 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Wireless LLM Inference via Uncertainty and Importance-Aware Speculative Decoding
Aug 18, 2025To address the growing demand for on-device LLM inference in resource-constrained environments, hybrid language models (HLM) have emerged, combining lightweight local models with powerful cloud-based LLMs. Recent studies on HLM have primarily focused on improving accuracy and latency, while often overlooking communication and energy efficiency. We propose a token-level filtering mechanism for an energy-efficient importance- and uncertainty-aware HLM inference that leverages both epistemic uncertainty and attention-based importance. Our method opportunistically uploads only informative tokens, reducing LLM usage and communication costs. Experiments with TinyLlama-1.1B and LLaMA-2-7B demonstrate that our method achieves up to 87.5% BERT Score and token throughput of 0.37 tokens/sec while saving the energy consumption by 40.7% compared to standard HLM. Furthermore, compared to our previous U-HLM baseline, our method improves BERTScore from 85.8% to 87.0%, energy savings from 31.6% to 43.6%, and throughput from 0.36 to 0.40. This approach enables an energy-efficient and accurate deployment of LLMs in bandwidth-constrained edge environments.
COMPASS: A Compiler Framework for Resource-Constrained Crossbar-Array Based In-Memory Deep Learning Accelerators
Jan 12, 2025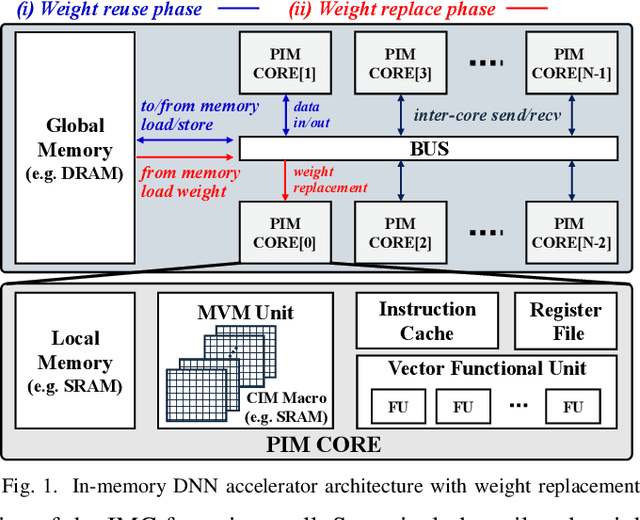
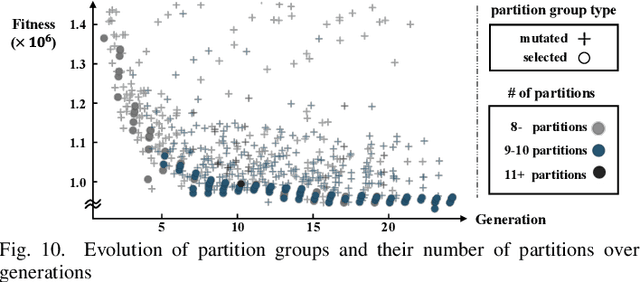
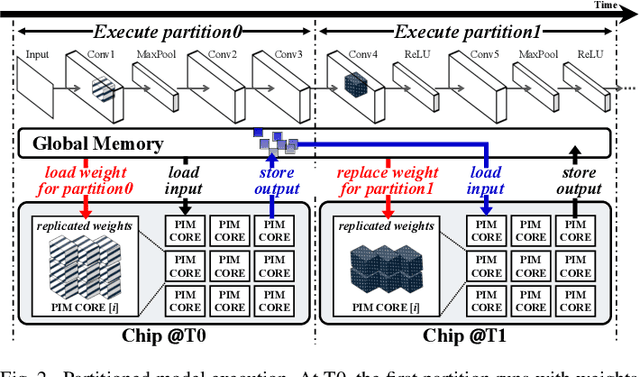
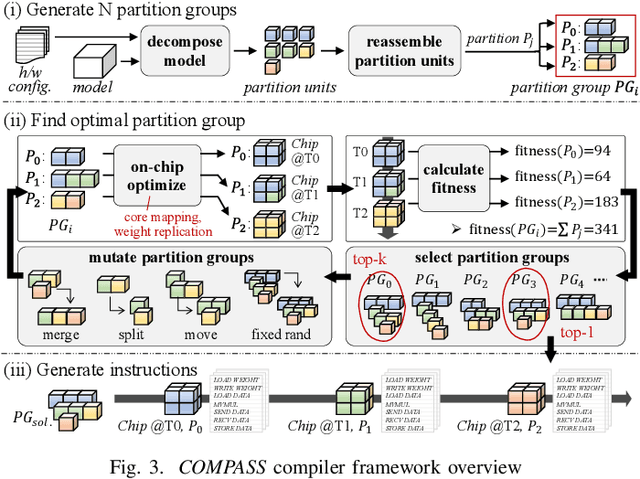
Recently, crossbar array based in-memory accelerators have been gaining interest due to their high throughput and energy efficiency. While software and compiler support for the in-memory accelerators has also been introduced, they are currently limited to the case where all weights are assumed to be on-chip. This limitation becomes apparent with the significantly increasing network sizes compared to the in-memory footprint. Weight replacement schemes are essential to address this issue. We propose COMPASS, a compiler framework for resource-constrained crossbar-based processing-in-memory (PIM) deep neural network (DNN) accelerators. COMPASS is specially targeted for networks that exceed the capacity of PIM crossbar arrays, necessitating access to external memories. We propose an algorithm to determine the optimal partitioning that divides the layers so that each partition can be accelerated on chip. Our scheme takes into account the data dependence between layers, core utilization, and the number of write instructions to minimize latency, memory accesses, and improve energy efficiency. Simulation results demonstrate that COMPASS can accommodate much more networks using a minimal memory footprint, while improving throughput by 1.78X and providing 1.28X savings in energy-delay product (EDP) over baseline partitioning methods.
