 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvents as Triggers for Behavioral Diversity in Multi-Agent Reinforcement Learning
May 13, 2026Effective multi-agent cooperation requires agents to adopt diverse behaviors as task conditions evolve-and to do so at the right moment. Yet, current Multi-Agent Reinforcement Learning (MARL) frameworks that facilitate this diversity are still limited by the fact that they bind fixed behaviors to fixed agent identities. Consequently, they are ill-equipped for tasks where agents need to take on different roles at very specific moments in time. We argue that, to define these behavioral transitions, the missing ingredient is $\textbf{events}$. Events are changes in the state of the system that induce qualitative changes in the task. Based on this view, we introduce a framework that decouples agent identity from behavior, capturing a continuous manifold from which agents instantiate their behaviors in response to events. This framework is based on two elements. First, to build an expressive behavior manifold, we introduce Neural Manifold Diversity (NMD), a formal distance metric that remains well-defined when behaviors are transient and agent-agnostic. Second, we use an event-based hypernetwork that generates Low-Rank Adaptation (LoRA) modules over a shared team policy, enabling on-the-fly agent-policy reconfiguration in response to events. We prove that this construction ensures that diversity does not interfere with reward maximization by design. Empirical results demonstrate that our framework outperforms established baselines across benchmarks while exhibiting zero-shot generalization, and being the only method that solves tasks requiring sequential behavior reassignment.
Remotely Detectable Robot Policy Watermarking
Dec 17, 2025The success of machine learning for real-world robotic systems has created a new form of intellectual property: the trained policy. This raises a critical need for novel methods that verify ownership and detect unauthorized, possibly unsafe misuse. While watermarking is established in other domains, physical policies present a unique challenge: remote detection. Existing methods assume access to the robot's internal state, but auditors are often limited to external observations (e.g., video footage). This ``Physical Observation Gap'' means the watermark must be detected from signals that are noisy, asynchronous, and filtered by unknown system dynamics. We formalize this challenge using the concept of a \textit{glimpse sequence}, and introduce Colored Noise Coherency (CoNoCo), the first watermarking strategy designed for remote detection. CoNoCo embeds a spectral signal into the robot's motions by leveraging the policy's inherent stochasticity. To show it does not degrade performance, we prove CoNoCo preserves the marginal action distribution. Our experiments demonstrate strong, robust detection across various remote modalities, including motion capture and side-way/top-down video footage, in both simulated and real-world robot experiments. This work provides a necessary step toward protecting intellectual property in robotics, offering the first method for validating the provenance of physical policies non-invasively, using purely remote observations.
Extract-QD Framework: A Generic Approach for Quality-Diversity in Noisy, Stochastic or Uncertain Domains
Feb 10, 2025



Quality-Diversity (QD) has demonstrated potential in discovering collections of diverse solutions to optimisation problems. Originally designed for deterministic environments, QD has been extended to noisy, stochastic, or uncertain domains through various Uncertain-QD (UQD) methods. However, the large number of UQD methods, each with unique constraints, makes selecting the most suitable one challenging. To remedy this situation, we present two contributions: first, the Extract-QD Framework (EQD Framework), and second, Extract-ME (EME), a new method derived from it. The EQD Framework unifies existing approaches within a modular view, and facilitates developing novel methods by interchanging modules. We use it to derive EME, a novel method that consistently outperforms or matches the best existing methods on standard benchmarks, while previous methods show varying performance. In a second experiment, we show how our EQD Framework can be used to augment existing QD algorithms and in particular the well-established Policy-Gradient-Assisted-MAP-Elites method, and demonstrate improved performance in uncertain domains at no additional evaluation cost. For any new uncertain task, our contributions now provide EME as a reliable "first guess" method, and the EQD Framework as a tool for developing task-specific approaches. Together, these contributions aim to lower the cost of adopting UQD insights in QD applications.
Large Language Models as In-context AI Generators for Quality-Diversity
Apr 24, 2024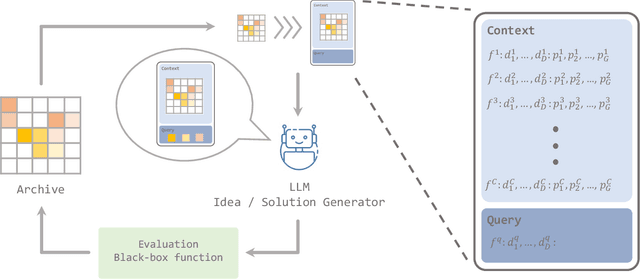
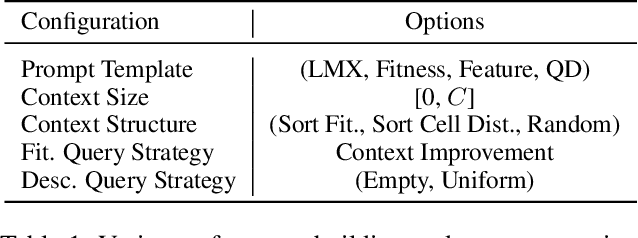
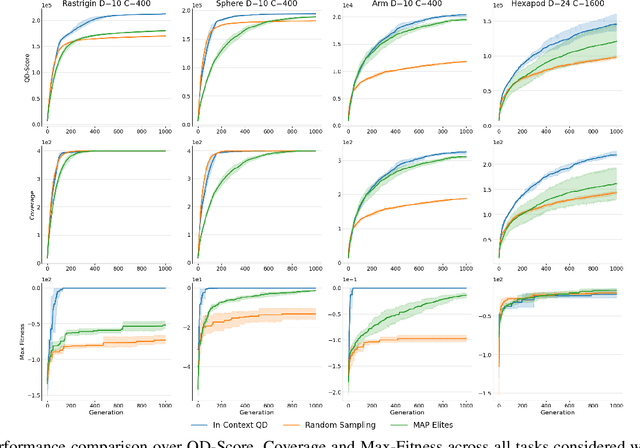

