 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Conditioned Gradient Variations for Multi-Objective Quality-Diversity
Paper and Code
Nov 19, 2024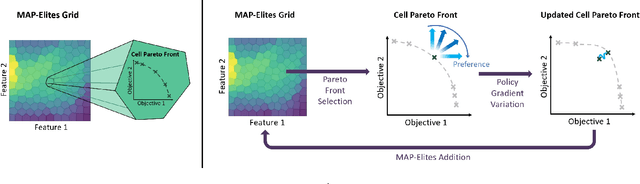
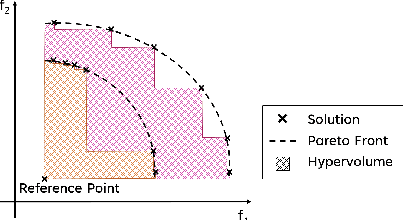
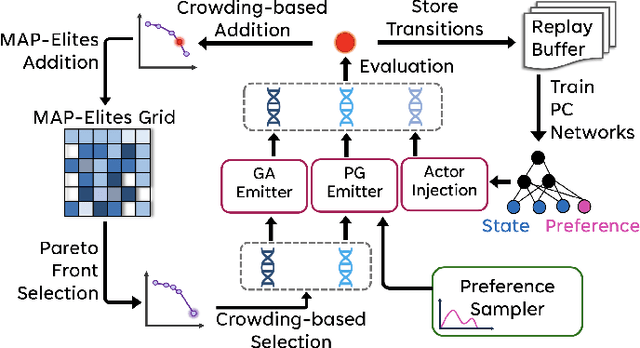
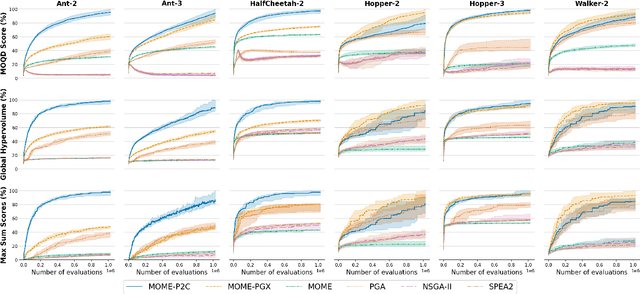
In a variety of domains, from robotics to finance, Quality-Diversity algorithms have been used to generate collections of both diverse and high-performing solutions. Multi-Objective Quality-Diversity algorithms have emerged as a promising approach for applying these methods to complex, multi-objective problems. However, existing methods are limited by their search capabilities. For example, Multi-Objective Map-Elites depends on random genetic variations which struggle in high-dimensional search spaces. Despite efforts to enhance search efficiency with gradient-based mutation operators, existing approaches consider updating solutions to improve on each objective separately rather than achieving desired trade-offs. In this work, we address this limitation by introducing Multi-Objective Map-Elites with Preference-Conditioned Policy-Gradient and Crowding Mechanisms: a new Multi-Objective Quality-Diversity algorithm that uses preference-conditioned policy-gradient mutations to efficiently discover promising regions of the objective space and crowding mechanisms to promote a uniform distribution of solutions on the Pareto front. We evaluate our approach on six robotics locomotion tasks and show that our method outperforms or matches all state-of-the-art Multi-Objective Quality-Diversity methods in all six, including two newly proposed tri-objective tasks. Importantly, our method also achieves a smoother set of trade-offs, as measured by newly-proposed sparsity-based metrics. This performance comes at a lower computational storage cost compared to previous methods.