 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Mental States to Guide Social Influence in Multi-Person Group Dialogue
Jan 20, 2026Existing dynamic Theory of Mind (ToM) benchmarks mostly place language models in a passive role: the model reads a sequence of connected scenarios and reports what people believe, feel, intend, and do as these states change. In real social interaction, ToM is also used for action: a speaker plans what to say in order to shift another person's mental-state trajectory toward a goal. We introduce SocialMindChange, a benchmark that moves from tracking minds to changing minds in social interaction. Each instance defines a social context with 4 characters and five connected scenes. The model plays one character and generates dialogue across the five scenes to reach the target while remaining consistent with the evolving states of all participants. SocialMindChange also includes selected higher-order states. Using a structured four-step framework, we construct 1,200 social contexts, covering 6000 scenarios and over 90,000 questions, each validated for realism and quality. Evaluations on ten state-of-the-art LLMs show that their average performance is 54.2% below human performance. This gap suggests that current LLMs still struggle to maintain and change mental-state representations across long, linked interactions.
ColorDynamic: Generalizable, Scalable, Real-time, End-to-end Local Planner for Unstructured and Dynamic Environments
Feb 27, 2025Deep Reinforcement Learning (DRL) has demonstrated potential in addressing robotic local planning problems, yet its efficacy remains constrained in highly unstructured and dynamic environments. To address these challenges, this study proposes the ColorDynamic framework. First, an end-to-end DRL formulation is established, which maps raw sensor data directly to control commands, thereby ensuring compatibility with unstructured environments. Under this formulation, a novel network, Transqer, is introduced. The Transqer enables online DRL learning from temporal transitions, substantially enhancing decision-making in dynamic scenarios. To facilitate scalable training of Transqer with diverse data, an efficient simulation platform E-Sparrow, along with a data augmentation technique leveraging symmetric invariance, are developed. Comparative evaluations against state-of-the-art methods, alongside assessments of generalizability, scalability, and real-time performance, were conducted to validate the effectiveness of ColorDynamic. Results indicate that our approach achieves a success rate exceeding 90% while exhibiting real-time capacity (1.2-1.3 ms per planning). Additionally, ablation studies were performed to corroborate the contributions of individual components. Building on this, the OkayPlan-ColorDynamic (OPCD) navigation system is presented, with simulated and real-world experiments demonstrating its superiority and applicability in complex scenarios. The codebase and experimental demonstrations have been open-sourced on our website to facilitate reproducibility and further research.
Performance of Medical Image Fusion in High-level Analysis Tasks: A Mutual Enhancement Framework for Unaligned PAT and MRI Image Fusion
Jul 04, 2024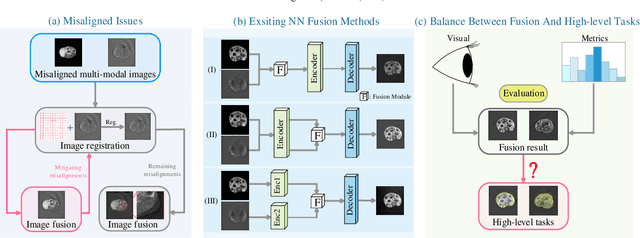
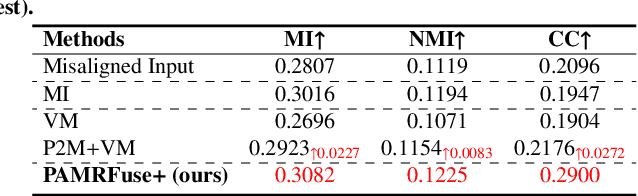
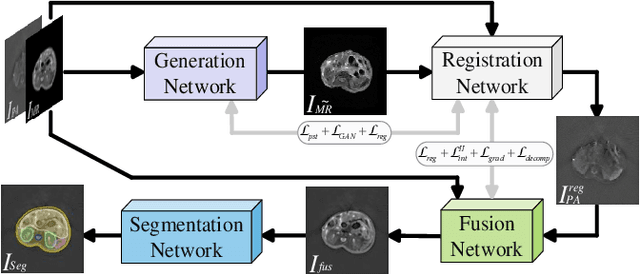
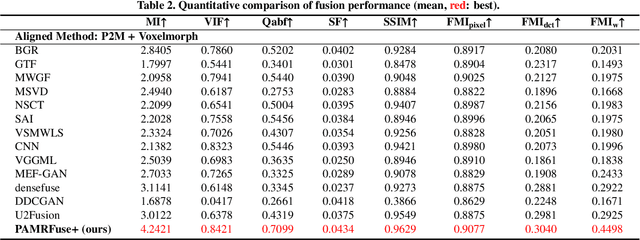
Photoacoustic tomography (PAT) offers optical contrast, whereas magnetic resonance imaging (MRI) excels in imaging soft tissue and organ anatomy. The fusion of PAT with MRI holds promising application prospects due to their complementary advantages. Existing image fusion have made considerable progress in pre-registered images, yet spatial deformations are difficult to avoid in medical imaging scenarios. More importantly, current algorithms focus on visual quality and statistical metrics, thus overlooking the requirements of high-level tasks. To address these challenges, we proposes a unsupervised fusion model, termed PAMRFuse+, which integrates image generation and registration. Specifically, a cross-modal style transfer network is introduced to simplify cross-modal registration to single-modal registration. Subsequently, a multi-level registration network is employed to predict displacement vector fields. Furthermore, a dual-branch feature decomposition fusion network is proposed to address the challenges of cross-modal feature modeling and decomposition by integrating modality-specific and modality-shared features. PAMRFuse+ achieves satisfactory results in registering and fusing unaligned PAT-MRI datasets. Moreover, for the first time, we evaluate the performance of medical image fusion with contour segmentation and multi-organ instance segmentation. Extensive experimental demonstrations reveal the advantages of PAMRFuse+ in improving the performance of medical image analysis tasks.
