 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtendable Long-Horizon Planning via Hierarchical Multiscale Diffusion
Mar 25, 2025



This paper tackles a novel problem, extendable long-horizon planning-enabling agents to plan trajectories longer than those in training data without compounding errors. To tackle this, we propose the Hierarchical Multiscale Diffuser (HM-Diffuser) and Progressive Trajectory Extension (PTE), an augmentation method that iteratively generates longer trajectories by stitching shorter ones. HM-Diffuser trains on these extended trajectories using a hierarchical structure, efficiently handling tasks across multiple temporal scales. Additionally, we introduce Adaptive Plan Pondering and the Recursive HM-Diffuser, which consolidate hierarchical layers into a single model to process temporal scales recursively. Experimental results demonstrate the effectiveness of our approach, advancing diffusion-based planners for scalable long-horizon planning.
Dr. Strategy: Model-Based Generalist Agents with Strategic Dreaming
Feb 29, 2024



Model-based reinforcement learning (MBRL) has been a primary approach to ameliorating the sample efficiency issue as well as to make a generalist agent. However, there has not been much effort toward enhancing the strategy of dreaming itself. Therefore, it is a question whether and how an agent can "dream better" in a more structured and strategic way. In this paper, inspired by the observation from cognitive science suggesting that humans use a spatial divide-and-conquer strategy in planning, we propose a new MBRL agent, called Dr. Strategy, which is equipped with a novel Dreaming Strategy. The proposed agent realizes a version of divide-and-conquer-like strategy in dreaming. This is achieved by learning a set of latent landmarks and then utilizing these to learn a landmark-conditioned highway policy. With the highway policy, the agent can first learn in the dream to move to a landmark, and from there it tackles the exploration and achievement task in a more focused way. In experiments, we show that the proposed model outperforms prior pixel-based MBRL methods in various visually complex and partially observable navigation tasks. The source code will be available at https://github.com/ahn-ml/drstrategy
Residual Dynamics Learning for Trajectory Tracking for Multi-rotor Aerial Vehicles
May 25, 2023This paper presents a technique to cope with the gap between high-level planning, e.g., reference trajectory tracking, and low-level controlling using a learning-based method in the plan-based control paradigm. The technique improves the smoothness of maneuvering through cluttered environments, especially targeting low-speed velocity profiles. In such a profile, external aerodynamic effects that are applied on the quadrotor can be neglected. Hence, we used a simplified motion model to represent the motion of the quadrotor when formulating the Nonlinear Model Predictive Control (NMPC)-based local planner. However, the simplified motion model causes residual dynamics between the high-level planner and the low-level controller. The Sparse Gaussian Process Regression-based technique is proposed to reduce these residual dynamics. The proposed technique is compared with Data-Driven MPC. The comparison results yield that an augmented residual dynamics model-based planner helps to reduce the nominal model error by a factor of 2 on average. Further, we compared the proposed complete framework with four other approaches. The proposed approach outperformed the others in terms of tracking the reference trajectory without colliding with obstacles with less flight time without losing computational efficiency.
