 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025
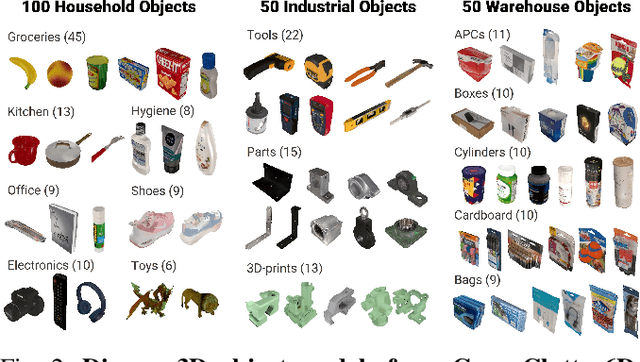
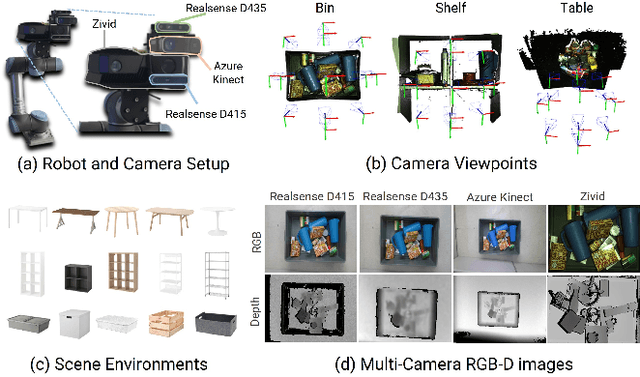
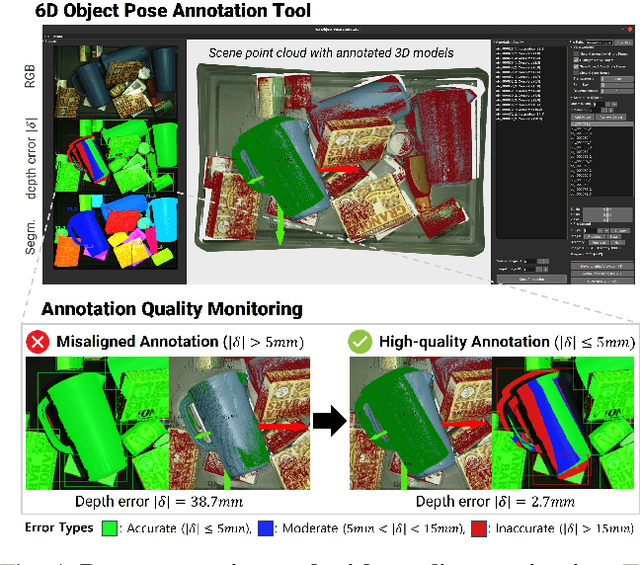
Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
PolyFit: A Peg-in-hole Assembly Framework for Unseen Polygon Shapes via Sim-to-real Adaptation
Dec 05, 2023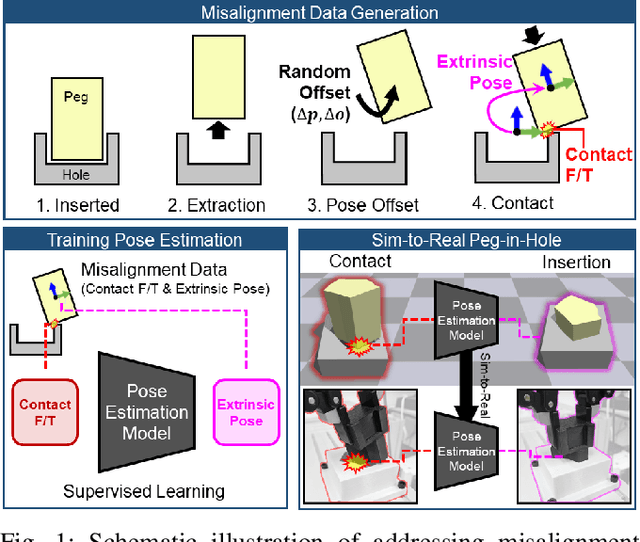
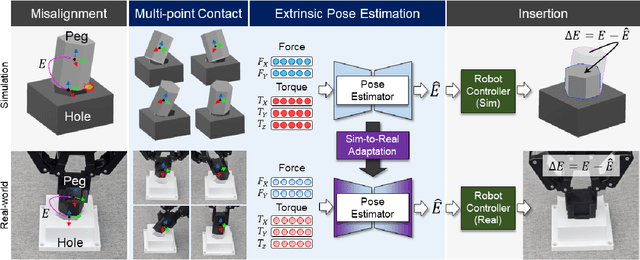
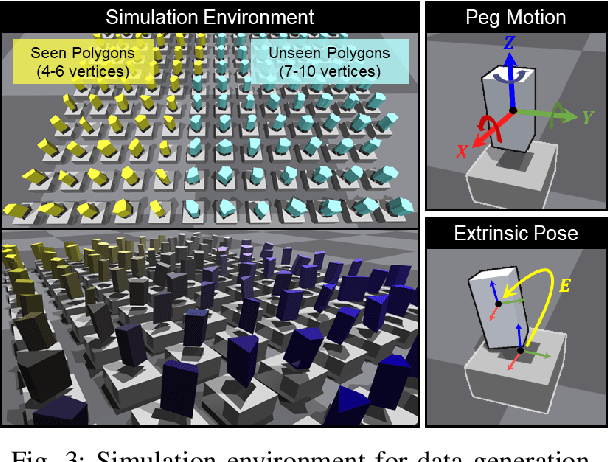
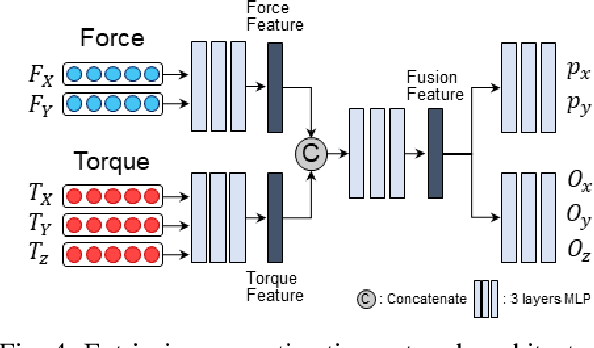
The study addresses the foundational and challenging task of peg-in-hole assembly in robotics, where misalignments caused by sensor inaccuracies and mechanical errors often result in insertion failures or jamming. This research introduces PolyFit, representing a paradigm shift by transitioning from a reinforcement learning approach to a supervised learning methodology. PolyFit is a Force/Torque (F/T)-based supervised learning framework designed for 5-DoF peg-in-hole assembly. It utilizes F/T data for accurate extrinsic pose estimation and adjusts the peg pose to rectify misalignments. Extensive training in a simulated environment involves a dataset encompassing a diverse range of peg-hole shapes, extrinsic poses, and their corresponding contact F/T readings. To enhance extrinsic pose estimation, a multi-point contact strategy is integrated into the model input, recognizing that identical F/T readings can indicate different poses. The study proposes a sim-to-real adaptation method for real-world application, using a sim-real paired dataset to enable effective generalization to complex and unseen polygon shapes. PolyFit achieves impressive peg-in-hole success rates of 97.3% and 96.3% for seen and unseen shapes in simulations, respectively. Real-world evaluations further demonstrate substantial success rates of 86.7% and 85.0%, highlighting the robustness and adaptability of the proposed method.