Deep learning acceleration of iterative model-based light fluence correction for photoacoustic tomography
Dec 08, 2023Photoacoustic tomography (PAT) is a promising imaging technique that can visualize the distribution of chromophores within biological tissue. However, the accuracy of PAT imaging is compromised by light fluence (LF), which hinders the quantification of light absorbers. Currently, model-based iterative methods are used for LF correction, but they require significant computational resources due to repeated LF estimation based on differential light transport models. To improve LF correction efficiency, we propose to use Fourier neural operator (FNO), a neural network specially designed for solving differential equations, to learn the forward projection of light transport in PAT. Trained using paired finite-element-based LF simulation data, our FNO model replaces the traditional computational heavy LF estimator during iterative correction, such that the correction procedure is significantly accelerated. Simulation and experimental results demonstrate that our method achieves comparable LF correction quality to traditional iterative methods while reducing the correction time by over 30 times.
Explainable fMRI-based Brain Decoding via Spatial Temporal-pyramid Graph Convolutional Network
Oct 08, 2022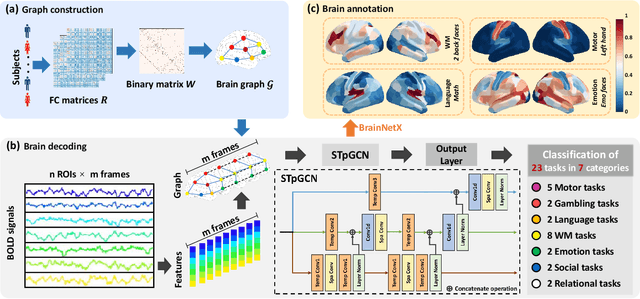
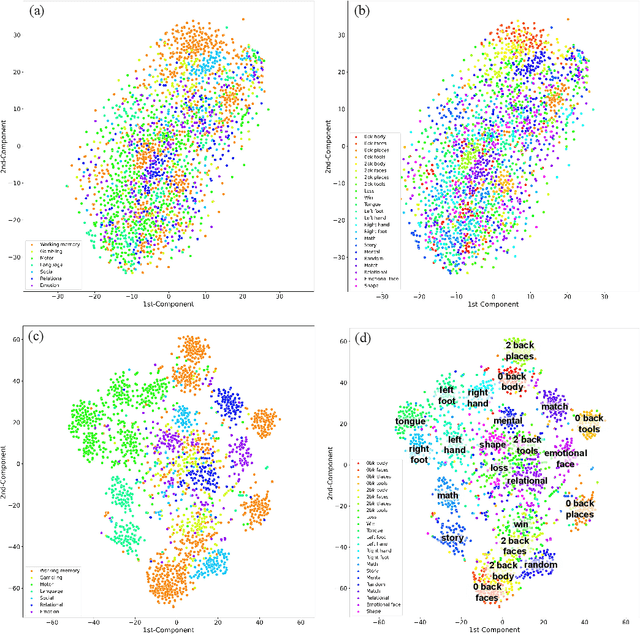

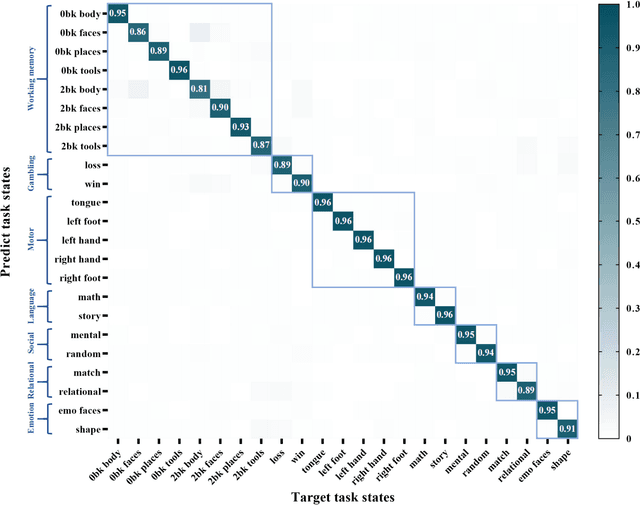
Brain decoding, aiming to identify the brain states using neural activity, is important for cognitive neuroscience and neural engineering. However, existing machine learning methods for fMRI-based brain decoding either suffer from low classification performance or poor explainability. Here, we address this issue by proposing a biologically inspired architecture, Spatial Temporal-pyramid Graph Convolutional Network (STpGCN), to capture the spatial-temporal graph representation of functional brain activities. By designing multi-scale spatial-temporal pathways and bottom-up pathways that mimic the information process and temporal integration in the brain, STpGCN is capable of explicitly utilizing the multi-scale temporal dependency of brain activities via graph, thereby achieving high brain decoding performance. Additionally, we propose a sensitivity analysis method called BrainNetX to better explain the decoding results by automatically annotating task-related brain regions from the brain-network standpoint. We conduct extensive experiments on fMRI data under 23 cognitive tasks from Human Connectome Project (HCP) S1200. The results show that STpGCN significantly improves brain decoding performance compared to competing baseline models; BrainNetX successfully annotates task-relevant brain regions. Post hoc analysis based on these regions further validates that the hierarchical structure in STpGCN significantly contributes to the explainability, robustness and generalization of the model. Our methods not only provide insights into information representation in the brain under multiple cognitive tasks but also indicate a bright future for fMRI-based brain decoding.
