 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoProtoNet: Interpretability for Prototypical Networks
Apr 02, 2022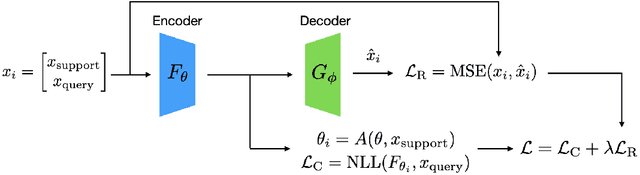
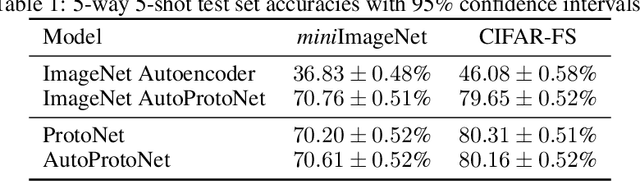

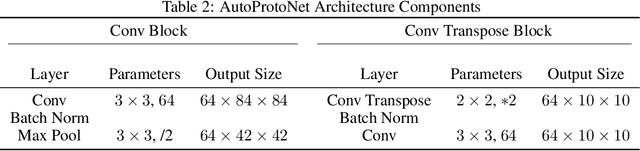
In meta-learning approaches, it is difficult for a practitioner to make sense of what kind of representations the model employs. Without this ability, it can be difficult to both understand what the model knows as well as to make meaningful corrections. To address these challenges, we introduce AutoProtoNet, which builds interpretability into Prototypical Networks by training an embedding space suitable for reconstructing inputs, while remaining convenient for few-shot learning. We demonstrate how points in this embedding space can be visualized and used to understand class representations. We also devise a prototype refinement method, which allows a human to debug inadequate classification parameters. We use this debugging technique on a custom classification task and find that it leads to accuracy improvements on a validation set consisting of in-the-wild images. We advocate for interpretability in meta-learning approaches and show that there are interactive ways for a human to enhance meta-learning algorithms.
SpikePropamine: Differentiable Plasticity in Spiking Neural Networks
Jun 04, 2021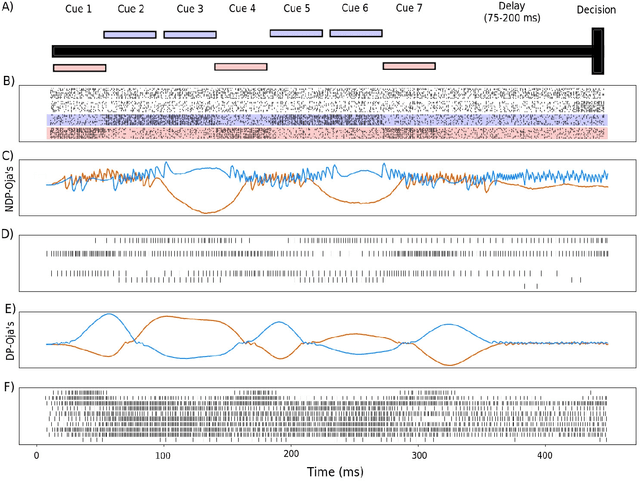
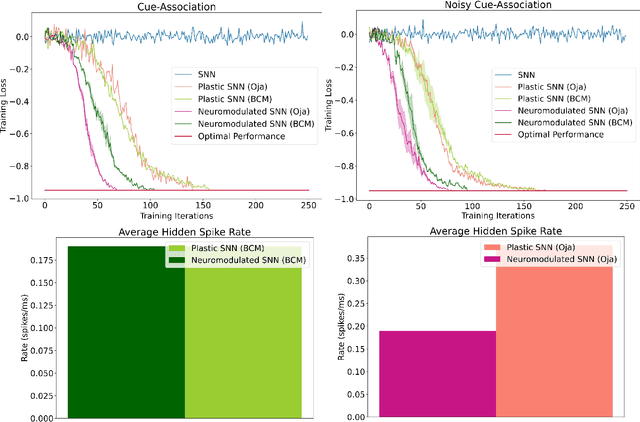
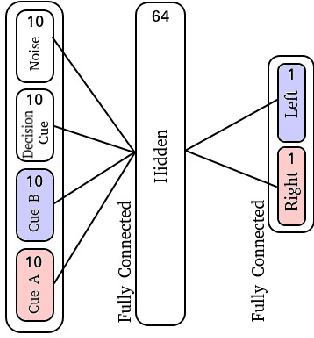
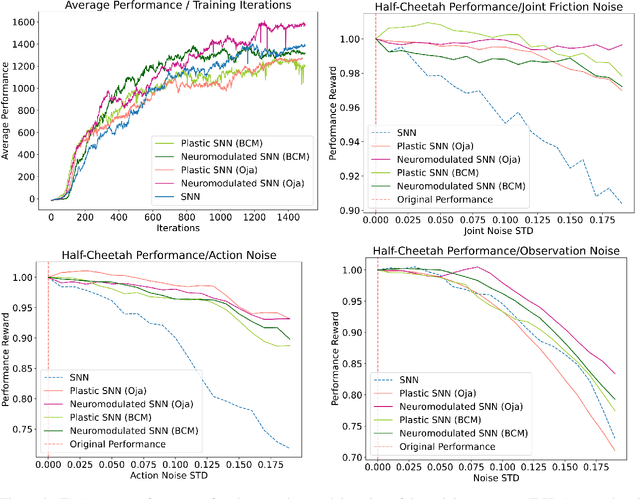
The adaptive changes in synaptic efficacy that occur between spiking neurons have been demonstrated to play a critical role in learning for biological neural networks. Despite this source of inspiration, many learning focused applications using Spiking Neural Networks (SNNs) retain static synaptic connections, preventing additional learning after the initial training period. Here, we introduce a framework for simultaneously learning the underlying fixed-weights and the rules governing the dynamics of synaptic plasticity and neuromodulated synaptic plasticity in SNNs through gradient descent. We further