 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Jun 27, 2024Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Feb 26, 2024AI alignment in the shape of Reinforcement Learning from Human Feedback (RLHF) is increasingly treated as a crucial ingredient for high performance large language models. Proximal Policy Optimization (PPO) has been positioned by recent literature as the canonical method for the RL part of RLHF. However, it involves both high computational cost and sensitive hyperparameter tuning. We posit that most of the motivational principles that led to the development of PPO are less of a practical concern in RLHF and advocate for a less computationally expensive method that preserves and even increases performance. We revisit the formulation of alignment from human preferences in the context of RL. Keeping simplicity as a guiding principle, we show that many components of PPO are unnecessary in an RLHF context and that far simpler REINFORCE-style optimization variants outperform both PPO and newly proposed "RL-free" methods such as DPO and RAFT. Our work suggests that careful adaptation to LLMs alignment characteristics enables benefiting from online RL optimization at low cost.
Inference Suboptimality in Variational Autoencoders
May 27, 2018


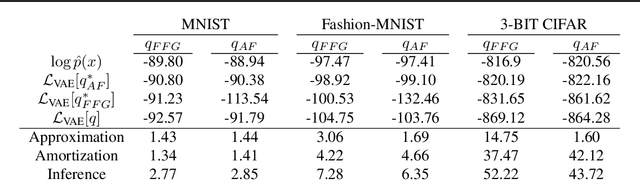
Amortized inference allows latent-variable models trained via variational learning to scale to large datasets. The quality of approximate inference is determined by two factors: a) the capacity of the variational distribution to match the true posterior and b) the ability of the recognition network to produce good variational parameters for each datapoint. We examine approximate inference in variational autoencoders in terms of these factors. We find that divergence from the true posterior is often due to imperfect recognition networks, rather than the limited complexity of the approximating distribution. We show that this is due partly to the generator learning to accommodate the choice of approximation. Furthermore, we show that the parameters used to increase the expressiveness of the approximation play a role in generalizing inference rather than simply improving the complexity of the approximation.
Reinterpreting Importance-Weighted Autoencoders
Aug 15, 2017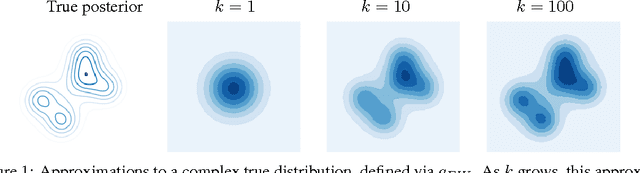
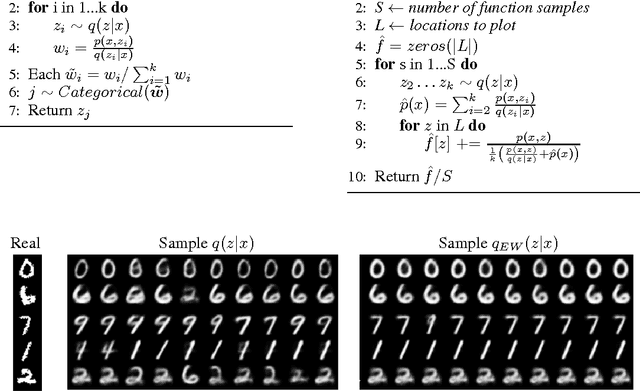
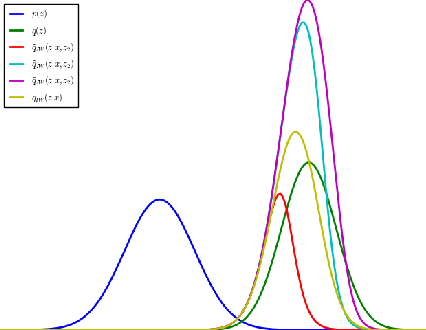
The standard interpretation of importance-weighted autoencoders is that they maximize a tighter lower bound on the marginal likelihood than the standard evidence lower bound. We give an alternate interpretation of this procedure: that it optimizes the standard variational lower bound, but using a more complex distribution. We formally derive this result, present a tighter lower bound, and visualize the implicit importance-weighted distribution.