 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
CD-FKD: Cross-Domain Feature Knowledge Distillation for Robust Single-Domain Generalization in Object Detection
Mar 17, 2026Single-domain generalization is essential for object detection, particularly when training models on a single source domain and evaluating them on unseen target domains. Domain shifts, such as changes in weather, lighting, or scene conditions, pose significant challenges to the generalization ability of existing models. To address this, we propose Cross-Domain Feature Knowledge Distillation (CD-FKD), which enhances the generalization capability of the student network by leveraging both global and instance-wise feature distillation. The proposed method uses diversified data through downscaling and corruption to train the student network, whereas the teacher network receives the original source domain data. The student network mimics the features of the teacher through both global and instance-wise distillation, enabling it to extract object-centric features effectively, even for objects that are difficult to detect owing to corruption. Extensive experiments on challenging scenes demonstrate that CD-FKD outperforms state-of-the-art methods in both target domain generalization and source domain performance, validating its effectiveness in improving object detection robustness to domain shifts. This approach is valuable in real-world applications, like autonomous driving and surveillance, where robust object detection in diverse environments is crucial.
GraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025
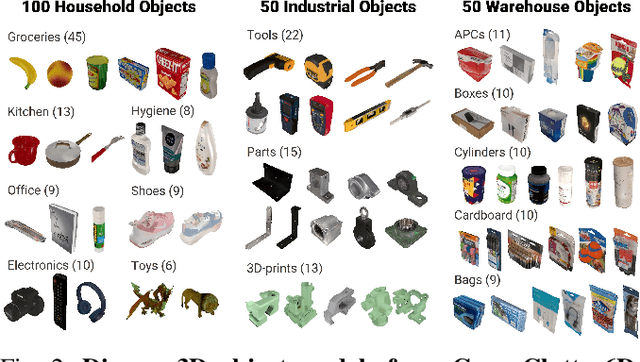
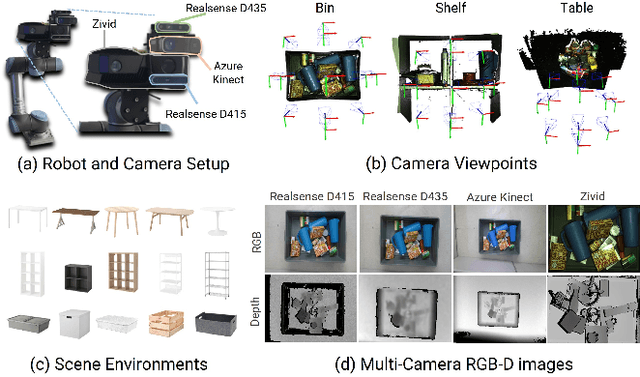
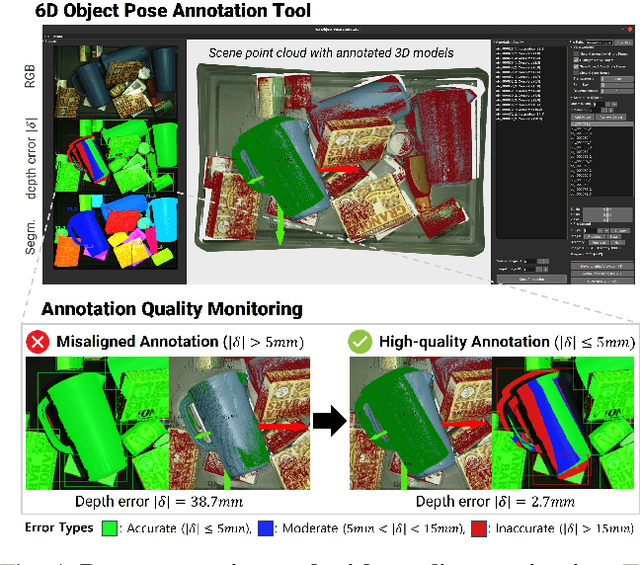
Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Curriculum Fine-tuning of Vision Foundation Model for Medical Image Classification Under Label Noise
