 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
Jul 09, 2025Conventional wisdom dictates that small batch sizes make language model pretraining and fine-tuning unstable, motivating gradient accumulation, which trades off the number of optimizer steps for a proportional increase in batch size. While it is common to decrease the learning rate for smaller batch sizes, other hyperparameters are often held fixed. In this work, we revisit small batch sizes all the way down to batch size one, and we propose a rule for scaling Adam hyperparameters to small batch sizes. We find that small batch sizes (1) train stably, (2) are consistently more robust to hyperparameter choices, (3) achieve equal or better per-FLOP performance than larger batch sizes, and (4) notably enable stable language model training with vanilla SGD, even without momentum, despite storing no optimizer state. Building on these results, we provide practical recommendations for selecting a batch size and setting optimizer hyperparameters. We further recommend against gradient accumulation unless training on multiple devices with multiple model replicas, bottlenecked by inter-device bandwidth.
Can a Confident Prior Replace a Cold Posterior?
Mar 02, 2024Benchmark datasets used for image classification tend to have very low levels of label noise. When Bayesian neural networks are trained on these datasets, they often underfit, misrepresenting the aleatoric uncertainty of the data. A common solution is to cool the posterior, which improves fit to the training data but is challenging to interpret from a Bayesian perspective. We explore whether posterior tempering can be replaced by a confidence-inducing prior distribution. First, we introduce a "DirClip" prior that is practical to sample and nearly matches the performance of a cold posterior. Second, we introduce a "confidence prior" that directly approximates a cold likelihood in the limit of decreasing temperature but cannot be easily sampled. Lastly, we provide several general insights into confidence-inducing priors, such as when they might diverge and how fine-tuning can mitigate numerical instability.
Image-Based Parking Space Occupancy Classification: Dataset and Baseline
Jul 26, 2021


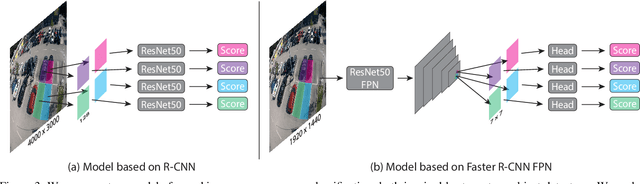
We introduce a new dataset for image-based parking space occupancy classification: ACPDS. Unlike in prior datasets, each image is taken from a unique view, systematically annotated, and the parking lots in the train, validation, and test sets are unique. We use this dataset to propose a simple baseline model for parking space occupancy classification, which achieves 98% accuracy on unseen parking lots, significantly outperforming existing models. We share our dataset, code, and trained models under the MIT license.