 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP-Elites with Descriptor-Conditioned Gradients and Archive Distillation into a Single Policy
Paper and Code
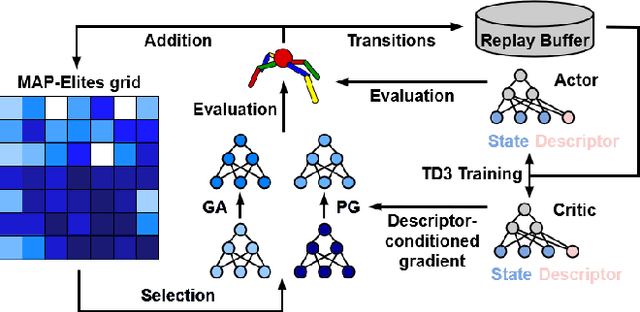
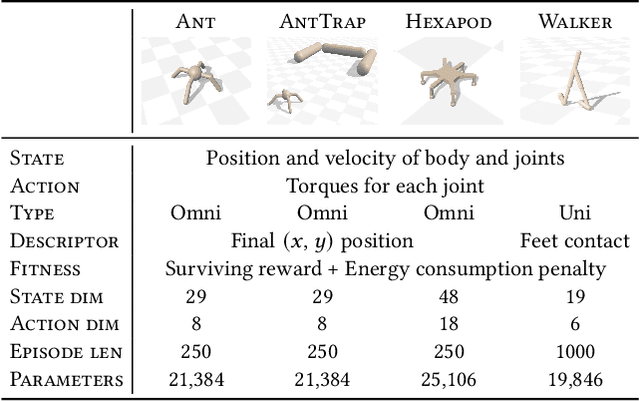
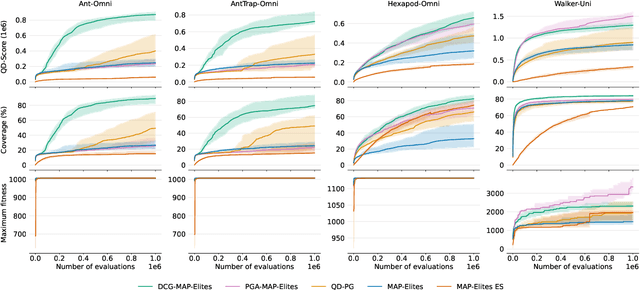
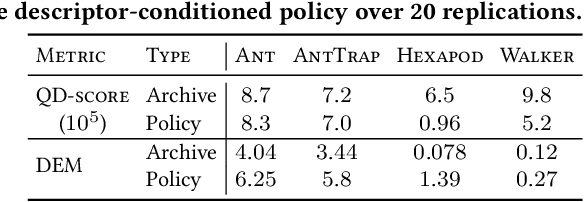
Quality-Diversity algorithms, such as MAP-Elites, are a branch of Evolutionary Computation generating collections of diverse and high-performing solutions, that have been successfully applied to a variety of domains and particularly in evolutionary robotics. However, MAP-Elites performs a divergent search based on random mutations originating from Genetic Algorithms, and thus, is limited to evolving populations of low-dimensional solutions. PGA-MAP-Elites overcomes this limitation by integrating a gradient-based variation operator inspired by Deep Reinforcement Learning which enables the evolution of large neural networks. Although high-performing in many environments, PGA-MAP-Elites fails on several tasks where the convergent search of the gradient-based operator does not direct mutations towards archive-improving solutions. In this work, we present two contributions: (1) we enhance the Policy Gradient variation operator with a descriptor-conditioned critic that improves the archive across the entire descriptor space, (2) we exploit the actor-critic training to learn a descriptor-conditioned policy at no additional cost, distilling the knowledge of the archive into one single versatile policy that can execute the entire range of behaviors contained in the archive. Our algorithm, DCG-MAP-Elites improves the QD score over PGA-MAP-Elites by 82% on average, on a set of challenging locomotion tasks.