 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFormer: Diversifying Feature Normalization and Token Mixing for Efficient Vision Transformers
Paper and Code
Nov 28, 2024

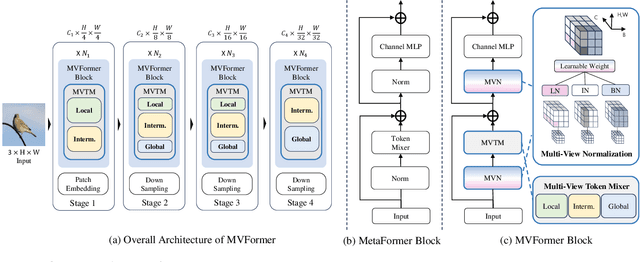
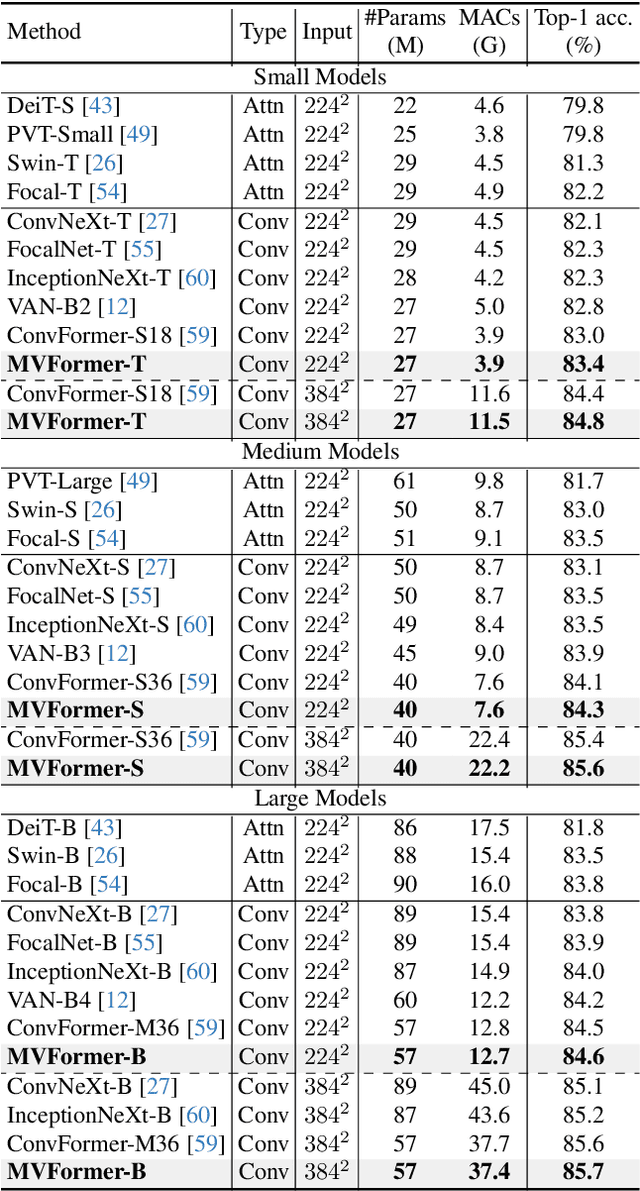
Active research is currently underway to enhance the efficiency of vision transformers (ViTs). Most studies have focused solely on effective token mixers, overlooking the potential relationship with normalization. To boost diverse feature learning, we propose two components: a normalization module called multi-view normalization (MVN) and a token mixer called multi-view token mixer (MVTM). The MVN integrates three differently normalized features via batch, layer, and instance normalization using a learnable weighted sum. Each normalization method outputs a different distribution, generating distinct features. Thus, the MVN is expected to offer diverse pattern information to the token mixer, resulting in beneficial synergy. The MVTM is a convolution-based multiscale token mixer with local, intermediate, and global filters, and it incorporates stage specificity by configuring various receptive fields for the token mixer at each stage, efficiently capturing ranges of visual patterns. We propose a novel ViT model, multi-vision transformer (MVFormer), adopting the MVN and MVTM in the MetaFormer block, the generalized ViT scheme. Our MVFormer outperforms state-of-the-art convolution-based ViTs on image classification, object detection, and instance and semantic segmentation with the same or lower parameters and MACs. Particularly, MVFormer variants, MVFormer-T, S, and B achieve 83.4%, 84.3%, and 84.6% top-1 accuracy, respectively, on ImageNet-1K benchmark.