 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanacea: Novel DNN Accelerator using Accuracy-Preserving Asymmetric Quantization and Energy-Saving Bit-Slice Sparsity
Dec 13, 2024Low bit-precisions and their bit-slice sparsity have recently been studied to accelerate general matrix-multiplications (GEMM) during large-scale deep neural network (DNN) inferences. While the conventional symmetric quantization facilitates low-resolution processing with bit-slice sparsity for both weight and activation, its accuracy loss caused by the activation's asymmetric distributions cannot be acceptable, especially for large-scale DNNs. In efforts to mitigate this accuracy loss, recent studies have actively utilized asymmetric quantization for activations without requiring additional operations. However, the cutting-edge asymmetric quantization produces numerous nonzero slices that cannot be compressed and skipped by recent bit-slice GEMM accelerators, naturally consuming more processing energy to handle the quantized DNN models. To simultaneously achieve high accuracy and hardware efficiency for large-scale DNN inferences, this paper proposes an Asymmetrically-Quantized bit-Slice GEMM (AQS-GEMM) for the first time. In contrast to the previous bit-slice computing, which only skips operations of zero slices, the AQS-GEMM compresses frequent nonzero slices, generated by asymmetric quantization, and skips their operations. To increase the slice-level sparsity of activations, we also introduce two algorithm-hardware co-optimization methods: a zero-point manipulation and a distribution-based bit-slicing. To support the proposed AQS-GEMM and optimizations at the hardware-level, we newly introduce a DNN accelerator, Panacea, which efficiently handles sparse/dense workloads of the tiled AQS-GEMM to increase data reuse and utilization. Panacea supports a specialized dataflow and run-length encoding to maximize data reuse and minimize external memory accesses, significantly improving its hardware efficiency. Our benchmark evaluations show Panacea outperforms existing DNN accelerators.
GROW: A Row-Stationary Sparse-Dense GEMM Accelerator for Memory-Efficient Graph Convolutional Neural Networks
Mar 02, 2022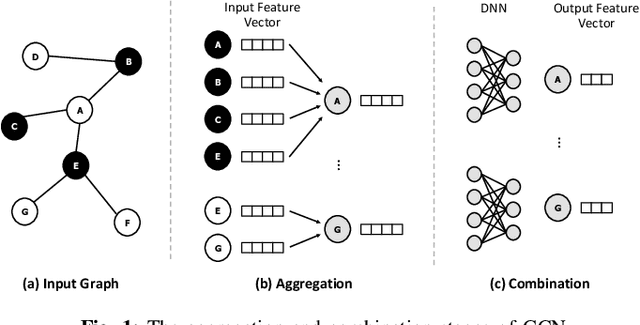
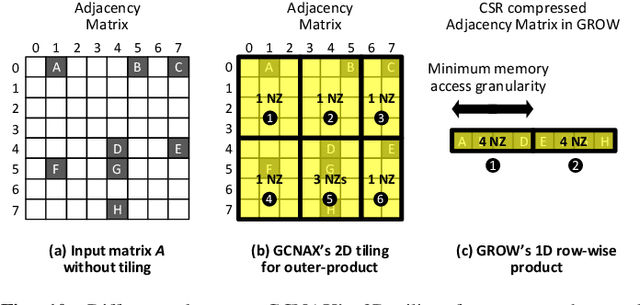
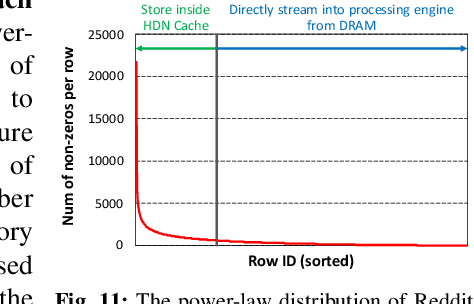
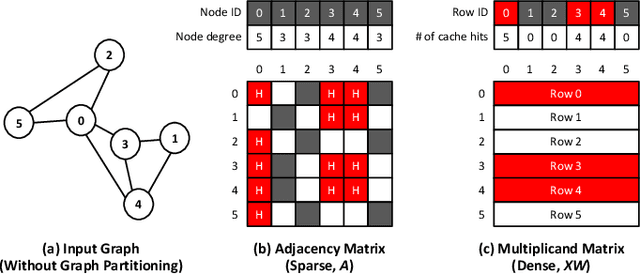
Graph convolutional neural networks (GCNs) have emerged as a key technology in various application domains where the input data is relational. A unique property of GCNs is that its two primary execution stages, aggregation and combination, exhibit drastically different dataflows. Consequently, prior GCN accelerators tackle this research space by casting the aggregation and combination stages as a series of sparse-dense matrix multiplication. However, prior work frequently suffers from inefficient data movements, leaving significant performance left on the table. We present GROW, a GCN accelerator based on Gustavson's algorithm to architect a row-wise product based sparse-dense GEMM accelerator. GROW co-designs the software/hardware that strikes a balance in locality and parallelism for GCNs, achieving significant energy-efficiency improvements vs. state-of-the-art GCN accelerators.