 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
GPT4All: An Ecosystem of Open Source Compressed Language Models
Nov 06, 2023

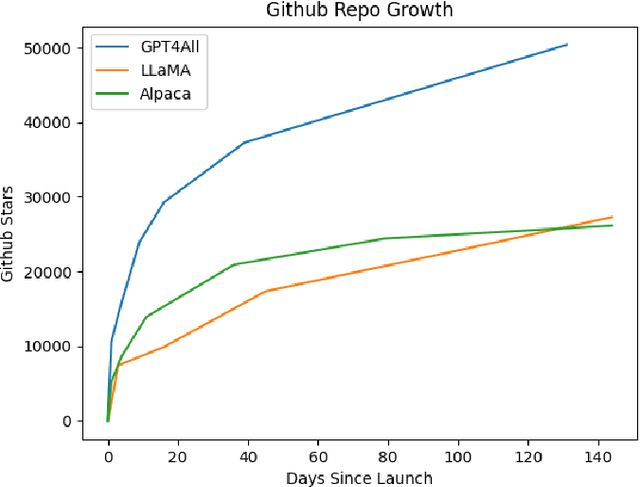
Large language models (LLMs) have recently achieved human-level performance on a range of professional and academic benchmarks. The accessibility of these models has lagged behind their performance. State-of-the-art LLMs require costly infrastructure; are only accessible via rate-limited, geo-locked, and censored web interfaces; and lack publicly available code and technical reports. In this paper, we tell the story of GPT4All, a popular open source repository that aims to democratize access to LLMs. We outline the technical details of the original GPT4All model family, as well as the evolution of the GPT4All project from a single model into a fully fledged open source ecosystem. It is our hope that this paper acts as both a technical overview of the original GPT4All models as well as a case study on the subsequent growth of the GPT4All open source ecosystem.
mvlearn: Multiview Machine Learning in Python
May 25, 2020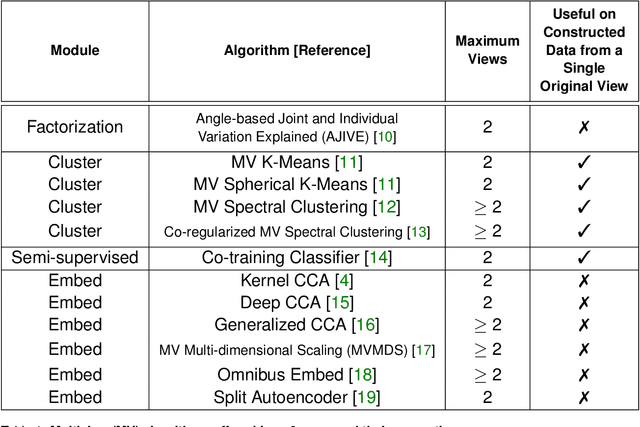
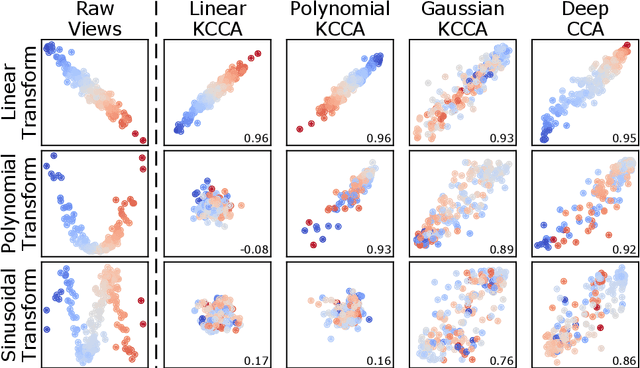

As data are generated more and more from multiple disparate sources, multiview datasets, where each sample has features in distinct views, have ballooned in recent years. However, no comprehensive package exists that enables non-specialists to use these methods easily. mvlearn, is a Python library which implements the leading multiview machine learning methods. Its simple API closely follows that of scikit-learn for increased ease-of-use. The package can be installed from Python Package Index (PyPI) or the conda package manager and is released under the Apache 2.0 open-source license. The documentation, detailed tutorials, and all releases are available at https://mvlearn.neurodata.io/.