Optimization-based Trajectory Tracking Approach for Multi-rotor Aerial Vehicles in Unknown Environments
Feb 12, 2022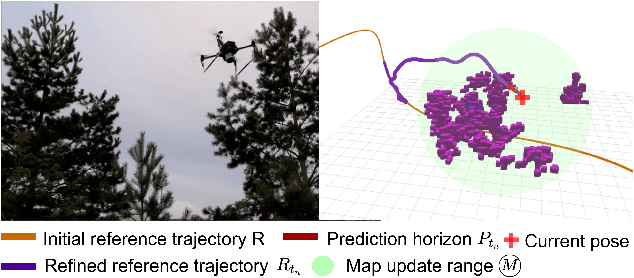
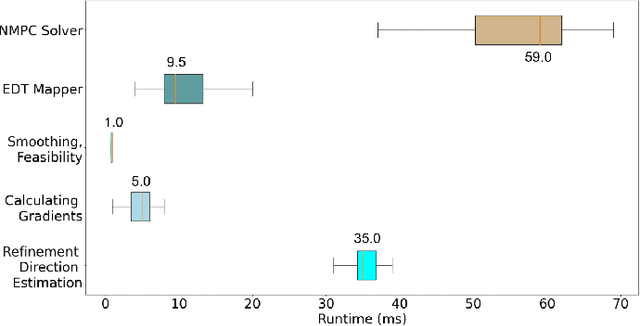
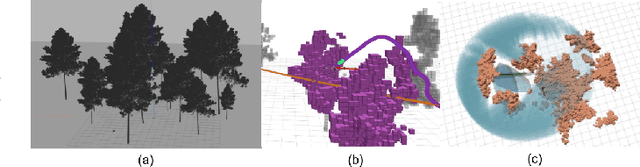
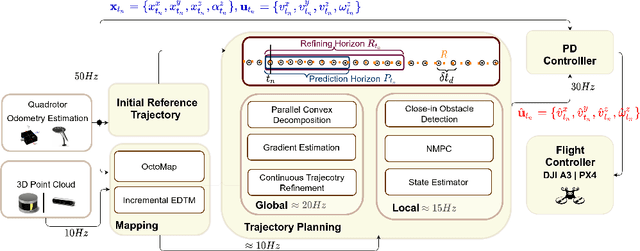
The goal of this paper is to develop a continuous optimization-based refinement of the reference trajectory to 'push it out' of the obstacle-occupied space in the global phase for Multi-rotor Aerial Vehicles in unknown environments. Our proposed approach comprises two planners: a global planner and a local planner. The global planner refines the initial reference trajectory when the trajectory goes either through an obstacle or near an obstacle and lets the local planner calculate a near-optimal control policy. The global planner comprises two convex programming approaches: the first one helps to refine the reference trajectory, and the second one helps to recover the reference trajectory if the first approach fails to refine. The global planner mainly focuses on real-time performance and obstacles avoidance, whereas the proposed formulation of the constrained nonlinear model predictive control-based local planner ensures safety, dynamic feasibility, and the reference trajectory tracking accuracy for low-speed maneuvers, provided that local and