Quality-Diversity (QD) approaches are a promising direction to develop open-ended processes as they can discover archives of high-quality solutions across diverse niches. While already successful in many applications, QD approaches usually rely on combining only one or two solutions to generate new candidate solutions. As observed in open-ended processes such as technological evolution, wisely combining large diversity of these solutions could lead to more innovative solutions and potentially boost the productivity of QD search. In this work, we propose to exploit the pattern-matching capabilities of generative models to enable such efficient solution combinations. We introduce In-context QD, a framework of techniques that aim to elicit the in-context capabilities of pre-trained Large Language Models (LLMs) to generate interesting solutions using the QD archive as context. Applied to a series of common QD domains, In-context QD displays promising results compared to both QD baselines and similar strategies developed for single-objective optimization. Additionally, this result holds across multiple values of parameter sizes and archive population sizes, as well as across domains with distinct characteristics from BBO functions to policy search. Finally, we perform an extensive ablation that highlights the key prompt design considerations that encourage the generation of promising solutions for QD.
Beyond Expected Return: Accounting for Policy Reproducibility when Evaluating Reinforcement Learning Algorithms
Dec 12, 2023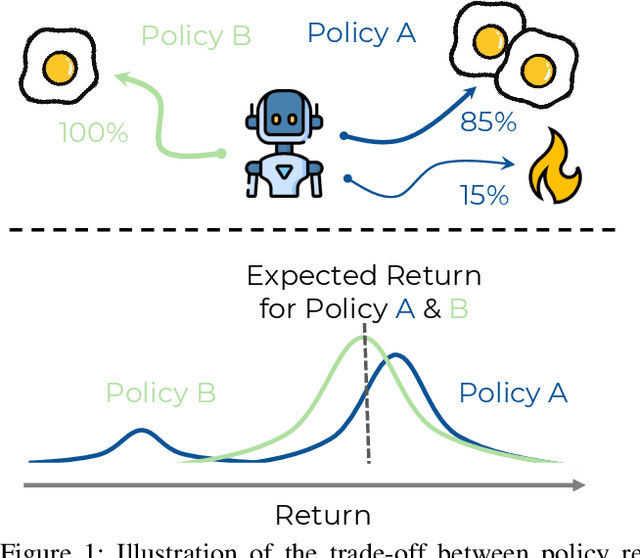



Many applications in Reinforcement Learning (RL) usually have noise or stochasticity present in the environment. Beyond their impact on learning, these uncertainties lead the exact same policy to perform differently, i.e. yield different return, from one roll-out to another. Common evaluation procedures in RL summarise the consequent return distributions using solely the expected return, which does not account for the spread of the distribution. Our work defines this spread as the policy reproducibility: the ability of a policy to obtain similar performance when rolled out many times, a crucial property in some real-world applications. We highlight that existing procedures that only use the expected return are limited on two fronts: first an infinite number of return distributions with a wide range of performance-reproducibility trade-offs can have the same expected return, limiting its effectiveness when used for comparing policies; second, the expected return metric does not leave any room for practitioners to choose the best trade-off value for considered applications. In this work, we address these limitations by recommending the use of Lower Confidence Bound, a metric taken from Bayesian optimisation that provides the user with a preference parameter to choose a desired performance-reproducibility trade-off. We also formalise and quantify policy reproducibility, and demonstrate the benefit of our metrics using extensive experiments of popular RL algorithms on common uncertain RL tasks.
Mix-ME: Quality-Diversity for Multi-Agent Learning
Nov 03, 2023



