 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler
Jul 15, 2024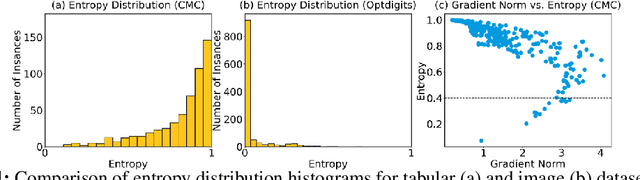
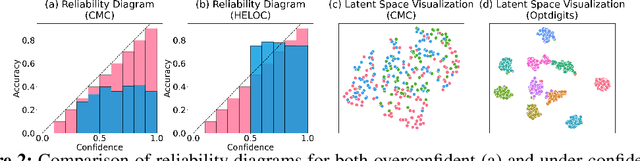
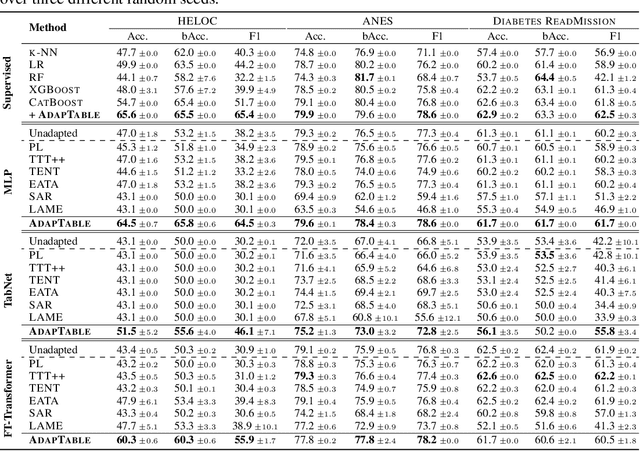
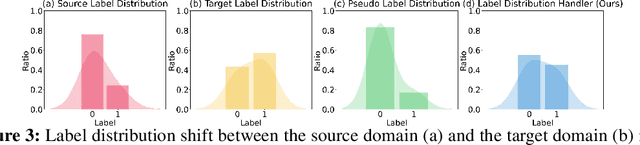
In real-world applications, tabular data often suffer from distribution shifts due to their widespread and abundant nature, leading to erroneous predictions of pre-trained machine learning models. However, addressing such distribution shifts in the tabular domain has been relatively underexplored due to unique challenges such as varying attributes and dataset sizes, as well as the limited representation learning capabilities of deep learning models for tabular data. Particularly, with the recent promising paradigm of test-time adaptation (TTA), where we adapt the off-the-shelf model to the unlabeled target domain during the inference phase without accessing the source domain, we observe that directly adopting commonly used TTA methods from other domains often leads to model collapse. We systematically explore challenges in tabular data test-time adaptation, including skewed entropy, complex latent space decision boundaries, confidence calibration issues with both overconfident and under-confident, and model bias towards source label distributions along with class imbalances. Based on these insights, we introduce AdapTable, a novel tabular test-time adaptation method that directly modifies output probabilities by estimating target label distributions and adjusting initial probabilities based on calibrated uncertainty. Extensive experiments on both natural distribution shifts and synthetic corruptions demonstrate the adaptation efficacy of the proposed method.