DiffSLT: Enhancing Diversity in Sign Language Translation via Diffusion Model
Nov 26, 2024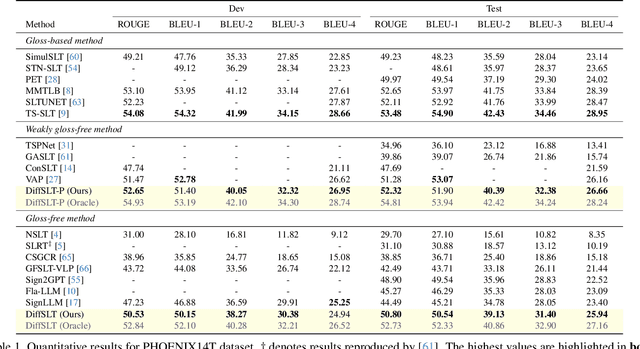


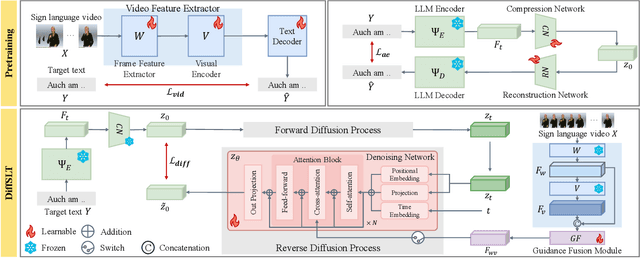
Sign language translation (SLT) is challenging, as it involves converting sign language videos into natural language. Previous studies have prioritized accuracy over diversity. However, diversity is crucial for handling lexical and syntactic ambiguities in machine translation, suggesting it could similarly benefit SLT. In this work, we propose DiffSLT, a novel gloss-free SLT framework that leverages a diffusion model, enabling diverse translations while preserving sign language semantics. DiffSLT transforms random noise into the target latent representation, conditioned on the visual features of input video. To enhance visual conditioning, we design Guidance Fusion Module, which fully utilizes the multi-level spatiotemporal information of the visual features. We also introduce DiffSLT-P, a DiffSLT variant that conditions on pseudo-glosses and visual features, providing key textual guidance and reducing the modality gap. As a result, DiffSLT and DiffSLT-P significantly improve diversity over previous gloss-free SLT methods and achieve state-of-the-art performance on two SLT datasets, thereby markedly improving translation quality.
Oscillations enhance time-series prediction in reservoir computing with feedback
Jun 05, 2024Reservoir computing, a machine learning framework used for modeling the brain, can predict temporal data with little observations and minimal computational resources. However, it is difficult to accurately reproduce the long-term target time series because the reservoir system becomes unstable. This predictive capability is required for a wide variety of time-series processing, including predictions of motor timing and chaotic dynamical systems. This study proposes oscillation-driven reservoir computing (ODRC) with feedback, where oscillatory signals are fed into a reservoir network to stabilize the network activity and induce complex reservoir dynamics. The ODRC can reproduce long-term target time series more accurately than conventional reservoir computing methods in a motor timing and chaotic time-series prediction tasks. Furthermore, it generates a time series similar to the target in the unexperienced period, that is, it can learn the abstract generative rules from limited observations. Given these significant improvements made by the simple and computationally inexpensive implementation, the ODRC would serve as a practical model of various time series data. Moreover, we will discuss biological implications of the ODRC, considering it as a model of neural oscillations and their cerebellar processors.
Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis
Nov 20, 2023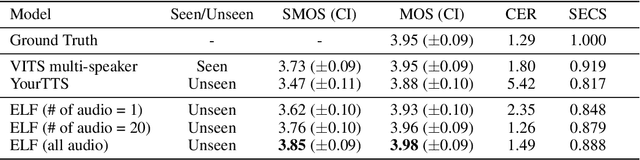
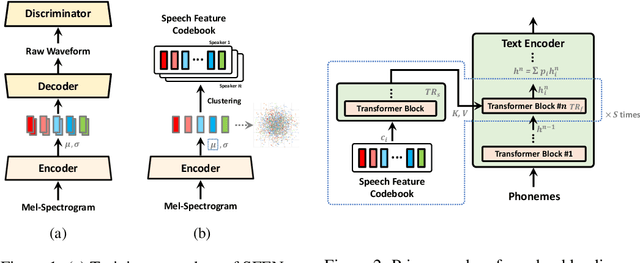
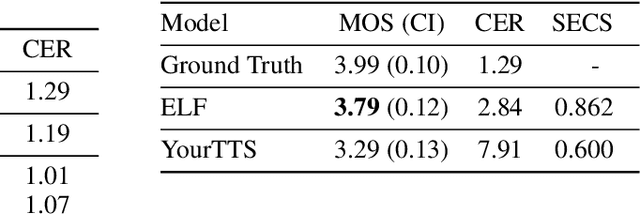
In this work, we propose a novel method for modeling numerous speakers, which enables expressing the overall characteristics of speakers in detail like a trained multi-speaker model without additional training on the target speaker's dataset. Although various works with similar purposes have been actively studied, their performance has not yet reached that of trained multi-speaker models due to their fundamental limitations. To overcome previous limitations, we propose effective methods for feature learning and representing target speakers' speech characteristics by discretizing the features and conditioning them to a speech synthesis model. Our method obtained a significantly higher similarity mean opinion score (SMOS) in subjective similarity evaluation than seen speakers of a best-performing multi-speaker model, even with unseen speakers. The proposed method also outperforms a zero-shot method by significant margins. Furthermore, our method shows remarkable performance in generating new artificial speakers. In addition, we demonstrate that the encoded latent features are sufficiently informative to reconstruct an original speaker's speech completely. It implies that our method can be used as a general methodology to encode and reconstruct speakers' characteristics in various tasks.
VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
Jul 31, 2023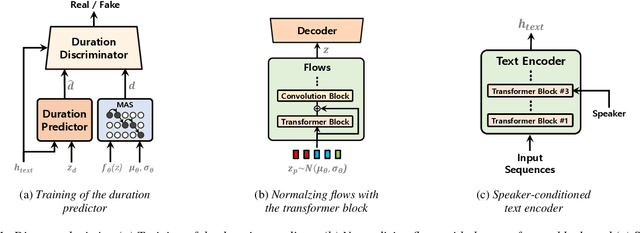


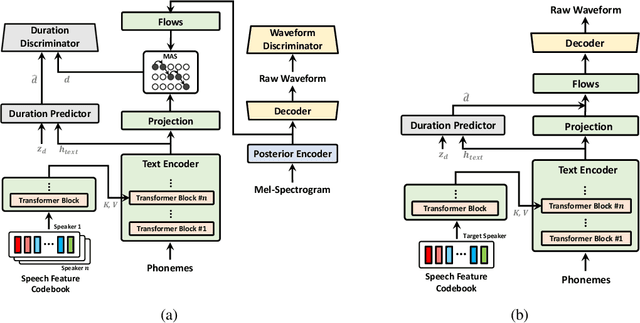
Single-stage text-to-speech models have been actively studied recently, and their results have outperformed two-stage pipeline systems. Although the previous single-stage model has made great progress, there is room for improvement in terms of its intermittent unnaturalness, computational efficiency, and strong dependence on phoneme conversion. In this work, we introduce VITS2, a single-stage text-to-speech model that efficiently synthesizes a more natural speech by improving several aspects of the previous work. We propose improved structures and training mechanisms and present that the proposed methods are effective in improving naturalness, similarity of speech characteristics in a multi-speaker model, and efficiency of training and inference. Furthermore, we demonstrate that the strong dependence on phoneme conversion in previous works can be significantly reduced with our method, which allows a fully end-to-end single-stage approach.