INSTA-BEEER: Explicit Error Estimation and Refinement for Fast and Accurate Unseen Object Instance Segmentation
Jun 28, 2023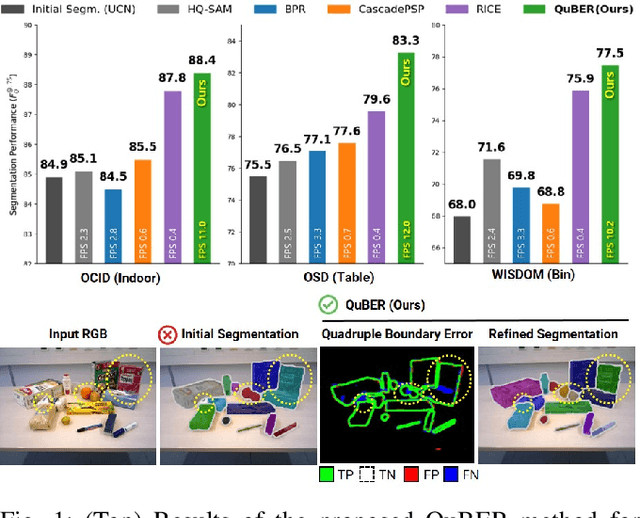

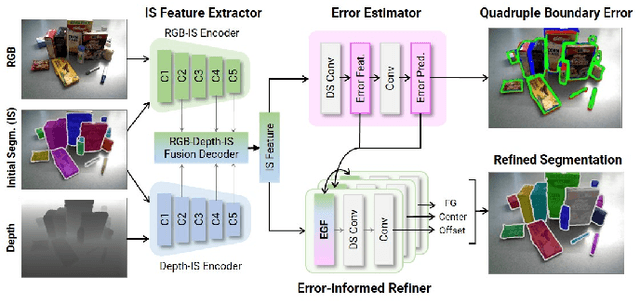

Efficient and accurate segmentation of unseen objects is crucial for robotic manipulation. However, it remains challenging due to over- or under-segmentation. Although existing refinement methods can enhance the segmentation quality, they fix only minor boundary errors or are not sufficiently fast. In this work, we propose INSTAnce Boundary Explicit Error Estimation and Refinement (INSTA-BEEER), a novel refinement model that allows for adding and deleting instances and sharpening boundaries. Leveraging an error-estimation-then-refinement scheme, the model first estimates the pixel-wise boundary explicit errors: true positive, true negative, false positive, and false negative pixels of the instance boundary in the initial segmentation. It then refines the initial segmentation using these error estimates as guidance. Experiments show that the proposed model significantly enhances segmentation, achieving state-of-the-art performance. Furthermore, with a fast runtime (less than 0.1 s), the model consistently improves performance across various initial segmentation methods, making it highly suitable for practical robotic applications.
Teaching Where to Look: Attention Similarity Knowledge Distillation for Low Resolution Face Recognition
Sep 29, 2022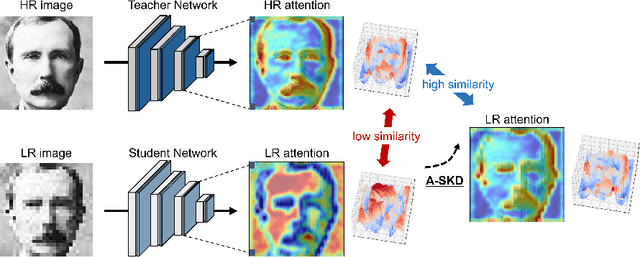
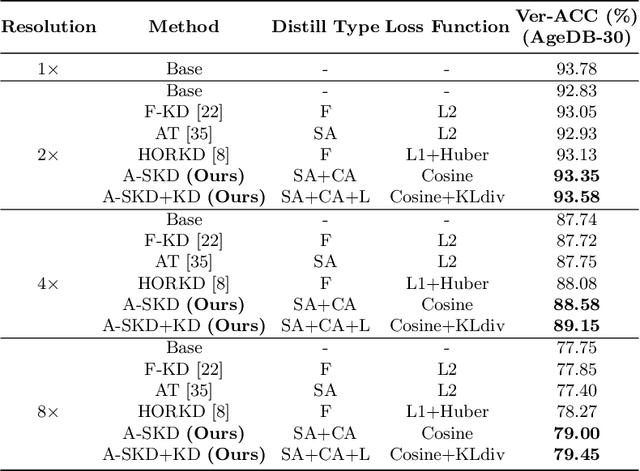

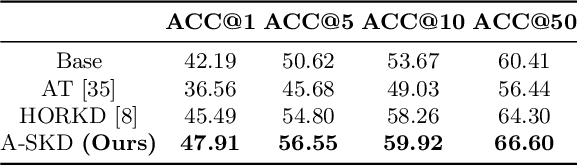
Deep learning has achieved outstanding performance for face recognition benchmarks, but performance reduces significantly for low resolution (LR) images. We propose an attention similarity knowledge distillation approach, which transfers attention maps obtained from a high resolution (HR) network as a teacher into an LR network as a student to boost LR recognition performance. Inspired by humans being able to approximate an object's region from an LR image based on prior knowledge obtained from HR images, we designed the knowledge distillation loss using the cosine similarity to make the student network's attention resemble the teacher network's attention. Experiments on various LR face related benchmarks confirmed the proposed method generally improved recognition performances on LR settings, outperforming state-of-the-art results by simply transferring well-constructed attention maps. The code and pretrained models are publicly available in the https://github.com/gist-ailab/teaching-where-to-look.
Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling
Sep 23, 2021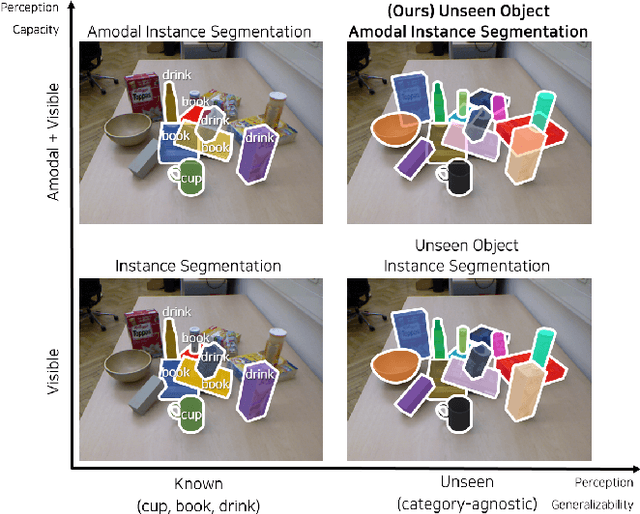
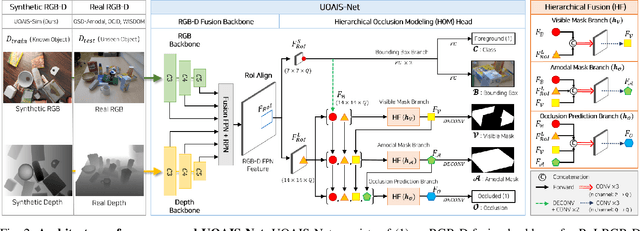
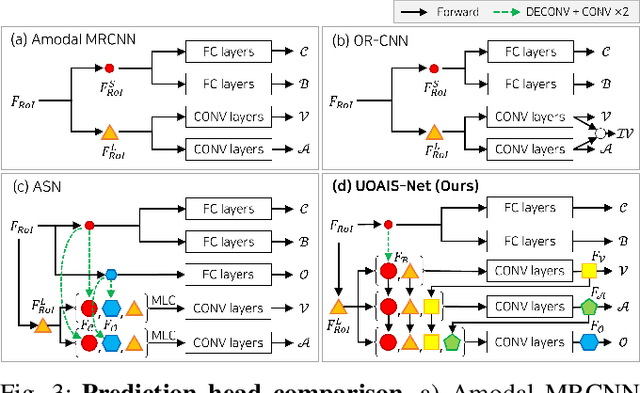

Instance-aware segmentation of unseen objects is essential for a robotic system in an unstructured environment. Although previous works achieved encouraging results, they were limited to segmenting the only visible regions of unseen objects. For robotic manipulation in a cluttered scene, amodal perception is required to handle the occluded objects behind others. This paper addresses Unseen Object Amodal Instance Segmentation (UOAIS) to detect 1) visible masks, 2) amodal masks, and 3) occlusions on unseen object instances. For this, we propose a Hierarchical Occlusion Modeling (HOM) scheme designed to reason about the occlusion by assigning a hierarchy to a feature fusion and prediction order. We evaluated our method on three benchmarks (tabletop, indoors, and bin environments) and achieved state-of-the-art (SOTA) performance. Robot demos for picking up occluded objects, codes, and datasets are available at https://sites.google.com/view/uoais
