 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Diversity Actor-Critic: Learning High-Performing and Diverse Behaviors via Value and Successor Features Critics
Mar 15, 2024



A key aspect of intelligence is the ability to demonstrate a broad spectrum of behaviors for adapting to unexpected situations. Over the past decade, advancements in deep reinforcement learning have led to groundbreaking achievements to solve complex continuous control tasks. However, most approaches return only one solution specialized for a specific problem. We introduce Quality-Diversity Actor-Critic (QDAC), an off-policy actor-critic deep reinforcement learning algorithm that leverages a value function critic and a successor features critic to learn high-performing and diverse behaviors. In this framework, the actor optimizes an objective that seamlessly unifies both critics using constrained optimization to (1) maximize return, while (2) executing diverse skills. Compared with other Quality-Diversity methods, QDAC achieves significantly higher performance and more diverse behaviors on six challenging continuous control locomotion tasks. We also demonstrate that we can harness the learned skills to adapt better than other baselines to five perturbed environments. Finally, qualitative analyses showcase a range of remarkable behaviors, available at: http://bit.ly/qdac.
In a Nutshell, the Human Asked for This: Latent Goals for Following Temporal Specifications
Oct 18, 2021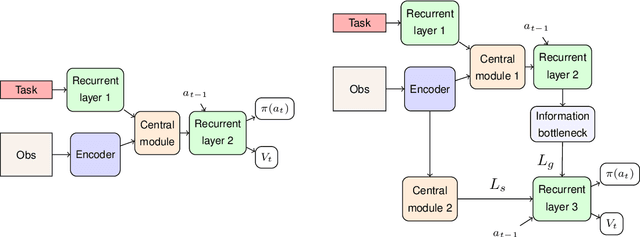
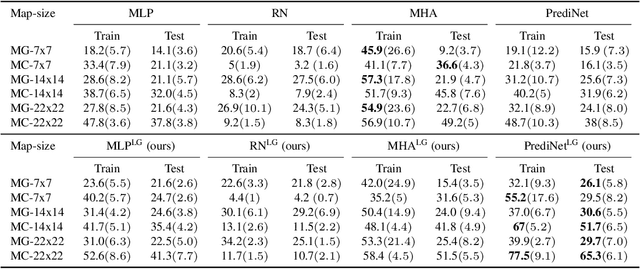
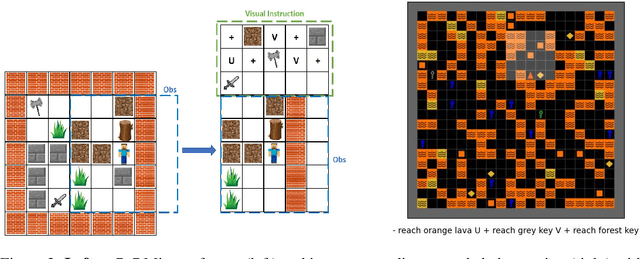
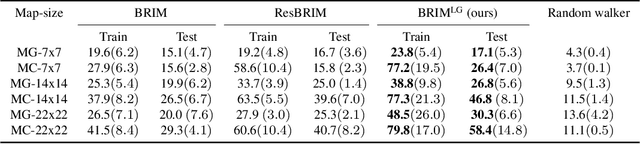
We address the problem of building agents whose goal is to satisfy out-of distribution (OOD) multi-task instructions expressed in temporal logic (TL) by using deep reinforcement learning (DRL). Recent works provided evidence that the deep learning architecture is a key feature when teaching a DRL agent to solve OOD tasks in TL. Yet, the studies on their performance are still limited. In this work, we analyse various state-of-the-art (SOTA) architectures that include generalisation mechanisms such as relational layers, the soft-attention mechanism, or hierarchical configurations, when generalising safety-aware tasks expressed in TL. Most importantly, we present a novel deep learning architecture that induces agents to generate latent representations of their current goal given both the human instruction and the current observation from the environment. We find that applying our proposed configuration to SOTA architectures yields significantly stronger performance when executing new tasks in OOD environments.