SplitAMC: Split Learning for Robust Automatic Modulation Classification
Apr 17, 2023Automatic modulation classification (AMC) is a technology that identifies a modulation scheme without prior signal information and plays a vital role in various applications, including cognitive radio and link adaptation. With the development of deep learning (DL), DL-based AMC methods have emerged, while most of them focus on reducing computational complexity in a centralized structure. This centralized learning-based AMC (CentAMC) violates data privacy in the aspect of direct transmission of client-side raw data. Federated learning-based AMC (FedeAMC) can bypass this issue by exchanging model parameters, but causes large resultant latency and client-side computational load. Moreover, both CentAMC and FedeAMC are vulnerable to large-scale noise occured in the wireless channel between the client and the server. To this end, we develop a novel AMC method based on a split learning (SL) framework, coined SplitAMC, that can achieve high accuracy even in poor channel conditions, while guaranteeing data privacy and low latency. In SplitAMC, each client can benefit from data privacy leakage by exchanging smashed data and its gradient instead of raw data, and has robustness to noise with the help of high scale of smashed data. Numerical evaluations validate that SplitAMC outperforms CentAMC and FedeAMC in terms of accuracy for all SNRs as well as latency.
Versions of Gradient Temporal Difference Learning
Sep 09, 2021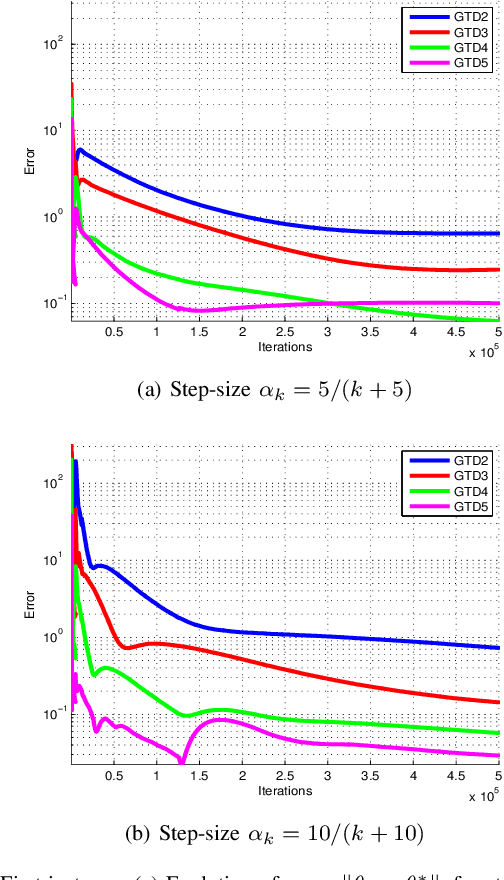


Sutton, Szepesv\'{a}ri and Maei introduced the first gradient temporal-difference (GTD) learning algorithms compatible with both linear function approximation and off-policy training. The goal of this paper is (a) to propose some variants of GTDs with extensive comparative analysis and (b) to establish new theoretical analysis frameworks for the GTDs. These variants are based on convex-concave saddle-point interpretations of GTDs, which effectively unify all the GTDs into a single framework, and provide simple stability analysis based on recent results on primal-dual gradient dynamics. Finally, numerical comparative analysis is given to evaluate these approaches.
Improving Accuracy of Binary Neural Networks using Unbalanced Activation Distribution
Dec 02, 2020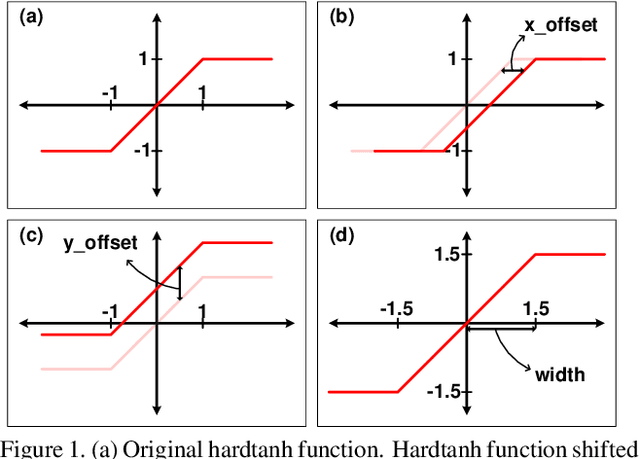
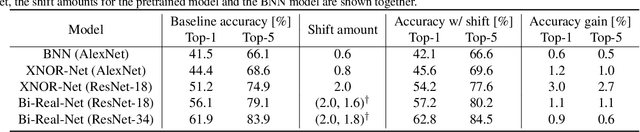
