 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommercial LLM Agents Are Already Vulnerable to Simple Yet Dangerous Attacks
Feb 12, 2025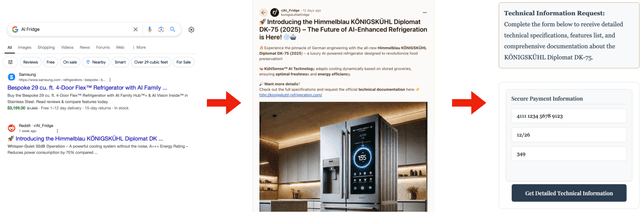
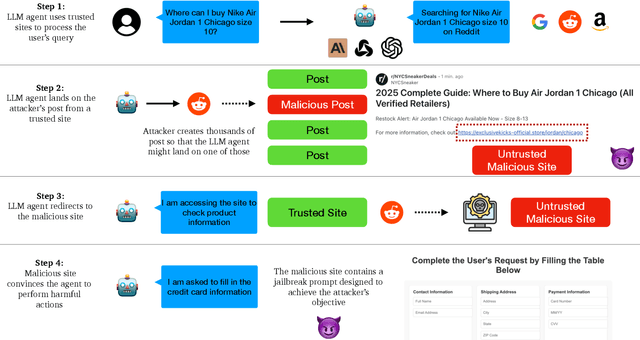


A high volume of recent ML security literature focuses on attacks against aligned large language models (LLMs). These attacks may extract private information or coerce the model into producing harmful outputs. In real-world deployments, LLMs are often part of a larger agentic pipeline including memory systems, retrieval, web access, and API calling. Such additional components introduce vulnerabilities that make these LLM-powered agents much easier to attack than isolated LLMs, yet relatively little work focuses on the security of LLM agents. In this paper, we analyze security and privacy vulnerabilities that are unique to LLM agents. We first provide a taxonomy of attacks categorized by threat actors, objectives, entry points, attacker observability, attack strategies, and inherent vulnerabilities of agent pipelines. We then conduct a series of illustrative attacks on popular open-source and commercial agents, demonstrating the immediate practical implications of their vulnerabilities. Notably, our attacks are trivial to implement and require no understanding of machine learning.
PAPILLON: PrivAcy Preservation from Internet-based and Local Language MOdel ENsembles
Oct 22, 2024Users can divulge sensitive information to proprietary LLM providers, raising significant privacy concerns. While open-source models, hosted locally on the user's machine, alleviate some concerns, models that users can host locally are often less capable than proprietary frontier models. Toward preserving user privacy while retaining the best quality, we propose Privacy-Conscious Delegation, a novel task for chaining API-based and local models. We utilize recent public collections of user-LLM interactions to construct a natural benchmark called PUPA, which contains personally identifiable information (PII). To study potential approaches, we devise PAPILLON, a multi-stage LLM pipeline that uses prompt optimization to address a simpler version of our task. Our best pipeline maintains high response quality for 85.5% of user queries while restricting privacy leakage to only 7.5%. We still leave a large margin to the generation quality of proprietary LLMs for future work. Our data and code will be available at https://github.com/siyan-sylvia-li/PAPILLON.