 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorDynamic: Generalizable, Scalable, Real-time, End-to-end Local Planner for Unstructured and Dynamic Environments
Feb 27, 2025Deep Reinforcement Learning (DRL) has demonstrated potential in addressing robotic local planning problems, yet its efficacy remains constrained in highly unstructured and dynamic environments. To address these challenges, this study proposes the ColorDynamic framework. First, an end-to-end DRL formulation is established, which maps raw sensor data directly to control commands, thereby ensuring compatibility with unstructured environments. Under this formulation, a novel network, Transqer, is introduced. The Transqer enables online DRL learning from temporal transitions, substantially enhancing decision-making in dynamic scenarios. To facilitate scalable training of Transqer with diverse data, an efficient simulation platform E-Sparrow, along with a data augmentation technique leveraging symmetric invariance, are developed. Comparative evaluations against state-of-the-art methods, alongside assessments of generalizability, scalability, and real-time performance, were conducted to validate the effectiveness of ColorDynamic. Results indicate that our approach achieves a success rate exceeding 90% while exhibiting real-time capacity (1.2-1.3 ms per planning). Additionally, ablation studies were performed to corroborate the contributions of individual components. Building on this, the OkayPlan-ColorDynamic (OPCD) navigation system is presented, with simulated and real-world experiments demonstrating its superiority and applicability in complex scenarios. The codebase and experimental demonstrations have been open-sourced on our website to facilitate reproducibility and further research.
OkayPlan: Obstacle Kinematics Augmented Dynamic Real-time Path Planning via Particle Swarm Optimization
Jan 10, 2024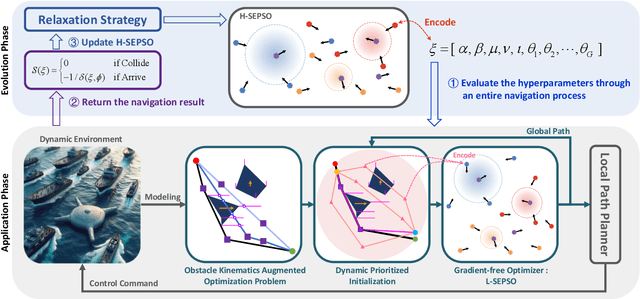

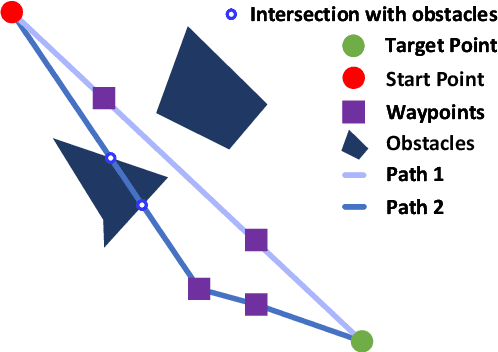

Existing Global Path Planning (GPP) algorithms predominantly presume planning in a static environment. This assumption immensely limits their applications to Unmanned Surface Vehicles (USVs) that typically navigate in dynamic environments. To address this limitation, we present OkayPlan, a GPP algorithm capable of generating safe and short paths in dynamic scenarios at a real-time executing speed (125 Hz on a desktop-class computer). Specifically, we approach the challenge of dynamic obstacle avoidance by formulating the path planning problem as an obstacle kinematics augmented optimization problem, which can be efficiently resolved through a PSO-based optimizer at a real-time speed. Meanwhile, a Dynamic Prioritized Initialization (DPI) mechanism that adaptively initializes potential solutions for the optimization problem is established to further ameliorate the solution quality. Additionally, a relaxation strategy that facilitates the autonomous tuning of OkayPlan's hyperparameters in dynamic environments is devised. Comparative experiments involving canonical and contemporary GPP algorithms, along with ablation studies, have been conducted to substantiate the efficacy of our approach. Results indicate that OkayPlan outstrips existing methods in terms of path safety, length optimality, and computational efficiency, establishing it as a potent GPP technique for dynamic environments. The video and code associated with this paper are accessible at https://github.com/XinJingHao/OkayPlan.
Efficient Real-time Path Planning with Self-evolving Particle Swarm Optimization in Dynamic Scenarios
Aug 20, 2023