global planners have mean computation times 0.06s (15Hz) and 0.05s (20Hz), respectively, on an NVIDIA Jetson Xavier NX computer. The results of our experiment confirmed that, in cluttered environments, the proposed approach outperformed three other approaches: sampling-based pathfinding followed by trajectory generation, a local planner, and graph-based pathfinding followed by trajectory generation.
Learning Stabilizing Control Policies for a Tensegrity Hopper with Augmented Random Search
Apr 06, 2020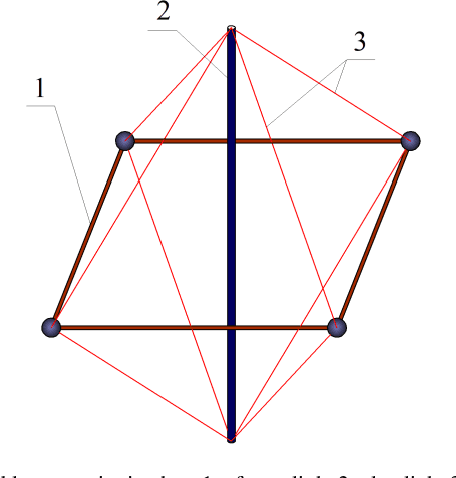
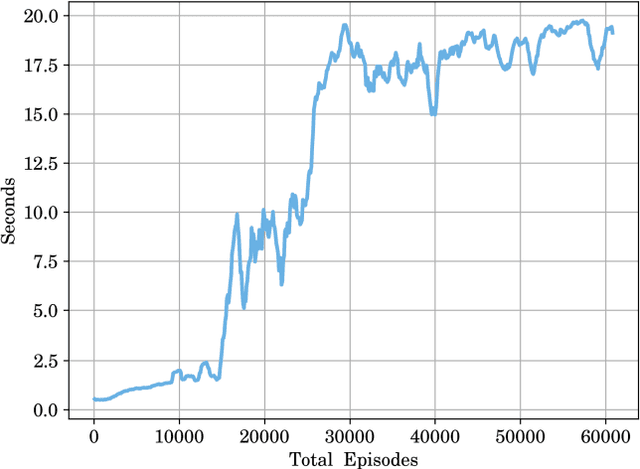
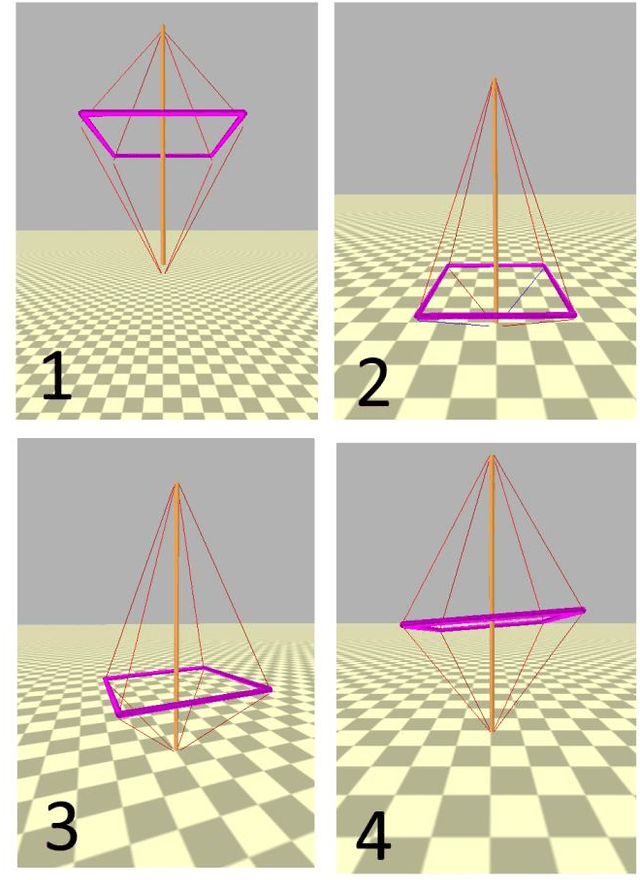
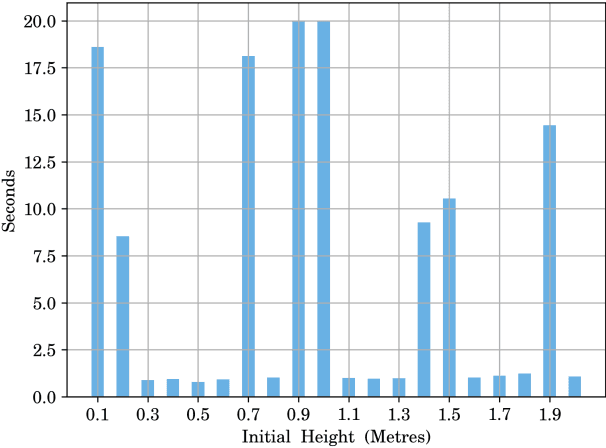
In this paper, we consider tensegrity hopper - a novel tensegrity-based robot, capable of moving by hopping. The paper focuses on the design of the stabilizing control policies, which are obtained with Augmented Random Search method. In particular, we search for control policies which allow the hopper to maintain vertical stability after performing a single jump. It is demonstrated, that the hopper can maintain a vertical configuration, subject to the different initial conditions and with changing control frequency rates. In particular, lowering control frequency from 1000Hz in training to 500Hz in execution did not affect the success rate of the balancing task.