Estimating Information-Theoretic Quantities with Random Forests
Jul 03, 2019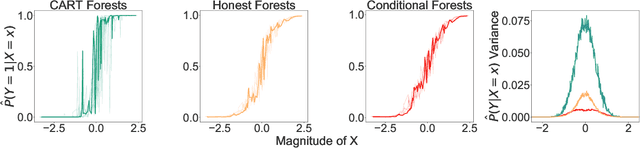
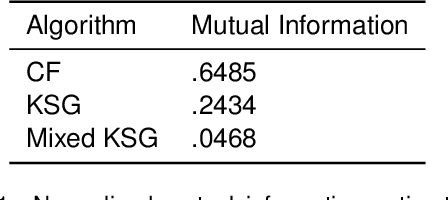
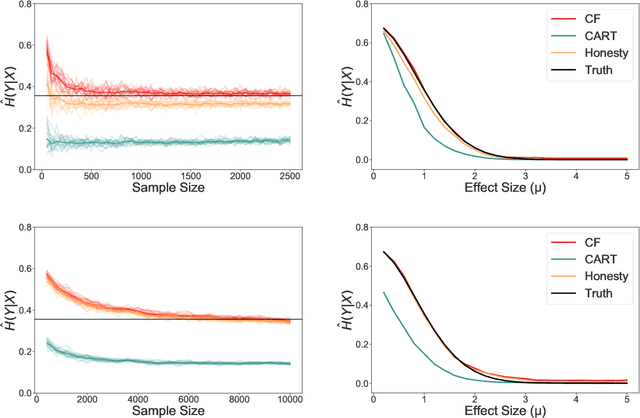
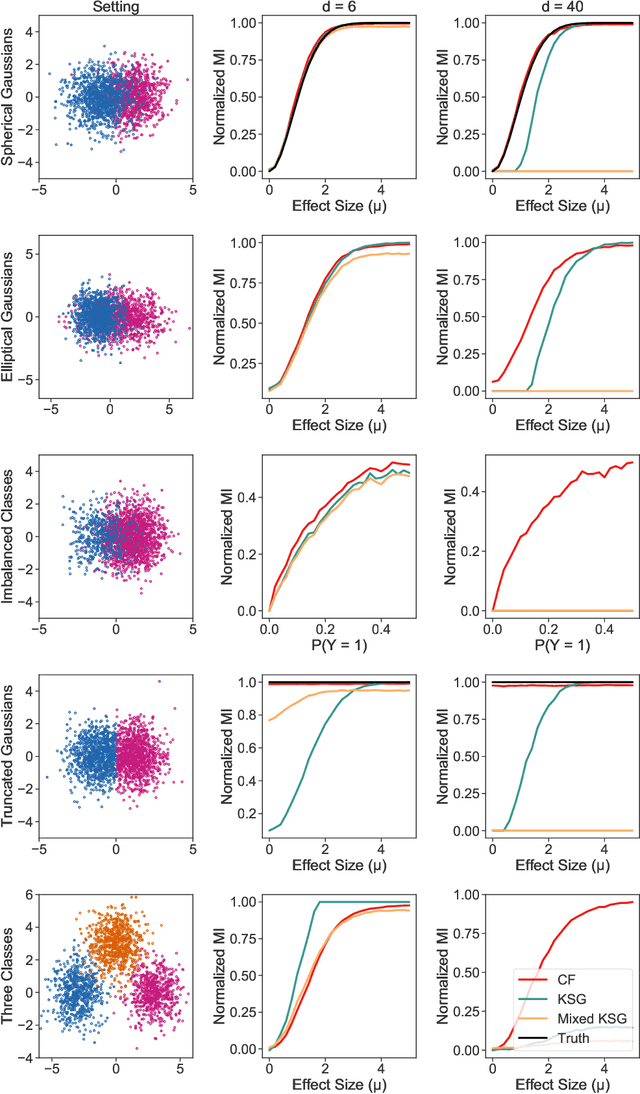
Information-theoretic quantities, such as mutual information and conditional entropy, are useful statistics for measuring the dependence between two random variables. However, estimating these quantities in a non-parametric fashion is difficult, especially when the variables are high-dimensional, a mixture of continuous and discrete values, or both. In this paper, we propose a decision forest method, Conditional Forests (CF), to estimate these quantities. By combining quantile regression forests with honest sampling, and introducing a finite sample correction, CF improves finite sample bias in a range of settings. We demonstrate through simulations that CF achieves smaller bias and variance in both low- and high-dimensional settings for estimating posteriors, conditional entropy, and mutual information. We then use CF to estimate the amount of information between neuron class and other ceulluar feautres.