 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tabula Rasa to Emergent Abilities: Discovering Robot Skills via Real-World Unsupervised Quality-Diversity
Aug 28, 2025Autonomous skill discovery aims to enable robots to acquire diverse behaviors without explicit supervision. Learning such behaviors directly on physical hardware remains challenging due to safety and data efficiency constraints. Existing methods, including Quality-Diversity Actor-Critic (QDAC), require manually defined skill spaces and carefully tuned heuristics, limiting real-world applicability. We propose Unsupervised Real-world Skill Acquisition (URSA), an extension of QDAC that enables robots to autonomously discover and master diverse, high-performing skills directly in the real world. We demonstrate that URSA successfully discovers diverse locomotion skills on a Unitree A1 quadruped in both simulation and the real world. Our approach supports both heuristic-driven skill discovery and fully unsupervised settings. We also show that the learned skill repertoire can be reused for downstream tasks such as real-world damage adaptation, where URSA outperforms all baselines in 5 out of 9 simulated and 3 out of 5 real-world damage scenarios. Our results establish a new framework for real-world robot learning that enables continuous skill discovery with limited human intervention, representing a significant step toward more autonomous and adaptable robotic systems. Demonstration videos are available at https://adaptive-intelligent-robotics.github.io/URSA.
Quality with Just Enough Diversity in Evolutionary Policy Search
May 07, 2024



Evolution Strategies (ES) are effective gradient-free optimization methods that can be competitive with gradient-based approaches for policy search. ES only rely on the total episodic scores of solutions in their population, from which they estimate fitness gradients for their update with no access to true gradient information. However this makes them sensitive to deceptive fitness landscapes, and they tend to only explore one way to solve a problem. Quality-Diversity methods such as MAP-Elites introduced additional information with behavior descriptors (BD) to return a population of diverse solutions, which helps exploration but leads to a large part of the evaluation budget not being focused on finding the best performing solution. Here we show that behavior information can also be leveraged to find the best policy by identifying promising search areas which can then be efficiently explored with ES. We introduce the framework of Quality with Just Enough Diversity (JEDi) which learns the relationship between behavior and fitness to focus evaluations on solutions that matter. When trying to reach higher fitness values, JEDi outperforms both QD and ES methods on hard exploration tasks like mazes and on complex control problems with large policies.
Quality-Diversity Actor-Critic: Learning High-Performing and Diverse Behaviors via Value and Successor Features Critics
Mar 15, 2024A key aspect of intelligence is the ability to demonstrate a broad spectrum of behaviors for adapting to unexpected situations. Over the past decade, advancements in deep reinforcement learning have led to groundbreaking achievements to solve complex continuous control tasks. However, most approaches return only one solution specialized for a specific problem. We introduce Quality-Diversity Actor-Critic (QDAC), an off-policy actor-critic deep reinforcement learning algorithm that leverages a value function critic and a successor features critic to learn high-performing and diverse behaviors. In this framework, the actor optimizes an objective that seamlessly unifies both critics using constrained optimization to (1) maximize return, while (2) executing diverse skills. Compared with other Quality-Diversity methods, QDAC achieves significantly higher performance and more diverse behaviors on six challenging continuous control locomotion tasks. We also demonstrate that we can harness the learned skills to adapt better than other baselines to five perturbed environments. Finally, qualitative analyses showcase a range of remarkable behaviors, available at: http://bit.ly/qdac.
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
Benchmark tasks for Quality-Diversity applied to Uncertain domains
Apr 26, 2023While standard approaches to optimisation focus on producing a single high-performing solution, Quality-Diversity (QD) algorithms allow large diverse collections of such solutions to be found. If QD has proven promising across a large variety of domains, it still struggles when faced with uncertain domains, where quantification of performance and diversity are non-deterministic. Previous work in Uncertain Quality-Diversity (UQD) has proposed methods and metrics designed for such uncertain domains. In this paper, we propose a first set of benchmark tasks to analyse and estimate the performance of UQD algorithms. We identify the key uncertainty properties to easily define UQD benchmark tasks: the uncertainty location, the type of distribution and its parameters. By varying the nature of those key UQD components, we introduce a set of 8 easy-to-implement and lightweight tasks, split into 3 main categories. All our tasks build on the Redundant Arm: a common QD environment that is lightweight and easily replicable. Each one of these tasks highlights one specific limitation that arises when considering UQD domains. With this first benchmark, we hope to facilitate later advances in UQD.
