 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Prompting for Low-Shot Temporal Action Localization
Paper and Code
Mar 21, 2023
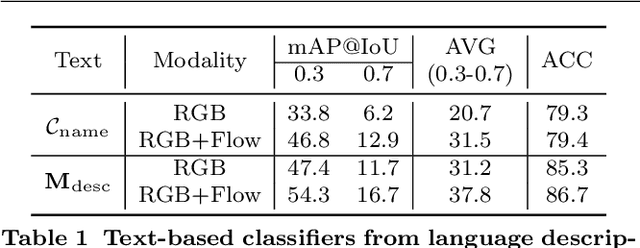
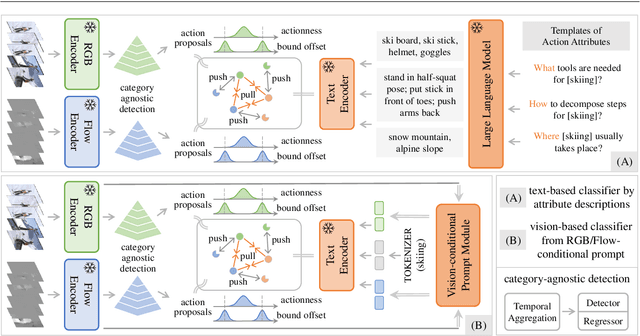
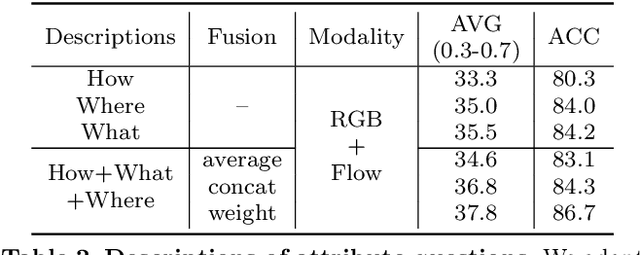
In this paper, we consider the problem of temporal action localization under low-shot (zero-shot & few-shot) scenario, with the goal of detecting and classifying the action instances from arbitrary categories within some untrimmed videos, even not seen at training time. We adopt a Transformer-based two-stage action localization architecture with class-agnostic action proposal, followed by open-vocabulary classification. We make the following contributions. First, to compensate image-text foundation models with temporal motions, we improve category-agnostic action proposal by explicitly aligning embeddings of optical flows, RGB and texts, which has largely been ignored in existing low-shot methods. Second, to improve open-vocabulary action classification, we construct classifiers with strong discriminative power, i.e., avoid lexical ambiguities. To be specific, we propose to prompt the pre-trained CLIP text encoder either with detailed action descriptions (acquired from large-scale language models), or visually-conditioned instance-specific prompt vectors. Third, we conduct thorough experiments and ablation studies on THUMOS14 and ActivityNet1.3, demonstrating the superior performance of our proposed model, outperforming existing state-of-the-art approaches by one significant margin.