Nov 29, 2024Deep neural networks have demonstrated remarkable performance in various vision tasks, but their success heavily depends on the quality of the training data. Noisy labels are a critical issue in medical datasets and can significantly degrade model performance. Previous clean sample selection methods have not utilized the well pre-trained features of vision foundation models (VFMs) and assumed that training begins from scratch. In this paper, we propose CUFIT, a curriculum fine-tuning paradigm of VFMs for medical image classification under label noise. Our method is motivated by the fact that linear probing of VFMs is relatively unaffected by noisy samples, as it does not update the feature extractor of the VFM, thus robustly classifying the training samples. Subsequently, curriculum fine-tuning of two adapters is conducted, starting with clean sample selection from the linear probing phase. Our experimental results demonstrate that CUFIT outperforms previous methods across various medical image benchmarks. Specifically, our method surpasses previous baselines by 5.0%, 2.1%, 4.6%, and 5.8% at a 40% noise rate on the HAM10000, APTOS-2019, BloodMnist, and OrgancMnist datasets, respectively. Furthermore, we provide extensive analyses to demonstrate the impact of our method on noisy label detection. For instance, our method shows higher label precision and recall compared to previous approaches. Our work highlights the potential of leveraging VFMs in medical image classification under challenging conditions of noisy labels.
MART: MultiscAle Relational Transformer Networks for Multi-agent Trajectory Prediction
Jul 31, 2024Multi-agent trajectory prediction is crucial to autonomous driving and understanding the surrounding environment. Learning-based approaches for multi-agent trajectory prediction, such as primarily relying on graph neural networks, graph transformers, and hypergraph neural networks, have demonstrated outstanding performance on real-world datasets in recent years. However, the hypergraph transformer-based method for trajectory prediction is yet to be explored. Therefore, we present a MultiscAle Relational Transformer (MART) network for multi-agent trajectory prediction. MART is a hypergraph transformer architecture to consider individual and group behaviors in transformer machinery. The core module of MART is the encoder, which comprises a Pair-wise Relational Transformer (PRT) and a Hyper Relational Transformer (HRT). The encoder extends the capabilities of a relational