Don't Bet on Luck Alone: Enhancing Behavioral Reproducibility of Quality-Diversity Solutions in Uncertain Domains
Apr 07, 2023

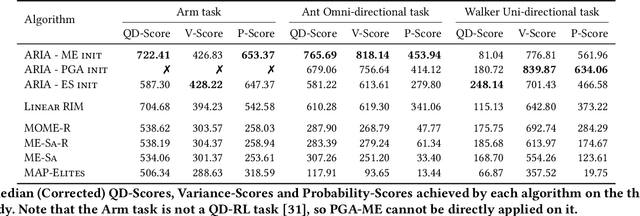
Quality-Diversity (QD) algorithms are designed to generate collections of high-performing solutions while maximizing their diversity in a given descriptor space. However, in the presence of unpredictable noise, the fitness and descriptor of the same solution can differ significantly from one evaluation to another, leading to uncertainty in the estimation of such values. Given the elitist nature of QD algorithms, they commonly end up with many degenerate solutions in such noisy settings. In this work, we introduce Archive Reproducibility Improvement Algorithm (ARIA); a plug-and-play approach that improves the reproducibility of the solutions present in an archive. We propose it as a separate optimization module, relying on natural evolution strategies, that can be executed on top of any QD algorithm. Our module mutates solutions to (1) optimize their probability of belonging to their niche, and (2) maximize their fitness. The performance of our method is evaluated on various tasks, including a classical optimization problem and two high-dimensional control tasks in simulated robotic environments. We show that our algorithm enhances the quality and descriptor space coverage of any given archive by at least 50%.
Discovering Unsupervised Behaviours from Full-State Trajectories
Nov 22, 2022


Improving open-ended learning capabilities is a promising approach to enable robots to face the unbounded complexity of the real-world. Among existing methods, the ability of Quality-Diversity algorithms to generate large collections of diverse and high-performing skills is instrumental in this context. However, most of those algorithms rely on a hand-coded behavioural descriptor to characterise the diversity, hence requiring prior knowledge about the considered tasks. In this work, we propose an additional analysis of Autonomous Robots Realising their Abilities; a Quality-Diversity algorithm that autonomously finds behavioural characterisations. We evaluate this approach on a simulated robotic environment, where the robot has to autonomously discover its abilities from its full-state trajectories. All algorithms were applied to three tasks: navigation, moving forward with a high velocity, and performing half-rolls. The experimental results show that the algorithm under study discovers autonomously collections of solutions that are diverse with respect to all tasks. More specifically, the analysed approach autonomously finds policies that make the robot move to diverse positions, but also utilise its legs in diverse ways, and even perform half-rolls.
Benchmarking Quality-Diversity Algorithms on Neuroevolution for Reinforcement Learning
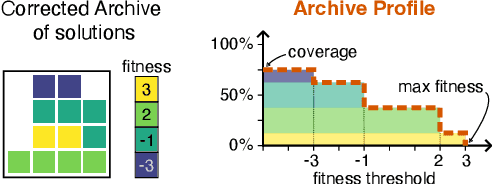
Nov 04, 2022We present a Quality-Diversity benchmark suite for Deep Neuroevolution in Reinforcement Learning domains for robot control. The suite includes the definition of tasks, environments, behavioral descriptors, and fitness. We specify different benchmarks based on the complexity of both the task and the agent controlled by a deep neural network. The benchmark uses standard Quality-Diversity metrics, including coverage, QD-score, maximum fitness, and an archive profile metric to quantify the relation between coverage and fitness. We also present how to quantify the robustness of the solutions with respect to environmental stochasticity by introducing corrected versions of the same metrics. We believe that our benchmark is a valuable tool for the community to compare and improve their findings. The source code is available online: https://github.com/adaptive-intelligent-robotics/QDax
Relevance-guided Unsupervised Discovery of Abilities with Quality-Diversity Algorithms
Apr 21, 2022


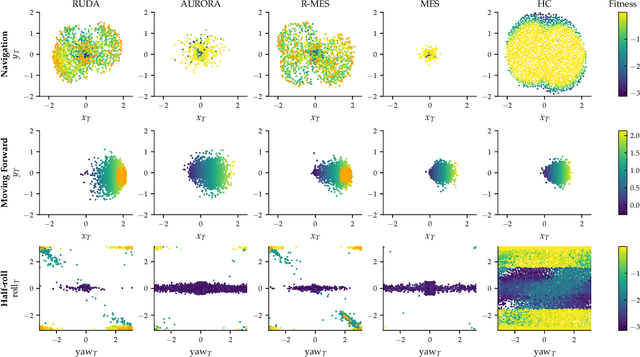
Quality-Diversity algorithms provide efficient mechanisms to generate large collections of diverse and high-performing solutions, which have shown to be instrumental for solving downstream tasks. However, most of those algorithms rely on a behavioural descriptor to characterise the diversity that is hand-coded, hence requiring prior knowledge about the considered tasks. In this work, we introduce Relevance-guided Unsupervised Discovery of Abilities; a Quality-Diversity algorithm that autonomously finds a behavioural characterisation tailored to the task at hand. In particular, our method introduces a custom diversity metric that leads to higher densities of solutions near the areas of interest in the learnt behavioural descriptor space. We evaluate our approach on a simulated robotic environment, where the robot has to autonomously discover its abilities based on its full sensory data. We evaluated the algorithms on three tasks: navigation to random targets, moving forward with a high velocity, and performing half-rolls. The experimental results show that our method manages to discover collections of solutions that are not only diverse, but also well-adapted to the considered downstream task.
