 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025
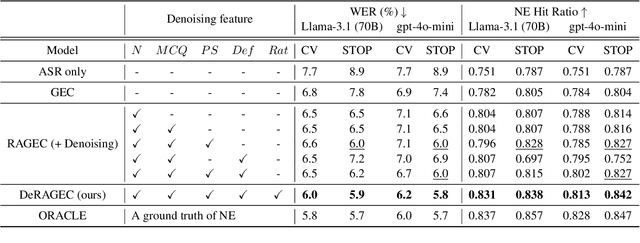

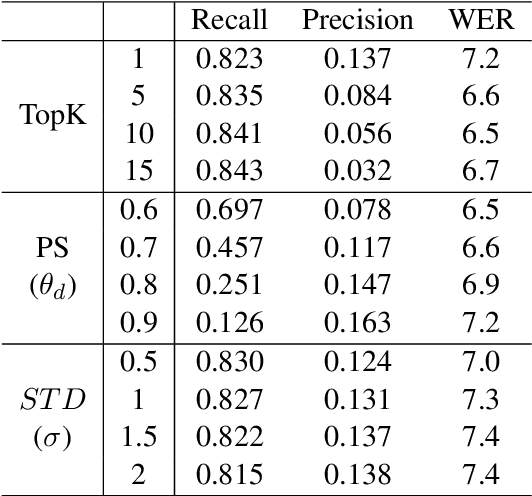
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
Revisiting Early Detection of Sexual Predators via Turn-level Optimization
Mar 09, 2025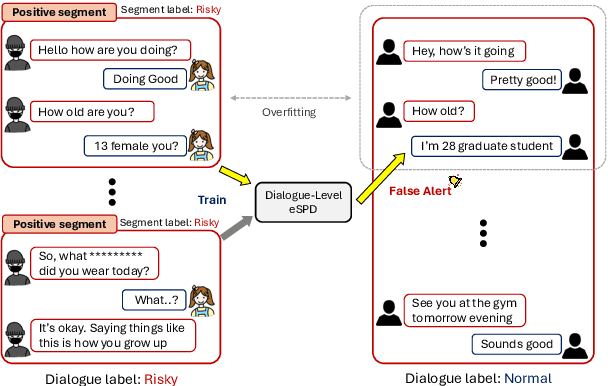



Online grooming is a severe social threat where sexual predators gradually entrap child victims with subtle and gradual manipulation. Therefore, timely intervention for online grooming is critical for proactive protection. However, previous methods fail to determine the optimal intervention points (i.e., jump to conclusions) as they rely on chat-level risk labels by causing weak supervision of risky utterances. For timely detection, we propose speed control reinforcement learning (SCoRL) (The code and supplementary materials are available at https://github.com/jinmyeongAN/SCoRL), incorporating a practical strategy derived from luring communication theory (LCT). To capture the predator's turn-level entrapment, we use a turn-level risk label based on the LCT. Then, we design a novel speed control reward function that balances the trade-off between speed and accuracy based on turn-level risk label; thus, SCoRL can identify the optimal intervention moment. In addition, we introduce a turn-level metric for precise evaluation, identifying limitations in previously used chat-level metrics. Experimental results show that SCoRL effectively preempted online grooming, offering a more proactive and timely solution. Further analysis reveals that our method enhances performance while intuitively identifying optimal early intervention points.
An Investigation Into Explainable Audio Hate Speech Detection
Aug 12, 2024Research on hate speech has predominantly revolved around detection and interpretation from textual inputs, leaving verbal content largely unexplored. While there has been limited exploration into hate speech detection within verbal acoustic speech inputs, the aspect of interpretability has been overlooked. Therefore, we introduce a new task of explainable audio hate speech detection. Specifically, we aim to identify the precise time intervals, referred to as audio frame-level rationales, which serve as evidence for hate speech classification. Towards this end, we propose two different approaches: cascading and End-to-End (E2E). The cascading approach initially converts audio to transcripts, identifies hate speech within these transcripts, and subsequently locates the corresponding audio time frames. Conversely, the E2E approach processes audio utterances directly, which allows it to pinpoint hate speech within specific time frames. Additionally, due to the lack of explainable audio hate speech datasets that include audio frame-level rationales, we curated a synthetic audio dataset to train our models. We further validated these models on actual human speech utterances and found that the E2E approach outperforms the cascading method in terms of the audio frame Intersection over Union (IoU) metric. Furthermore, we observed that including frame-level rationales significantly enhances hate speech detection accuracy for the E2E approach. \textbf{Disclaimer} The reader may encounter content of an offensive or hateful nature. However, given the nature of the work, this cannot be avoided.