transformer by introducing HRT, which integrates hyperedge features into the transformer mechanism, promoting attention weights to focus on group-wise relations. In addition, we propose an Adaptive Group Estimator (AGE) designed to infer complex group relations in real-world environments. Extensive experiments on three real-world datasets (NBA, SDD, and ETH-UCY) demonstrate that our method achieves state-of-the-art performance, enhancing ADE/FDE by 3.9%/11.8% on the NBA dataset. Code is available at https://github.com/gist-ailab/MART.
Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation
Apr 17, 2024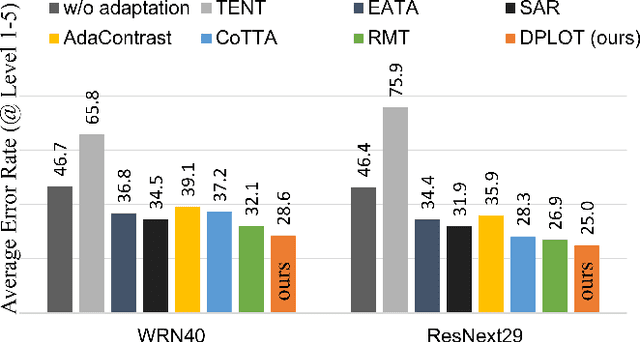
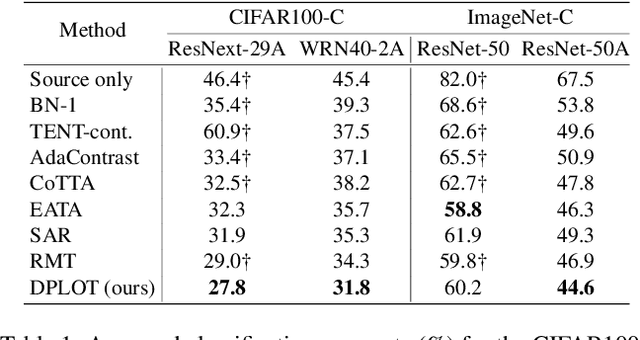
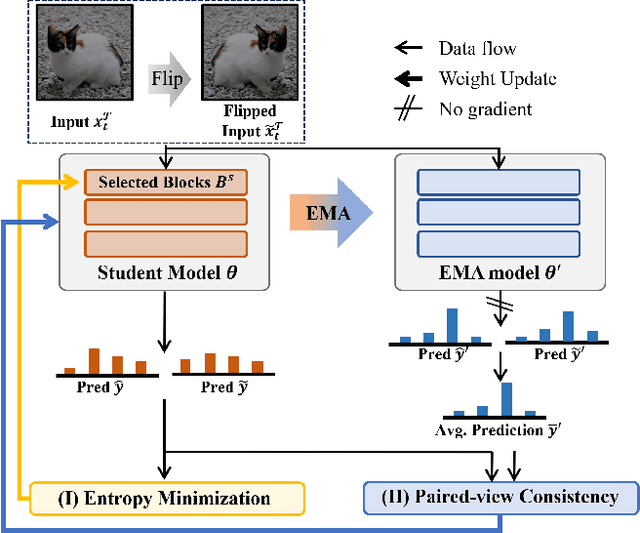
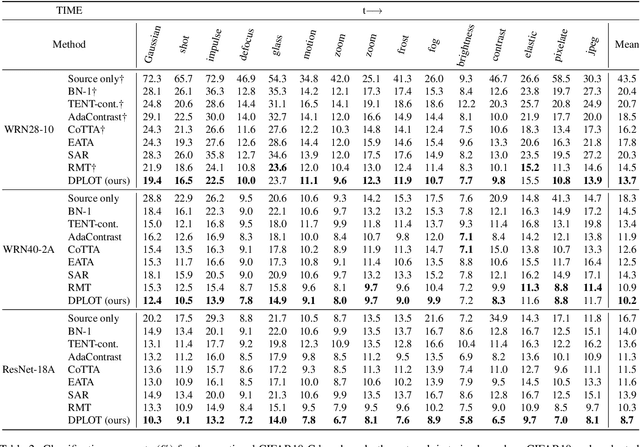
Test-time adaptation (TTA) aims to adapt a pre-trained model to a new test domain without access to source data after deployment. Existing approaches typically rely on self-training with pseudo-labels since ground-truth cannot be obtained from test data. Although the quality of pseudo labels is important for stable and accurate long-term adaptation, it has not been previously addressed. In this work, we propose DPLOT, a simple yet effective TTA framework that consists of two components: (1) domain-specific block selection and (2) pseudo-label generation using paired-view images. Specifically, we select blocks that involve domain-specific feature extraction and train these blocks by entropy minimization. After blocks are adjusted for current test domain, we generate pseudo-labels by averaging given test images and corresponding flipped counterparts. By simply using flip augmentation, we prevent a decrease in the quality of the pseudo-labels, which can be caused by the domain gap resulting from strong augmentation. Our experimental results demonstrate that DPLOT outperforms previous TTA methods in CIFAR10-C, CIFAR100-C, and ImageNet-C benchmarks, reducing error by up to 5.4%, 9.1%, and 2.9%, respectively. Also, we provide an extensive analysis to demonstrate effectiveness of our framework. Code is available at https://github.com/gist-ailab/domain-specific-block-selection-and-paired-view-pseudo-labeling-for-online-TTA.