Accelerated Quality-Diversity for Robotics through Massive Parallelism
Feb 02, 2022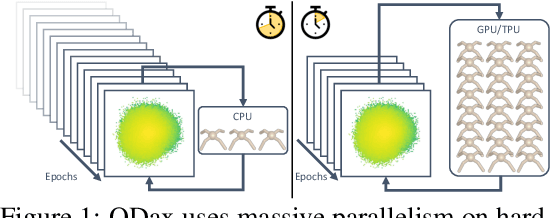
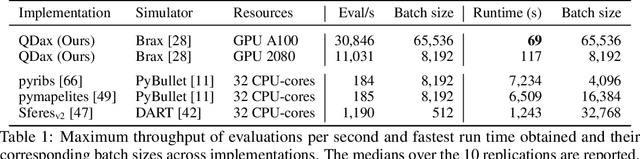
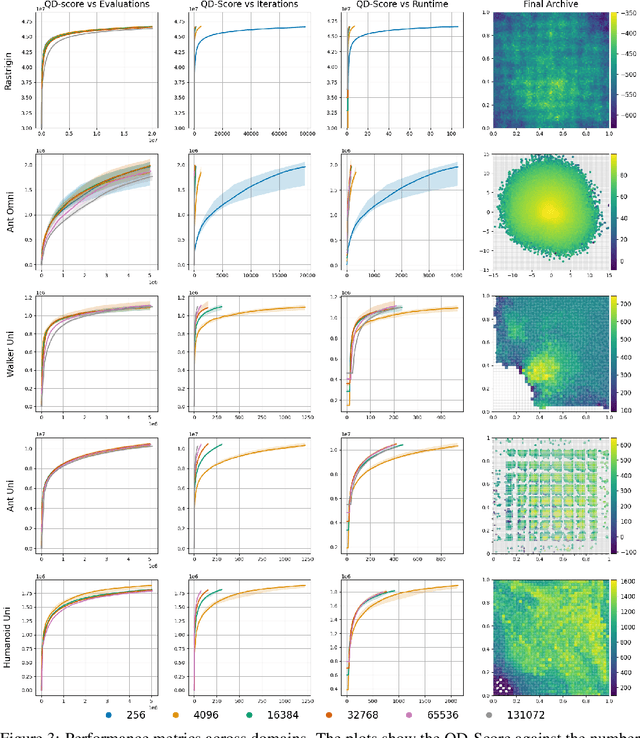
Quality-Diversity (QD) algorithms are a well-known approach to generate large collections of diverse and high-quality policies. However, QD algorithms are also known to be data-inefficient, requiring large amounts of computational resources and are slow when used in practice for robotics tasks. Policy evaluations are already commonly performed in parallel to speed up QD algorithms but have limited capabilities on a single machine as most physics simulators run on CPUs. With recent advances in simulators that run on accelerators, thousands of evaluations can performed in parallel on single GPU/TPU. In this paper, we present QDax, an implementation of MAP-Elites which leverages massive parallelism on accelerators to make QD algorithms more accessible. We first demonstrate the improvements on the number of evaluations per second that parallelism using accelerated simulators can offer. More importantly, we show that QD algorithms are ideal candidates and can scale with massive parallelism to be run at interactive timescales. The increase in parallelism does not significantly affect the performance of QD algorithms, while reducing experiment runtimes by two factors of magnitudes, turning days of computation into minutes. These results show that QD can now benefit from hardware acceleration, which contributed significantly to the bloom of deep learning.