Partial Least Square Regression via Three-factor SVD-type Manifold Optimization for EEG Decoding
Aug 15, 2022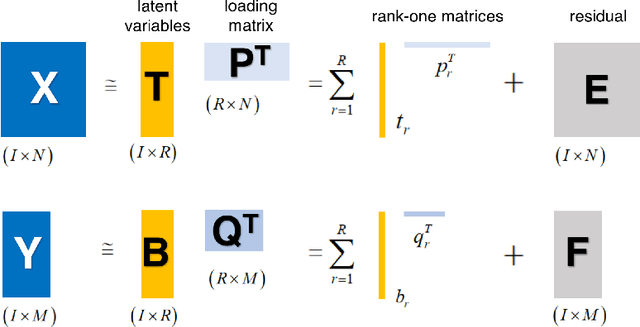
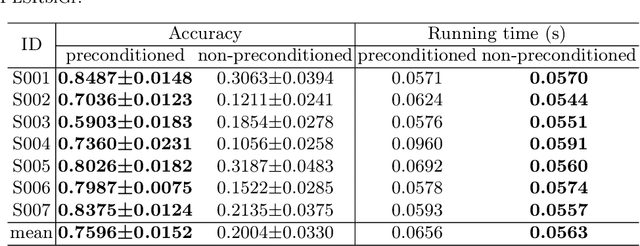
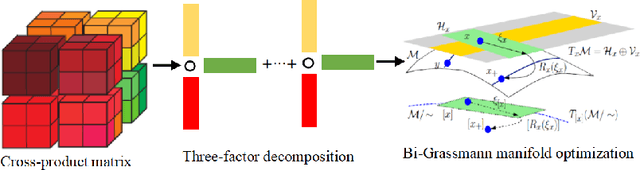
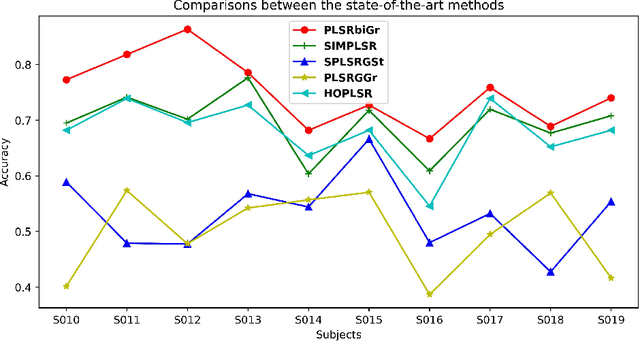
Partial least square regression (PLSR) is a widely-used statistical model to reveal the linear relationships of latent factors that comes from the independent variables and dependent variables. However, traditional methods to solve PLSR models are usually based on the Euclidean space, and easily getting stuck into a local minimum. To this end, we propose a new method to solve the partial least square regression, named PLSR via optimization on bi-Grassmann manifold (PLSRbiGr). Specifically, we first leverage the three-factor SVD-type decomposition of the cross-covariance matrix defined on the bi-Grassmann manifold, converting the orthogonal constrained optimization problem into an unconstrained optimization problem on bi-Grassmann manifold, and then incorporate the Riemannian preconditioning of matrix scaling to regulate the Riemannian metric in each iteration. PLSRbiGr is validated with a variety of experiments for decoding EEG signals at motor imagery (MI) and steady-state visual evoked potential (SSVEP) task. Experimental results demonstrate that PLSRbiGr outperforms competing algorithms in multiple EEG decoding tasks, which will greatly facilitate small sample data learning.