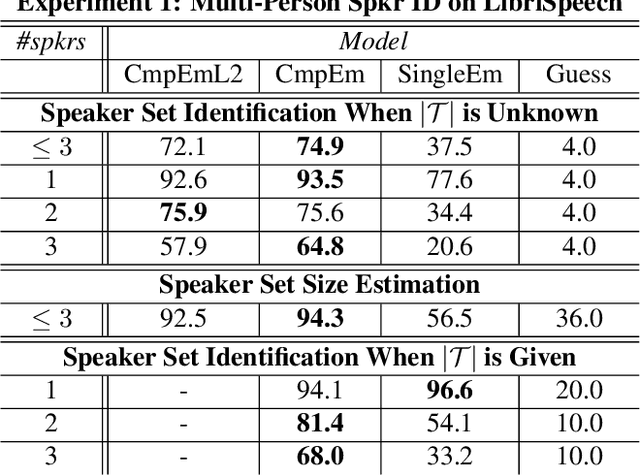

We propose a new method for speaker diarization that can handle overlapping speech with 2+ people. Our method is based on compositional embeddings [1]: Like standard speaker embedding methods such as x-vector [2], compositional embedding models contain a function f that separates speech from different speakers. In addition, they include a composition function g to compute set-union operations in the embedding space so as to infer the set of speakers within the input audio. In an experiment on multi-person speaker identification using synthesized LibriSpeech data, the proposed method outperforms traditional embedding methods that are only trained to separate single speakers (not speaker sets). In a speaker diarization experiment on the AMI Headset Mix corpus, we achieve state-of-the-art accuracy (DER=22.93%), slightly higher than the previous best result (23.82% from [3]).