PolyFit: A Peg-in-hole Assembly Framework for Unseen Polygon Shapes via Sim-to-real Adaptation
Dec 05, 2023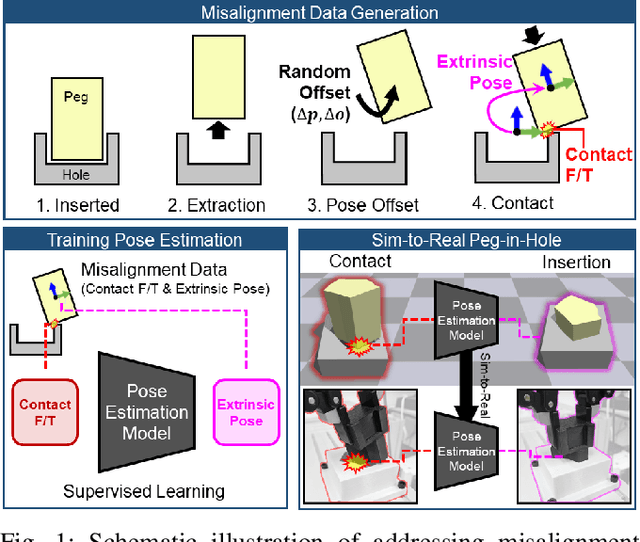
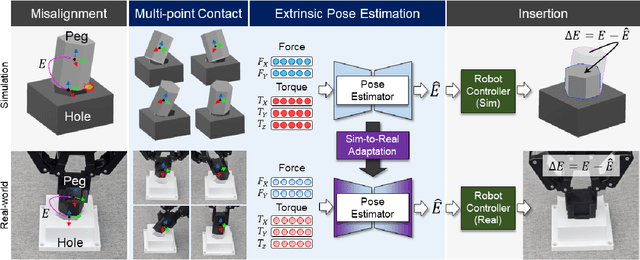
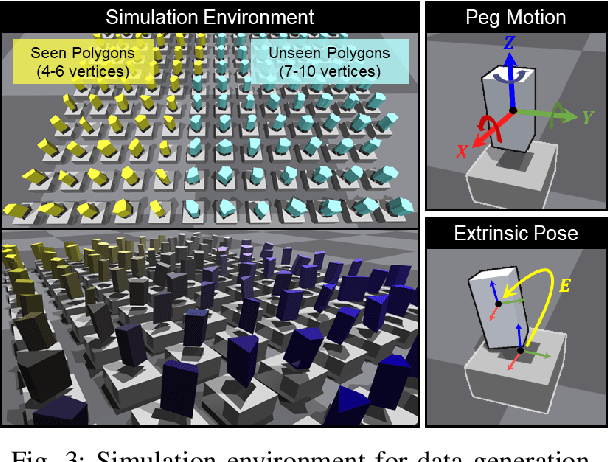
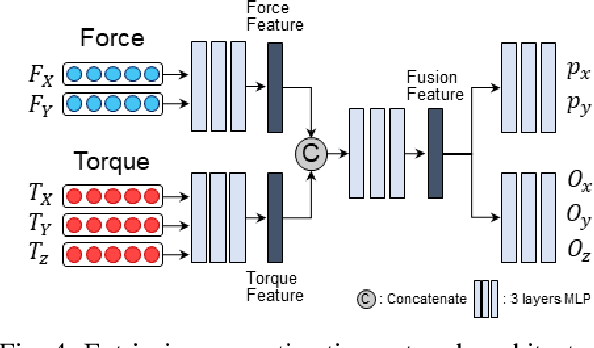
The study addresses the foundational and challenging task of peg-in-hole assembly in robotics, where misalignments caused by sensor inaccuracies and mechanical errors often result in insertion failures or jamming. This research introduces PolyFit, representing a paradigm shift by transitioning from a reinforcement learning approach to a supervised learning methodology. PolyFit is a Force/Torque (F/T)-based supervised learning framework designed for 5-DoF peg-in-hole assembly. It utilizes F/T data for accurate extrinsic pose estimation and adjusts the peg pose to rectify misalignments. Extensive training in a simulated environment involves a dataset encompassing a diverse range of peg-hole shapes, extrinsic poses, and their corresponding contact F/T readings. To enhance extrinsic pose estimation, a multi-point contact strategy is integrated into the model input, recognizing that identical F/T readings can indicate different poses. The study proposes a sim-to-real adaptation method for real-world application, using a sim-real paired dataset to enable effective generalization to complex and unseen polygon shapes. PolyFit achieves impressive peg-in-hole success rates of 97.3% and 96.3% for seen and unseen shapes in simulations, respectively. Real-world evaluations further demonstrate substantial success rates of 86.7% and 85.0%, highlighting the robustness and adaptability of the proposed method.