In many real-world systems, such as adaptive robotics, achieving a single, optimised solution may be insufficient. Instead, a diverse set of high-performing solutions is often required to adapt to varying contexts and requirements. This is the realm of Quality-Diversity (QD), which aims to discover a collection of high-performing solutions, each with their own unique characteristics. QD methods have recently seen success in many domains, including robotics, where they have been used to discover damage-adaptive locomotion controllers. However, most existing work has focused on single-agent settings, despite many tasks of interest being multi-agent. To this end, we introduce Mix-ME, a novel multi-agent variant of the popular MAP-Elites algorithm that forms new solutions using a crossover-like operator by mixing together agents from different teams. We evaluate the proposed methods on a variety of partially observable continuous control tasks. Our evaluation shows that these multi-agent variants obtained by Mix-ME not only compete with single-agent baselines but also often outperform them in multi-agent settings under partial observability.
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
Benchmark tasks for Quality-Diversity applied to Uncertain domains
Apr 26, 2023While standard approaches to optimisation focus on producing a single high-performing solution, Quality-Diversity (QD) algorithms allow large diverse collections of such solutions to be found. If QD has proven promising across a large variety of domains, it still struggles when faced with uncertain domains, where quantification of performance and diversity are non-deterministic. Previous work in Uncertain Quality-Diversity (UQD) has proposed methods and metrics designed for such uncertain domains. In this paper, we propose a first set of benchmark tasks to analyse and estimate the performance of UQD algorithms. We identify the key uncertainty properties to easily define UQD benchmark tasks: the uncertainty location, the type of distribution and its parameters. By varying the nature of those key UQD components, we introduce a set of 8 easy-to-implement and lightweight tasks, split into 3 main categories. All our tasks build on the Redundant Arm: a common QD environment that is lightweight and easily replicable. Each one of these tasks highlights one specific limitation that arises when considering UQD domains. With this first benchmark, we hope to facilitate later advances in UQD.
Don't Bet on Luck Alone: Enhancing Behavioral Reproducibility of Quality-Diversity Solutions in Uncertain Domains
Apr 07, 2023

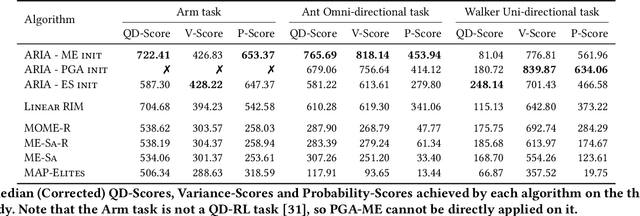
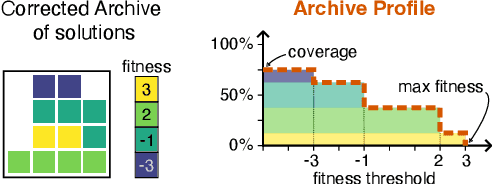
Quality-Diversity (QD) algorithms are designed to generate collections of high-performing solutions while maximizing their diversity in a given descriptor space. However, in the presence of unpredictable noise, the fitness and descriptor of the same solution can differ significantly from one evaluation to another, leading to uncertainty in the estimation of such values. Given the elitist nature of QD algorithms, they commonly end up with many degenerate solutions in such noisy settings. In this work, we introduce Archive Reproducibility Improvement Algorithm (ARIA); a plug-and-play approach that improves the reproducibility of the solutions present in an archive. We propose it as a separate optimization module, relying on natural evolution strategies, that can be executed on top of any QD algorithm. Our module mutates solutions to (1) optimize their probability of belonging to their niche, and (2) maximize their fitness. The performance of our method is evaluated on various tasks, including a classical optimization problem and two high-dimensional control tasks in simulated robotic environments. We show that our algorithm enhances the quality and descriptor space coverage of any given archive by at least 50%.
Multiple Hands Make Light Work: Enhancing Quality and Diversity using MAP-Elites with Multiple Parallel Evolution Strategies
Mar 10, 2023



With the development of hardware accelerators and their corresponding tools, evaluations have become more affordable through fast and massively parallel evaluations in some applications. This advancement has drastically sped up the runtime of evolution-inspired algorithms such as Quality-Diversity optimization, creating tremendous potential for algorithmic innovation through scale. In this work, we propose MAP-Elites-Multi-ES (MEMES), a novel QD algorithm based on Evolution Strategies (ES) designed for fast parallel evaluations. ME-Multi-ES builds on top of the existing MAP-Elites-ES algorithm, scaling it by maintaining multiple independent ES threads with massive parallelization. We also introduce a new dynamic reset procedure for the lifespan of the independent ES to autonomously maximize the improvement of the QD population. We show experimentally that MEMES outperforms existing gradient-based and objective-agnostic QD algorithms when compared in terms of generations. We perform this comparison on both black-box optimization and QD-Reinforcement Learning tasks, demonstrating the benefit of our approach across different problems and domains. Finally, we also find that our approach intrinsically enables optimization of fitness locally around a niche, a phenomenon not observed in other QD algorithms.