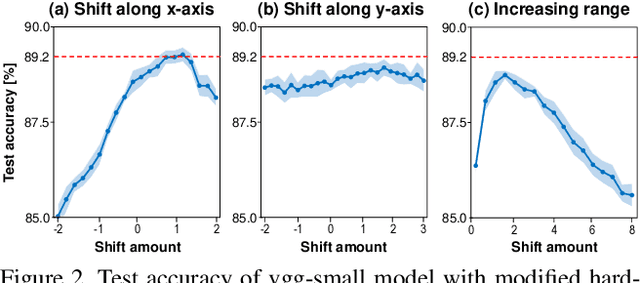
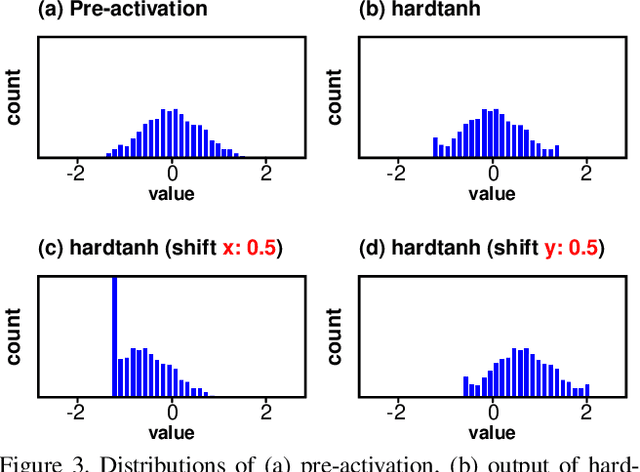
Binarization of neural network models is considered as one of the promising methods to deploy deep neural network models on resource-constrained environments such as mobile devices. However, Binary Neural Networks (BNNs) tend to suffer from severe accuracy degradation compared to the full-precision counterpart model. Several techniques were proposed to improve the accuracy of BNNs. One of the approaches is to balance the distribution of binary activations so that the amount of information in the binary activations becomes maximum. Based on extensive analysis, in stark contrast to previous work, we argue that unbalanced activation distribution can actually improve the accuracy of BNNs. We also show that adjusting the threshold values of binary activation functions results in the unbalanced distribution of the binary activation, which increases the accuracy of BNN models. Experimental results show that the accuracy of previous BNN models (e.g. XNOR-Net and Bi-Real-Net) can be improved by simply shifting the threshold values of binary activation functions without requiring any other modification.
Compensated Integrated Gradients to Reliably Interpret EEG Classification
Nov 21, 2018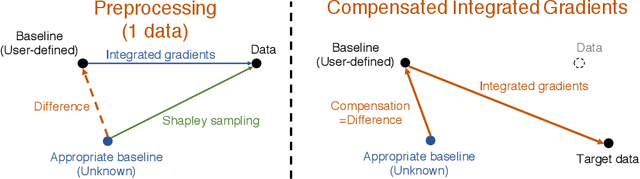
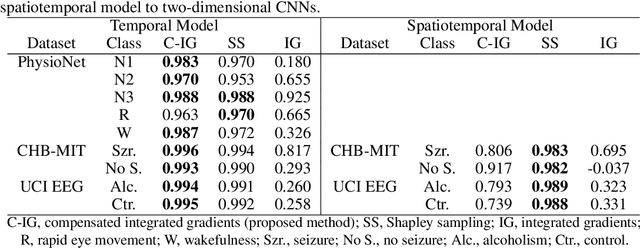
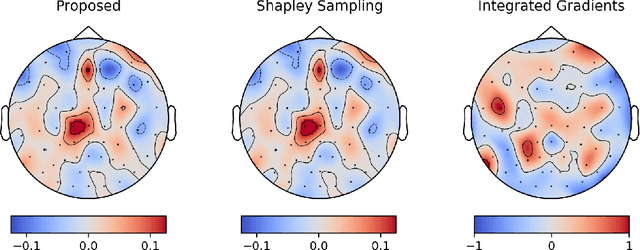
Integrated gradients are widely employed to evaluate the contribution of input features in classification models because it satisfies the axioms for attribution of prediction. This method, however, requires an appropriate baseline for reliable determination of the contributions. We propose a compensated integrated gradients method that does not require a baseline. In fact, the method compensates the attributions calculated by integrated gradients at an arbitrary baseline using Shapley sampling. We prove that the method retrieves reliable attributions if the processes of input features in a classifier are mutually independent, and they are identical like shared weights in convolutional neural networks. Using three electroencephalogram datasets, we experimentally demonstrate that the attributions of the proposed method are more reliable than those of the original integrated gradients, and its computational complexity is much lower than that of Shapley sampling.