 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Temporal Fusion Beyond the Field of View for Camera-based Semantic Scene Completion
Nov 16, 2025



Recent camera-based 3D semantic scene completion (SSC) methods have increasingly explored leveraging temporal cues to enrich the features of the current frame. However, while these approaches primarily focus on enhancing in-frame regions, they often struggle to reconstruct critical out-of-frame areas near the sides of the ego-vehicle, although previous frames commonly contain valuable contextual information about these unseen regions. To address this limitation, we propose the Current-Centric Contextual 3D Fusion (C3DFusion) module, which generates hidden region-aware 3D feature geometry by explicitly aligning 3D-lifted point features from both current and historical frames. C3DFusion performs enhanced temporal fusion through two complementary techniques-historical context blurring and current-centric feature densification-which suppress noise from inaccurately warped historical point features by attenuating their scale, and enhance current point features by increasing their volumetric contribution. Simply integrated into standard SSC architectures, C3DFusion demonstrates strong effectiveness, significantly outperforming state-of-the-art methods on the SemanticKITTI and SSCBench-KITTI-360 datasets. Furthermore, it exhibits robust generalization, achieving notable performance gains when applied to other baseline models.
MVFormer: Diversifying Feature Normalization and Token Mixing for Efficient Vision Transformers
Nov 28, 2024

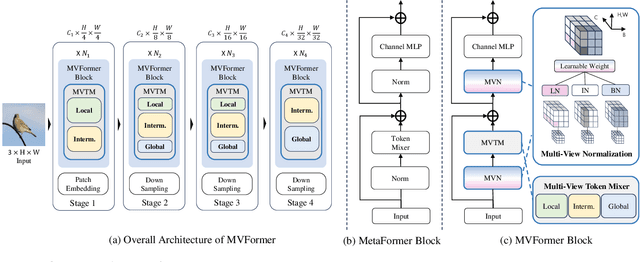
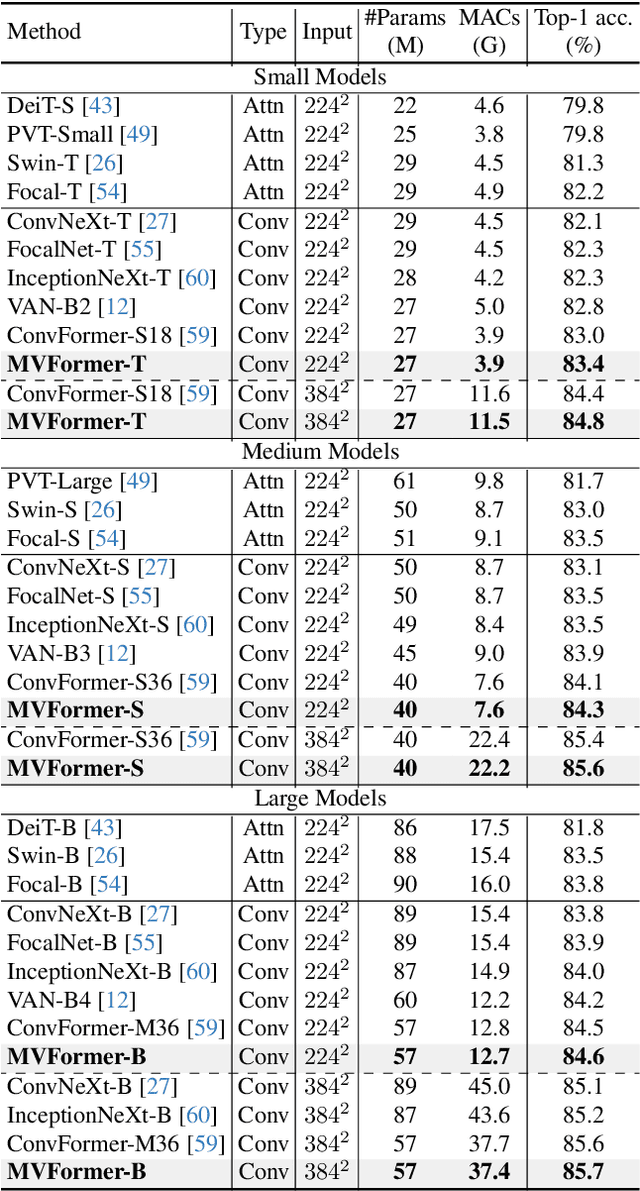
Active research is currently underway to enhance the efficiency of vision transformers (ViTs). Most studies have focused solely on effective token mixers, overlooking the potential relationship with normalization. To boost diverse feature learning, we propose two components: a normalization module called multi-view normalization (MVN) and a token mixer called multi-view token mixer (MVTM). The MVN integrates three differently normalized features via batch, layer, and instance normalization using a learnable weighted sum. Each normalization method