An Abstraction-based Method to Verify Multi-Agent Deep Reinforcement-Learning Behaviours
Feb 02, 2021
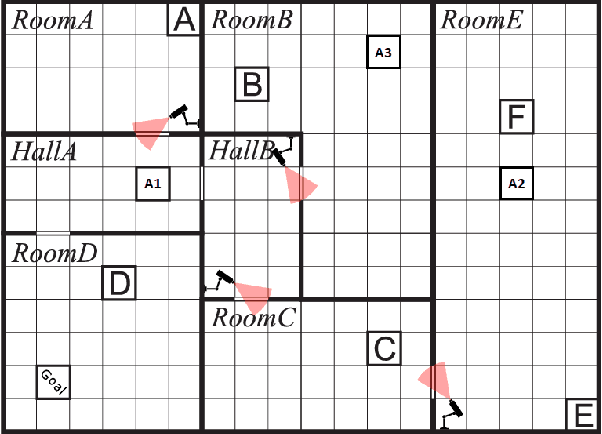
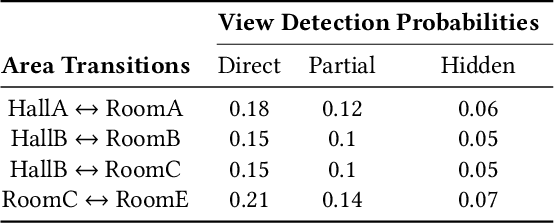
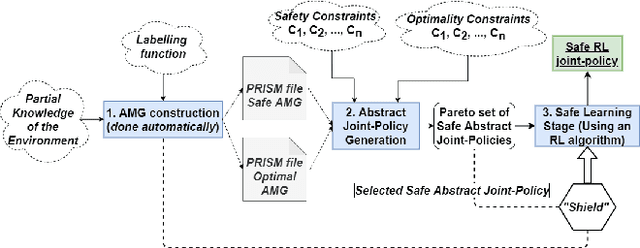
Multi-agent reinforcement learning (RL) often struggles to ensure the safe behaviours of the learning agents, and therefore it is generally not adapted to safety-critical applications. To address this issue, we present a methodology that combines formal verification with (deep) RL algorithms to guarantee the satisfaction of formally-specified safety constraints both in training and testing. The approach we propose expresses the constraints to verify in Probabilistic Computation Tree Logic (PCTL) and builds an abstract representation of the system to reduce the complexity of the verification step. This abstract model allows for model checking techniques to identify a set of abstract policies that meet the safety constraints expressed in PCTL. Then, the agents' behaviours are restricted according to these safe abstract policies. We provide formal guarantees that by using this method, the actions of the agents always meet the safety constraints, and provide a procedure to generate an abstract model automatically. We empirically evaluate and show the effectiveness of our method in a multi-agent environment.
Extended Markov Games to Learn Multiple Tasks in Multi-Agent Reinforcement Learning
Feb 14, 2020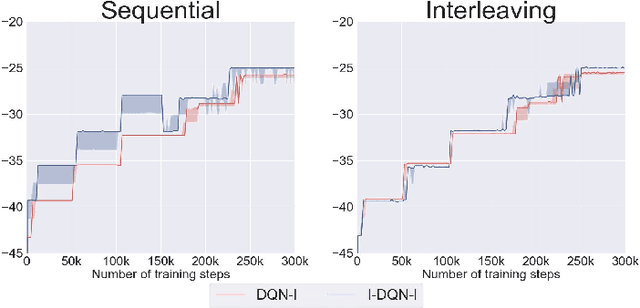
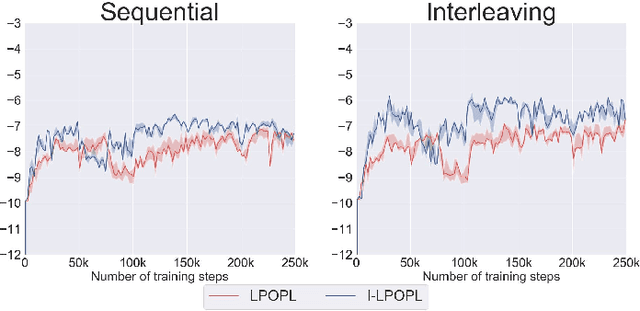
The combination of Formal Methods with Reinforcement Learning (RL) has recently attracted interest as a way for single-agent RL to learn multiple-task specifications. In this paper we extend this convergence to multi-agent settings and formally define Extended Markov Games as a general mathematical model that allows multiple RL agents to concurrently learn various non-Markovian specifications. To introduce this new model we provide formal definitions and proofs as well as empirical tests of RL algorithms running on this framework. Specifically, we use our model to train two different logic-based multi-agent RL algorithms to solve diverse settings of non-Markovian co-safe LTL specifications.