Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Markov Games to Learn Multiple Tasks in Multi-Agent Reinforcement Learning
Paper and Code
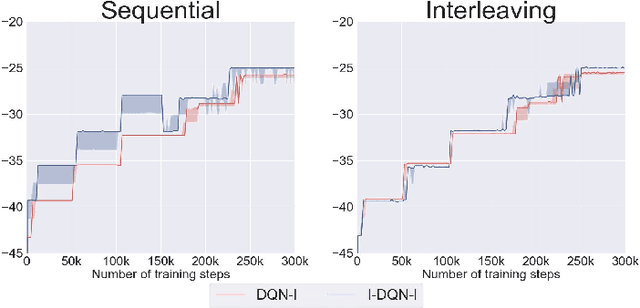
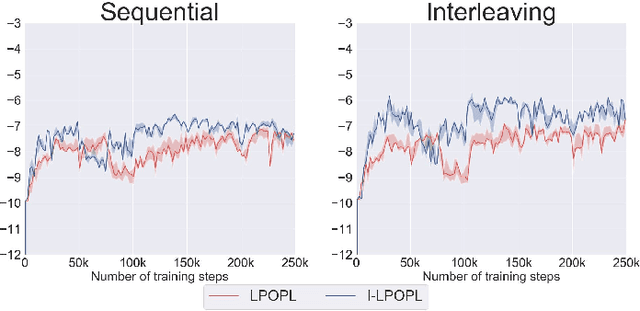
The combination of Formal Methods with Reinforcement Learning (RL) has recently attracted interest as a way for single-agent RL to learn multiple-task specifications. In this paper we extend this convergence to multi-agent settings and formally define Extended Markov Games as a general mathematical model that allows multiple RL agents to concurrently learn various non-Markovian specifications. To introduce this new model we provide formal definitions and proofs as well as empirical tests of RL algorithms running on this framework. Specifically, we use our model to train two different logic-based multi-agent RL algorithms to solve diverse settings of non-Markovian co-safe LTL specifications.
* Long version of the correspondent ECAI 2020 paper
View paper on