outputs a different distribution, generating distinct features. Thus, the MVN is expected to offer diverse pattern information to the token mixer, resulting in beneficial synergy. The MVTM is a convolution-based multiscale token mixer with local, intermediate, and global filters, and it incorporates stage specificity by configuring various receptive fields for the token mixer at each stage, efficiently capturing ranges of visual patterns. We propose a novel ViT model, multi-vision transformer (MVFormer), adopting the MVN and MVTM in the MetaFormer block, the generalized ViT scheme. Our MVFormer outperforms state-of-the-art convolution-based ViTs on image classification, object detection, and instance and semantic segmentation with the same or lower parameters and MACs. Particularly, MVFormer variants, MVFormer-T, S, and B achieve 83.4%, 84.3%, and 84.6% top-1 accuracy, respectively, on ImageNet-1K benchmark.
DiffSLT: Enhancing Diversity in Sign Language Translation via Diffusion Model
Nov 26, 2024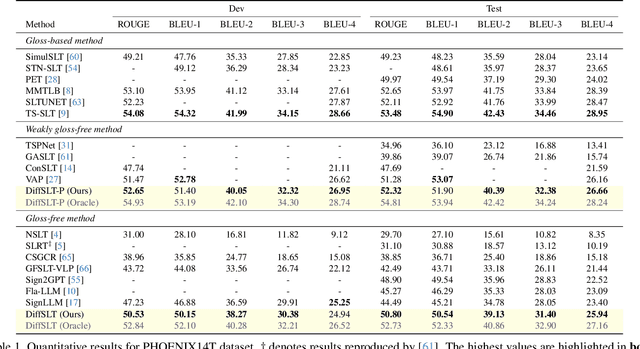


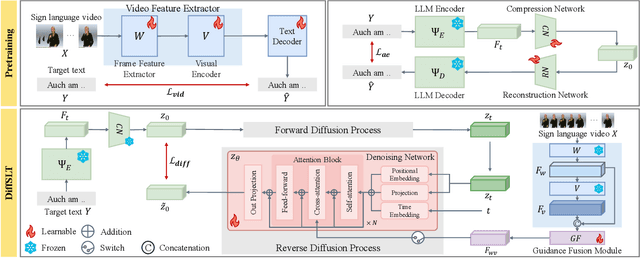
Sign language translation (SLT) is challenging, as it involves converting sign language videos into natural language. Previous studies have prioritized accuracy over diversity. However, diversity is crucial for handling lexical and syntactic ambiguities in machine translation, suggesting it could similarly benefit SLT. In this work, we propose DiffSLT, a novel gloss-free SLT framework that leverages a diffusion model, enabling diverse translations while preserving sign language semantics. DiffSLT transforms random noise into the target latent representation, conditioned on the visual features of input video. To enhance visual conditioning, we design Guidance Fusion Module, which fully utilizes the multi-level spatiotemporal information of the visual features. We also introduce DiffSLT-P, a DiffSLT variant that conditions on pseudo-glosses and visual features, providing key textual guidance and reducing the modality gap. As a result, DiffSLT and DiffSLT-P significantly improve diversity over previous gloss-free SLT methods and achieve state-of-the-art performance on two SLT datasets, thereby markedly improving translation quality.