INSTA-BEEER: Explicit Error Estimation and Refinement for Fast and Accurate Unseen Object Instance Segmentation
Jun 28, 2023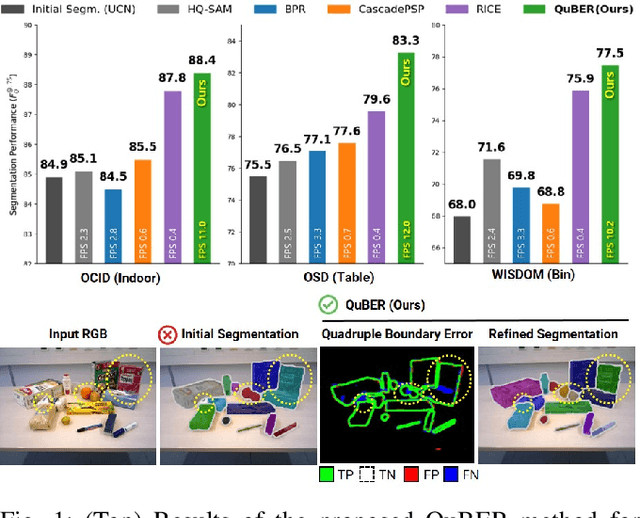

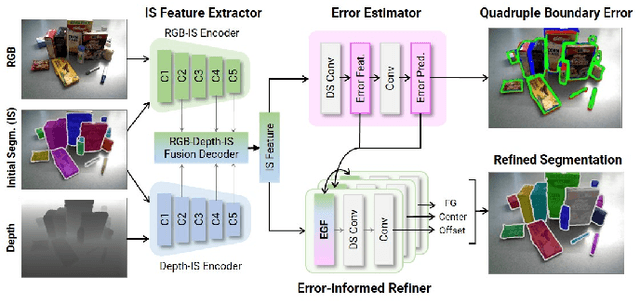

Efficient and accurate segmentation of unseen objects is crucial for robotic manipulation. However, it remains challenging due to over- or under-segmentation. Although existing refinement methods can enhance the segmentation quality, they fix only minor boundary errors or are not sufficiently fast. In this work, we propose INSTAnce Boundary Explicit Error Estimation and Refinement (INSTA-BEEER), a novel refinement model that allows for adding and deleting instances and sharpening boundaries. Leveraging an error-estimation-then-refinement scheme, the model first estimates the pixel-wise boundary explicit errors: true positive, true negative, false positive, and false negative pixels of the instance boundary in the initial segmentation. It then refines the initial segmentation using these error estimates as guidance. Experiments show that the proposed model significantly enhances segmentation, achieving state-of-the-art performance. Furthermore, with a fast runtime (less than 0.1 s), the model consistently improves performance across various initial segmentation methods, making it highly suitable for practical robotic applications.