Object Detection for Understanding Assembly Instruction Using Context-aware Data Augmentation and Cascade Mask R-CNN
Jan 08, 2021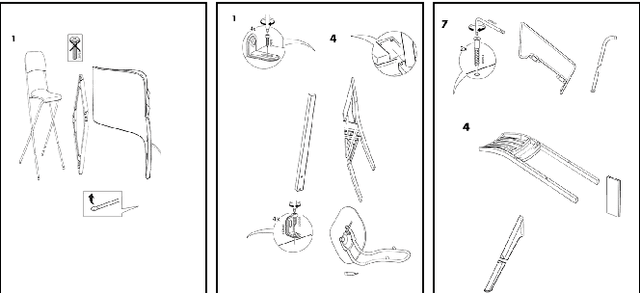

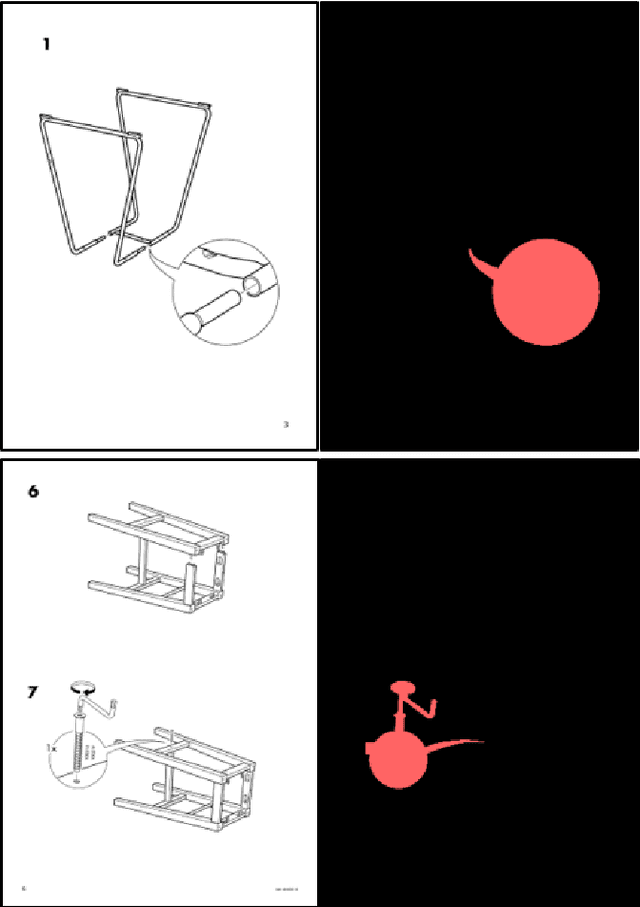
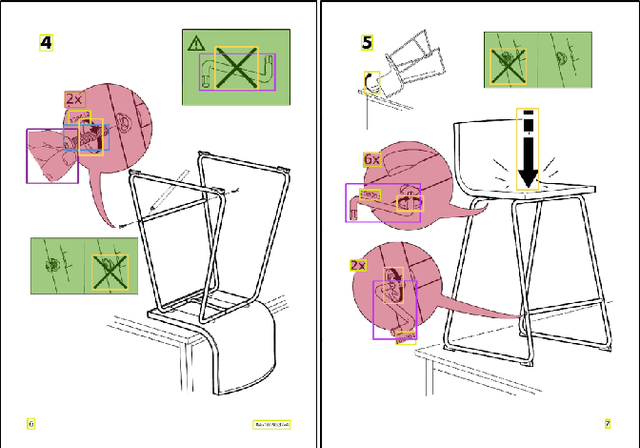
Understanding assembly instruction has the potential to enhance the robot s task planning ability and enables advanced robotic applications. To recognize the key components from the 2D assembly instruction image, We mainly focus on segmenting the speech bubble area, which contains lots of information about instructions. For this, We applied Cascade Mask R-CNN and developed a context-aware data augmentation scheme for speech bubble segmentation, which randomly combines images cuts by considering the context of assembly instructions. We showed that the proposed augmentation scheme achieves a better segmentation performance compared to the existing augmentation algorithm by increasing the diversity of trainable data while considering the distribution of components locations. Also, we showed that deep learning can be useful to understand assembly instruction by detecting the essential objects in the assembly instruction, such as tools and parts.