Leveraging the Power of MLLMs for Gloss-Free Sign Language Translation
Nov 25, 2024Sign language translation (SLT) is a challenging task that involves translating sign language images into spoken language. For SLT models to perform this task successfully, they must bridge the modality gap and identify subtle variations in sign language components to understand their meanings accurately. To address these challenges, we propose a novel gloss-free SLT framework called Multimodal Sign Language Translation (MMSLT), which leverages the representational capabilities of off-the-shelf multimodal large language models (MLLMs). Specifically, we generate detailed textual descriptions of sign language components using MLLMs. Then, through our proposed multimodal-language pre-training module, we integrate these description features with sign video features to align them within the spoken sentence space. Our approach achieves state-of-the-art performance on benchmark datasets PHOENIX14T and CSL-Daily, highlighting the potential of MLLMs to be effectively utilized in SLT.
Three Cars Approaching within 100m! Enhancing Distant Geometry by Tri-Axis Voxel Scanning for Camera-based Semantic Scene Completion
Nov 25, 2024Camera-based Semantic Scene Completion (SSC) is gaining attentions in the 3D perception field. However, properties such as perspective and occlusion lead to the underestimation of the geometry in distant regions, posing a critical issue for safety-focused autonomous driving systems. To tackle this, we propose ScanSSC, a novel camera-based SSC model composed of a Scan Module and Scan Loss, both designed to enhance distant scenes by leveraging context from near-viewpoint scenes. The Scan Module uses axis-wise masked attention, where each axis employing a near-to-far cascade masking that enables distant voxels to capture relationships with preceding voxels. In addition, the Scan Loss computes the cross-entropy along each axis between cumulative logits and corresponding class distributions in a near-to-far direction, thereby propagating rich context-aware signals to distant voxels. Leveraging the synergy between these components, ScanSSC achieves state-of-the-art performance, with IoUs of 44.54 and 48.29, and mIoUs of 17.40 and 20.14 on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.
Decompose, Adjust, Compose: Effective Normalization by Playing with Frequency for Domain Generalization
Mar 15, 2023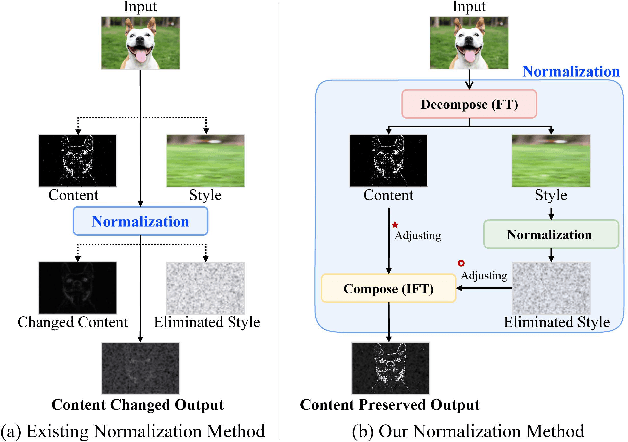



Domain generalization (DG) is a principal task to evaluate the robustness of computer vision models. Many previous studies have used normalization for DG. In normalization, statistics and normalized features are regarded as style and content, respectively. However, it has a content variation problem when removing style because the boundary between content and style is unclear. This study addresses this problem from the frequency domain perspective, where amplitude and phase are considered as style and content, respectively. First, we verify the quantitative phase variation of normalization through the mathematical derivation of the Fourier transform formula. Then, based on this, we propose a novel normalization method, PCNorm, which eliminates style only as the preserving content through spectral decomposition. Furthermore, we propose advanced PCNorm variants, CCNorm and SCNorm, which adjust the degrees of variations in content and style, respectively. Thus, they can learn domain-agnostic representations for DG. With the normalization methods, we propose ResNet-variant models, DAC-P and DAC-SC, which are robust to the domain gap. The proposed models outperform other recent DG methods. The DAC-SC achieves an average state-of-the-art performance of 65.6% on five datasets: PACS, VLCS, Office-Home, DomainNet, and TerraIncognita.