Learning to Place Unseen Objects Stably using a Large-scale Simulation
Mar 15, 2023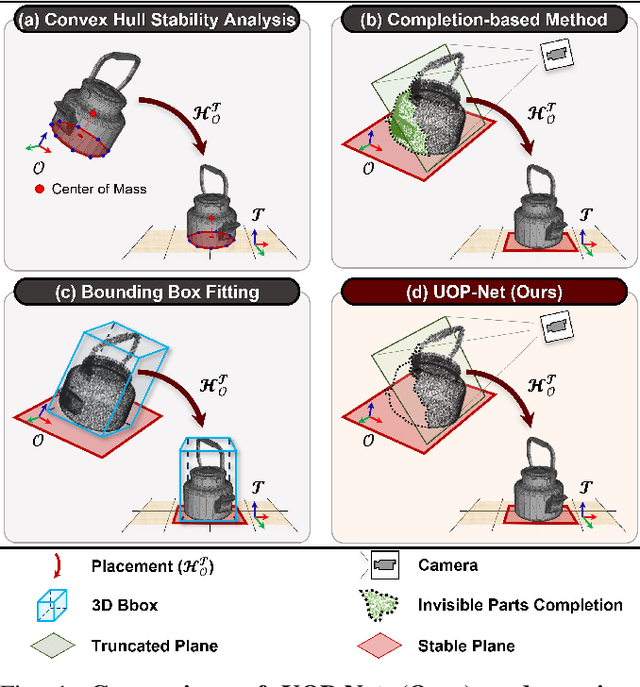
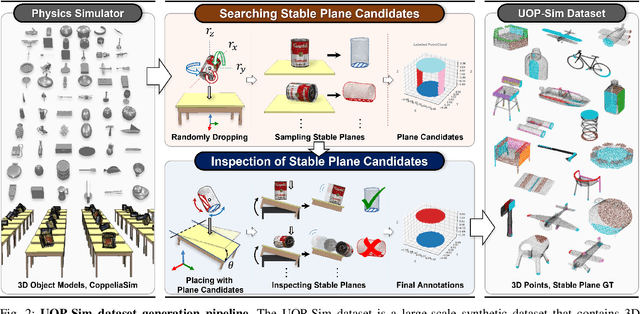
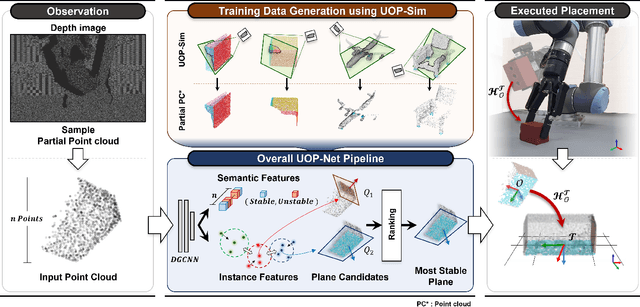
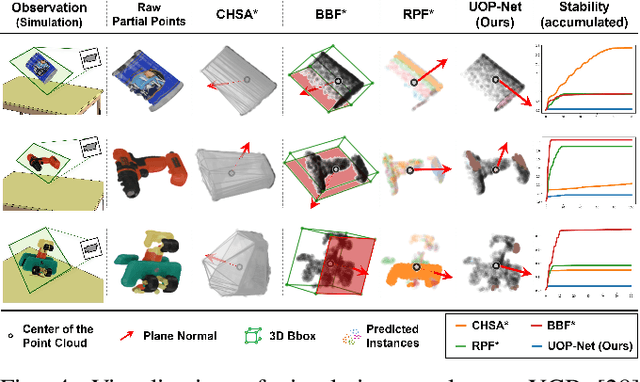
Object placement is a crucial task for robots in unstructured environments as it enables them to manipulate and arrange objects safely and efficiently. However, existing methods for object placement have limitations, such as the requirement for a complete 3D model of the object or the inability to handle complex object shapes, which restrict the applicability of robots in unstructured scenarios. In this paper, we propose an Unseen Object Placement (UOP) method that directly detects stable planes of unseen objects from a single-view and partial point cloud. We trained our model on large-scale simulation data to generalize over relationships between the shape and properties of stable planes with a 3D point cloud. We verify our approach through simulation and real-world robot experiments, demonstrating state-of-the-art performance for placing single-view and partial objects. Our UOP approach enables robots to place objects stably, even when the object's shape and properties are not fully known, providing a promising solution for object placement in unstructured environments. Our research has potential applications in various domains such as manufacturing, logistics, and home automation. Additional results can be viewed on https://sites.google.com/uop-net, and we will release our code, dataset upon publication.