 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deeper, the Better: Analysis of Person Attributes Recognition
Paper and Code
Jan 11, 2019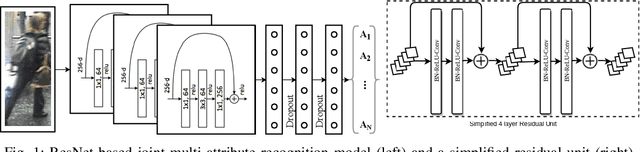
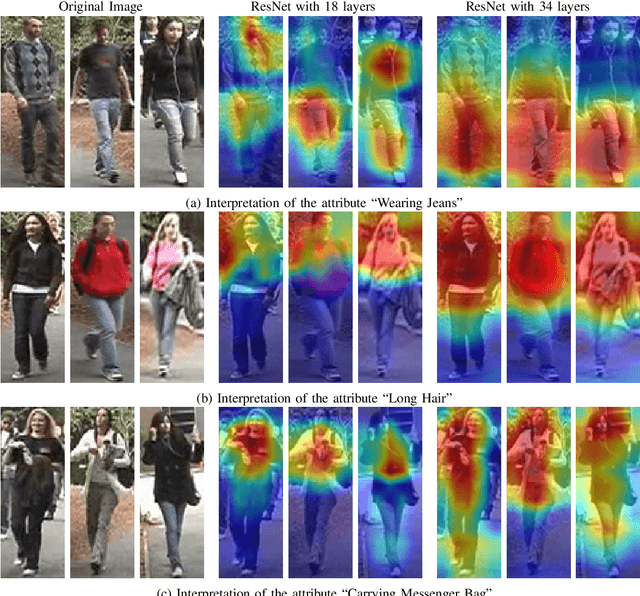

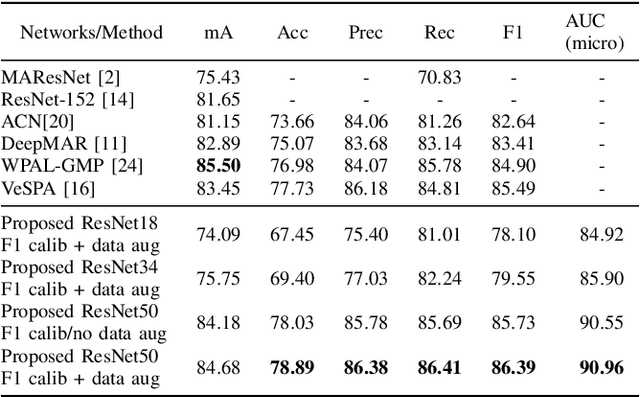
In person attributes recognition, we describe a person in terms of their appearance. Typically, this includes a wide range of traits including age, gender, clothing, and footwear. Although this could be used in a wide variety of scenarios, it generally is applied to video surveillance, where attribute recognition is impacted by low resolution, and other issues such as variable pose, occlusion and shadow. Recent approaches have used deep convolutional neural networks (CNNs) to improve the accuracy in person attribute recognition. However, many of these networks are relatively shallow and it is unclear to what extent they use contextual cues to improve classification accuracy. In this paper, we propose deeper methods for person attribute recognition. Interpreting the reasons behind the classification is highly important, as it can provide insight into how the classifier is making decisions. Interpretation suggests that deeper networks generally take more contextual information into consideration, which helps improve classification accuracy and generalizability. We present experimental analysis and results for whole body attributes using the PA-100K and PETA datasets and facial attributes using the CelebA dataset.