 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Free Training of Neural ODEs on Paired Data
Oct 30, 2024In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.
Learning to Compose: Improving Object Centric Learning by Injecting Compositionality
May 01, 2024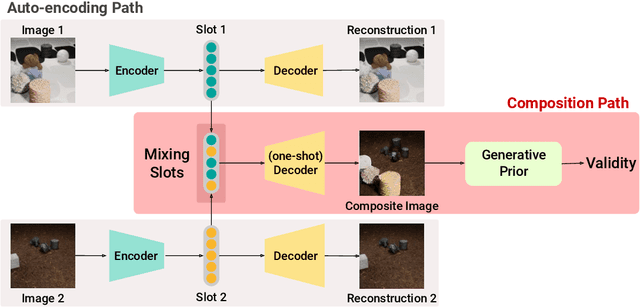
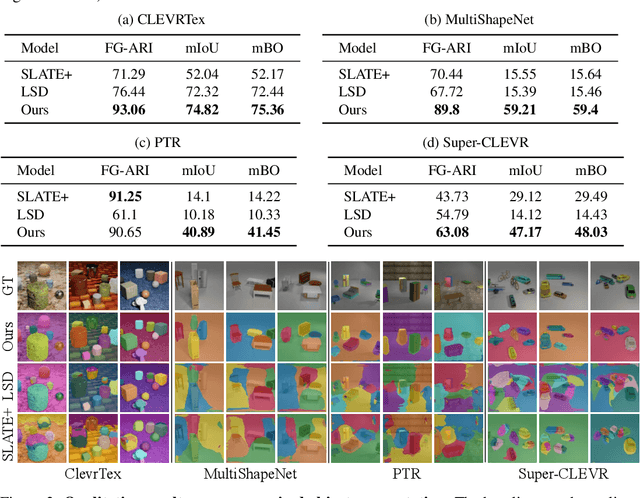
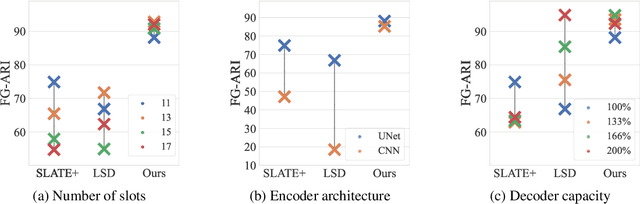
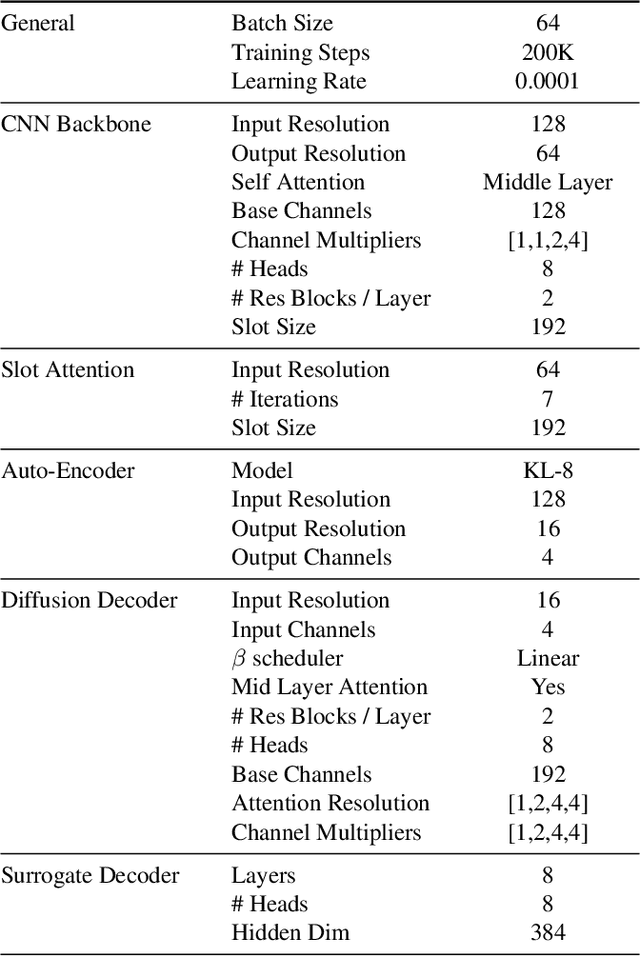
Learning compositional representation is a key aspect of object-centric learning as it enables flexible systematic generalization and supports complex visual reasoning. However, most of the existing approaches rely on auto-encoding objective, while the compositionality is implicitly imposed by the architectural or algorithmic bias in the encoder. This misalignment between auto-encoding objective and learning compositionality often results in failure of capturing meaningful object representations. In this study, we propose a novel objective that explicitly encourages compositionality of the representations. Built upon the existing object-centric learning framework (e.g., slot attention), our method incorporates additional constraints that an arbitrary mixture of object representations from two images should be valid by maximizing the likelihood of the composite data. We demonstrate that incorporating our objective to the existing framework consistently improves the objective-centric learning and enhances the robustness to the architectural choices.
Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
Mar 27, 2023Autoregressive transformers have shown remarkable success in video generation. However, the transformers are prohibited from directly learning the long-term dependency in videos due to the quadratic complexity of self-attention, and inherently suffering from slow inference time and error propagation due to the autoregressive process. In this paper, we propose Memory-efficient Bidirectional Transformer (MeBT) for end-to-end learning of long-term dependency in videos and fast inference. Based on recent advances in bidirectional transformers, our method learns to decode the entire spatio-temporal volume of a video in parallel from partially observed patches. The proposed transformer achieves a linear time complexity in both encoding and decoding, by projecting observable context tokens into a fixed number of latent tokens and conditioning them to decode the masked tokens through the cross-attention. Empowered by linear complexity and bidirectional modeling, our method demonstrates significant improvement over the autoregressive Transformers for generating moderately long videos in both quality and speed. Videos and code are available at https://sites.google.com/view/mebt-cvpr2023 .
SetVAE: Learning Hierarchical Composition for Generative Modeling of Set-Structured Data
Mar 29, 2021
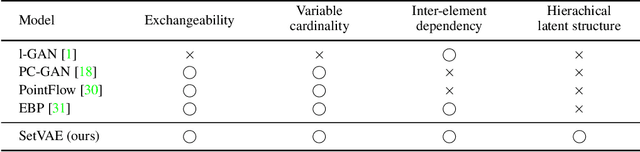
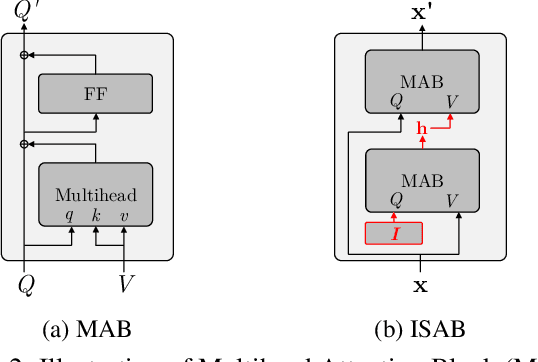

Generative modeling of set-structured data, such as point clouds, requires reasoning over local and global structures at various scales. However, adopting multi-scale frameworks for ordinary sequential data to a set-structured data is nontrivial as it should be invariant to the permutation of its elements. In this paper, we propose SetVAE, a hierarchical variational autoencoder for sets. Motivated by recent progress in set encoding, we build SetVAE upon attentive modules that first partition the set and project the partition back to the original cardinality. Exploiting this module, our hierarchical VAE learns latent variables at multiple scales, capturing coarse-to-fine dependency of the set elements while achieving permutation invariance. We evaluate our model on point cloud generation task and achieve competitive performance to the prior arts with substantially smaller model capacity. We qualitatively demonstrate that our model generalizes to unseen set sizes and learns interesting subset relations without supervision. Our implementation is available at https://github.com/jw9730/setvae.