Particle Swarm Optimization (PSO) has demonstrated efficacy in addressing static path planning problems. Nevertheless, such application on dynamic scenarios has been severely precluded by PSO's low computational efficiency and premature convergence downsides. To address these limitations, we proposed a Tensor Operation Form (TOF) that converts particle-wise manipulations to tensor operations, thereby enhancing computational efficiency. Harnessing the computational advantage of TOF, a variant of PSO, designated as Self-Evolving Particle Swarm Optimization (SEPSO) was developed. The SEPSO is underpinned by a novel Hierarchical Self-Evolving Framework (HSEF) that enables autonomous optimization of its own hyper-parameters to evade premature convergence. Additionally, a Priori Initialization (PI) mechanism and an Auto Truncation (AT) mechanism that substantially elevates the real-time performance of SEPSO on dynamic path planning problems were introduced. Comprehensive experiments on four widely used benchmark optimization functions have been initially conducted to corroborate the validity of SEPSO. Following this, a dynamic simulation environment that encompasses moving start/target points and dynamic/static obstacles was employed to assess the effectiveness of SEPSO on the dynamic path planning problem. Simulation results exhibit that the proposed SEPSO is capable of generating superior paths with considerably better real-time performance (67 path planning computations per second in a regular desktop computer) in contrast to alternative methods. The code of this paper can be accessed here.
Train a Real-world Local Path Planner in One Hour via Partially Decoupled Reinforcement Learning and Vectorized Diversity
May 07, 2023



Deep Reinforcement Learning (DRL) has exhibited efficacy in resolving the Local Path Planning (LPP) problem. However, such application in the real world is immensely limited due to the deficient efficiency and generalization capability of DRL. To alleviate these two issues, a solution named Color is proposed, which consists of an Actor-Sharer-Learner (ASL) training framework and a mobile robot-oriented simulator Sparrow. Specifically, the ASL framework, intending to improve the efficiency of the DRL algorithm, employs a Vectorized Data Collection (VDC) mode to expedite data acquisition, decouples the data collection from model optimization by multithreading, and partially connects the two procedures by harnessing a Time Feedback Mechanism (TFM) to evade data underuse or overuse. Meanwhile, the Sparrow simulator utilizes a 2D grid-based world, simplified kinematics, and conversion-free data flow to achieve a lightweight design. The lightness facilitates vectorized diversity, allowing diversified simulation setups across extensive copies of the vectorized environments, resulting in a notable enhancement in the generalization capability of the DRL algorithm being trained. Comprehensive experiments, comprising 57 benchmark video games, 32 simulated and 36 real-world LPP scenarios, have been conducted to corroborate the superiority of our method in terms of efficiency and generalization. The code and the video of the experiments can be accessed on our website.
Autonomous Exploration and Mapping for Mobile Robots via Cumulative Curriculum Reinforcement Learning
Feb 25, 2023Deep reinforcement learning (DRL) has been widely applied in autonomous exploration and mapping tasks, but often struggles with the challenges of sampling efficiency, poor adaptability to unknown map sizes, and slow simulation speed. To speed up convergence, we combine curriculum learning (CL) with DRL, and first propose a Cumulative Curriculum Reinforcement Learning (CCRL) training framework to alleviate the issue of catastrophic forgetting faced by general CL. Besides, we present a novel state representation, which considers a local egocentric map and a global exploration map resized to the fixed dimension, so as to flexibly adapt to environments with various sizes and shapes. Additionally, for facilitating the fast training of DRL models, we develop a lightweight grid-based simulator, which can substantially accelerate simulation compared to popular robot simulation platforms such as Gazebo. Based on the customized simulator, comprehensive experiments have been conducted, and the results show that the CCRL framework not only mitigates the catastrophic forgetting problem, but also improves the sample efficiency and generalization of DRL models, compared to general CL as well as without a curriculum. Our code is available at https://github.com/BeamanLi/CCRL_Exploration.