 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
Far from the Shallow: Brain-Predictive Reasoning Embedding through Residual Disentanglement
Oct 26, 2025Understanding how the human brain progresses from processing simple linguistic inputs to performing high-level reasoning is a fundamental challenge in neuroscience. While modern large language models (LLMs) are increasingly used to model neural responses to language, their internal representations are highly "entangled," mixing information about lexicon, syntax, meaning, and reasoning. This entanglement biases conventional brain encoding analyses toward linguistically shallow features (e.g., lexicon and syntax), making it difficult to isolate the neural substrates of cognitively deeper processes. Here, we introduce a residual disentanglement method that computationally isolates these components. By first probing an LM to identify feature-specific layers, our method iteratively regresses out lower-level representations to produce four nearly orthogonal embeddings for lexicon, syntax, meaning, and, critically, reasoning. We used these disentangled embeddings to model intracranial (ECoG) brain recordings from neurosurgical patients listening to natural speech. We show that: 1) This isolated reasoning embedding exhibits unique predictive power, accounting for variance in neural activity not explained by other linguistic features and even extending to the recruitment of visual regions beyond classical language areas. 2) The neural signature for reasoning is temporally distinct, peaking later (~350-400ms) than signals related to lexicon, syntax, and meaning, consistent with its position atop a processing hierarchy. 3) Standard, non-disentangled LLM embeddings can be misleading, as their predictive success is primarily attributable to linguistically shallow features, masking the more subtle contributions of deeper cognitive processing.
Contextual Feature Extraction Hierarchies Converge in Large Language Models and the Brain
Jan 31, 2024Recent advancements in artificial intelligence have sparked interest in the parallels between large language models (LLMs) and human neural processing, particularly in language comprehension. While prior research has established similarities in the representation of LLMs and the brain, the underlying computational principles that cause this convergence, especially in the context of evolving LLMs, remain elusive. Here, we examined a diverse selection of high-performance LLMs with similar parameter sizes to investigate the factors contributing to their alignment with the brain's language processing mechanisms. We find that as LLMs achieve higher performance on benchmark tasks, they not only become more brain-like as measured by higher performance when predicting neural responses from LLM embeddings, but also their hierarchical feature extraction pathways map more closely onto the brain's while using fewer layers to do the same encoding. We also compare the feature extraction pathways of the LLMs to each other and identify new ways in which high-performing models have converged toward similar hierarchical processing mechanisms. Finally, we show the importance of contextual information in improving model performance and brain similarity. Our findings reveal the converging aspects of language processing in the brain and LLMs and offer new directions for developing models that align more closely with human cognitive processing.
StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
Jun 13, 2023In this paper, we present StyleTTS 2, a text-to-speech (TTS) model that leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. StyleTTS 2 differs from its predecessor by modeling styles as a latent random variable through diffusion models to generate the most suitable style for the text without requiring reference speech, achieving efficient latent diffusion while benefiting from the diverse speech synthesis offered by diffusion models. Furthermore, we employ large pre-trained SLMs, such as WavLM, as discriminators with our novel differentiable duration modeling for end-to-end training, resulting in improved speech naturalness. StyleTTS 2 surpasses human recordings on the single-speaker LJSpeech dataset and matches it on the multispeaker VCTK dataset as judged by native English speakers. Moreover, when trained on the LibriTTS dataset, our model outperforms previous publicly available models for zero-shot speaker adaptation. This work achieves the first human-level TTS on both single and multispeaker datasets, showcasing the potential of style diffusion and adversarial training with large SLMs. The audio demos and source code are available at https://styletts2.github.io/.
mvlearn: Multiview Machine Learning in Python
May 25, 2020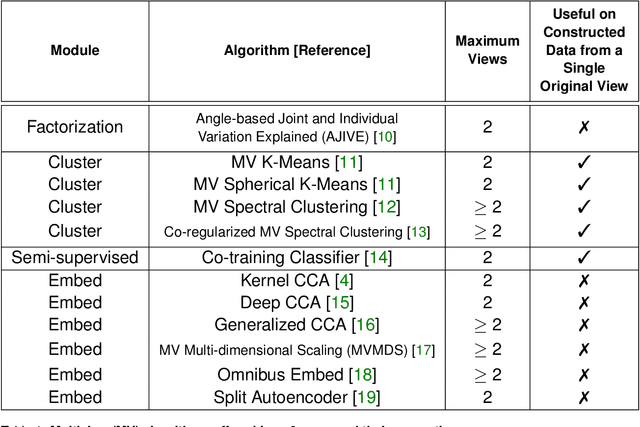
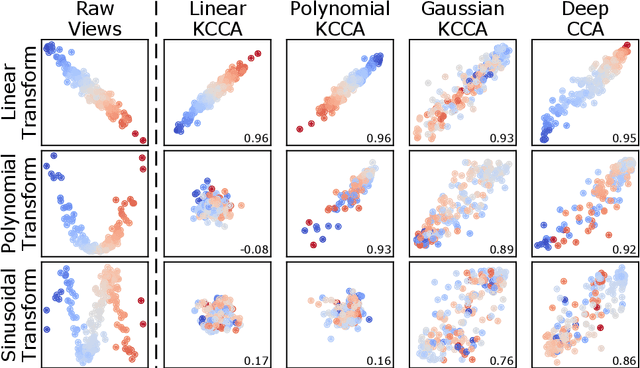

As data are generated more and more from multiple disparate sources, multiview datasets, where each sample has features in distinct views, have ballooned in recent years. However, no comprehensive package exists that enables non-specialists to use these methods easily. mvlearn, is a Python library which implements the leading multiview machine learning methods. Its simple API closely follows that of scikit-learn for increased ease-of-use. The package can be installed from Python Package Index (PyPI) or the conda package manager and is released under the Apache 2.0 open-source license. The documentation, detailed tutorials, and all releases are available at https://mvlearn.neurodata.io/.