demonstrate the capabilities of this framework on a series of challenging benchmarks, learning the parameters of several plasticity rules including BCM, Oja's, and their respective set of neuromodulatory variants. The experimental results display that SNNs augmented with differentiable plasticity are sufficient for solving a set of challenging temporal learning tasks that a traditional SNN fails to solve, even in the presence of significant noise. These networks are also shown to be capable of producing locomotion on a high-dimensional robotic learning task, where near-minimal degradation in performance is observed in the presence of novel conditions not seen during the initial training period.
The Deeper, the Better: Analysis of Person Attributes Recognition
Jan 11, 2019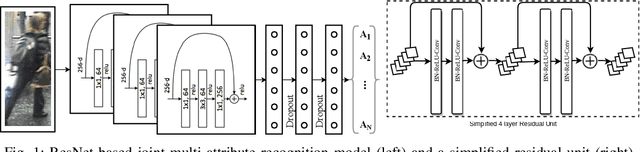
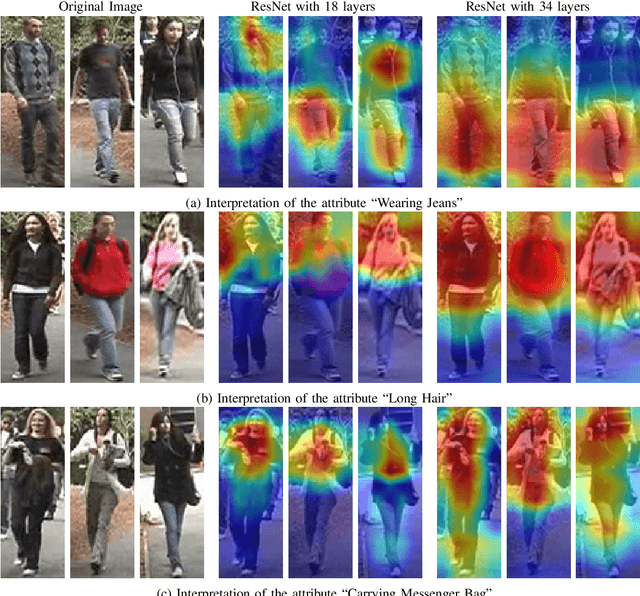

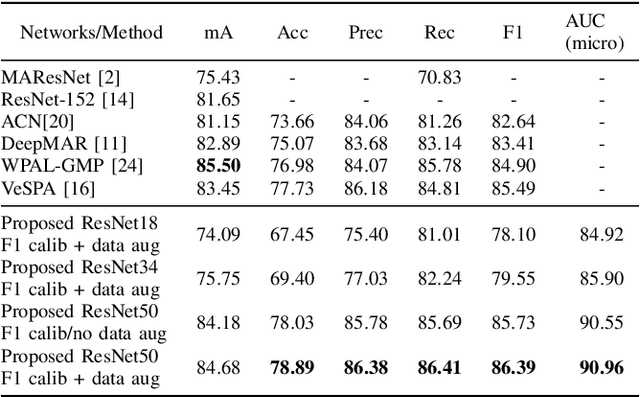
In person attributes recognition, we describe a person in terms of their appearance. Typically, this includes a wide range of traits including age, gender, clothing, and footwear. Although this could be used in a wide variety of scenarios, it generally is applied to video surveillance, where attribute recognition is impacted by low resolution, and other issues such as variable pose, occlusion and shadow. Recent approaches have used deep convolutional neural networks (CNNs) to improve the accuracy in person attribute recognition. However, many of these networks are relatively shallow and it is unclear to what extent they use contextual cues to improve classification accuracy. In this paper, we propose deeper methods for person attribute recognition. Interpreting the reasons behind the classification is highly important, as it can provide insight into how the classifier is making decisions. Interpretation suggests that deeper networks generally take more contextual information into consideration, which helps improve classification accuracy and generalizability. We present experimental analysis and results for whole body attributes using the PA-100K and PETA datasets and facial attributes using the CelebA dataset.